DeepSeek技术原理
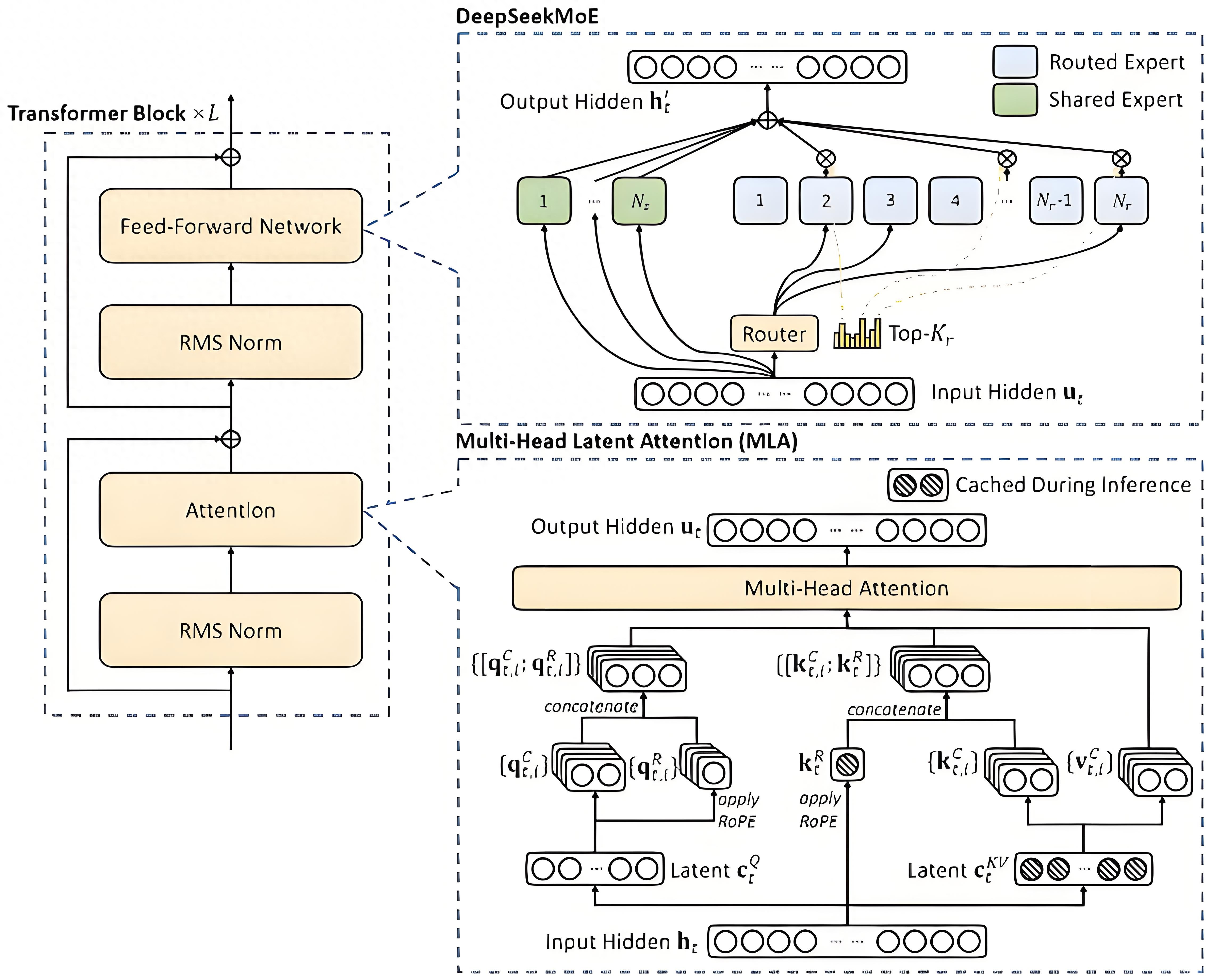
DeepSeek原理图
DeepSeek是由幻方量化创立的人工智能公司推出的一系列AI模型,包括DeepSeek Coder、DeepSeek LLM、DeepSeek-V2、DeepSeek-V3和DeepSeek-R1等。以下是对DeepSeek原理的通俗介绍:
核心架构方面
混合专家架构(MoE):MoE架构就像是一个有很多专家的团队。每个专家都擅长处理某一类特定的任务。当模型收到一个任务,比如回答一个问题或者处理一段文本时,它会把这个任务分配给最擅长处理该任务的专家去做,而不是让所有的模块都来处理。比如DeepSeek-V2有2360亿总参数,但处理每个token时,仅210亿参数被激活;DeepSeek -V3总参数达6710亿,但每个输入只激活370亿参数。这样一来,就大大减少了不必要的计算量,让模型处理复杂任务时又快又灵活。
基于Transformer架构:Transformer架构是DeepSeek的基础,它就像一个超级信息处理器,能处理各种顺序的信息,比如文字、语音等。它的核心是注意力机制,打个比方,我们在看一篇很长的文章时,会自动关注重要的部分,Transformer的注意力机制也能让模型在处理大量信息时,自动聚焦到关键内容上,理解信息之间的关系,不管这些信息是相隔很近还是很远。
关键技术方面
多头潜在注意力(MLA)机制:这是对传统注意力机制的升级。在处理像科研文献、长篇小说这样的长文本时,它能更精准地给句子、段落分配权重,找到文本的核心意思,不会像以前那样容易注意力分散。比如在机器翻译专业领域的长文档时,它能准确理解每个词在上下文中的意思,然后翻译成准确的目标语言。
无辅助损失负载均衡:在MoE架构中,不同的专家模块可能会出现有的忙不过来,有的却很空闲的情况。无辅助损失负载均衡策略就是来解决这个问题的,它能让各个专家模块的工作负担更均匀,不会出现有的累坏了,有的却没事干的情况,这样能让整个模型的性能更好。
多Token预测(MTP):传统模型一般是一个一个地预测token,而DeepSeek的多Token预测技术,可以一次预测多个token,就像我们说话时会连续说出几个词来表达一个意思,这样能让模型的推理速度更快,也能让生成的内容更连贯。
FP8混合精度训练:在训练模型时,数据的精度很重要。FP8混合精度训练就是一种新的训练方法,它能让模型在训练时用更合适的数据精度,既保证了训练的准确性,又能减少计算量,节省时间和成本,让大规模的模型训练变得更容易。
模型训练方面
知识蒸馏:简单来说,就是把一个大模型学到的知识,传递给一个小模型,就像老师把知识教给学生一样。比如DeepSeek-R1通过知识蒸馏,把长链推理模型的能力教给标准的LLM,让标准LLM的推理能力变得更强。
纯强化学习的尝试:以训练R1-Zero为例,它采用纯强化学习,让模型在试错中学习。比如在游戏场景里,模型尝试不同的操作,根据游戏给出的奖励或惩罚来知道自己做的对不对,慢慢找到最好的操作方法。虽然这种方式下模型输出有一些问题,像无休止重复、可读性差等,但也为模型训练提供了新方向。
多阶段训练和冷启动数据:DeepSeek-R1引入了多阶段训练和冷启动数据。多阶段训练就是在不同的阶段用不同的训练方法,就像我们学习时,小学、中学、大学的学习方法和重点都不一样。冷启动数据就是在模型开始学习前,给它一些高质量的数据,让它能更好地开始学习,就像我们在做一件事之前,先给一些提示和引导。
工作流程方面
输入处理与任务判断:当模型收到输入数据,比如用户的提问时,它会先对数据进行检查、清理和格式化等操作,就像我们拿到一个任务,会先看看是什么类型、难不难。然后通过MoE架构中的路由器机制,判断这个任务该交给哪个专家模块来处理。
调用合适模块进行数据处理:根据前面的判断结果,模型会调用相应的专家模块来处理数据。如果任务比较复杂,涉及多个领域,就会召集多个模块一起工作,它们之间还会互相传递信息,共同完成任务。
生成输出结果:相关模块处理完数据后,会把结果整合、优化,看看语句通不通顺、逻辑合不合理等。如果有问题,就会进行调整,直到得到一个满意的结果,再把这个结果返回给用户。