
AI大模型九大核心技术总览
一、核心技术(基础层)
这些技术是AI大模型得以构建和运行的基石,决定了模型的基础能力与扩展潜力。
1. Transformer架构
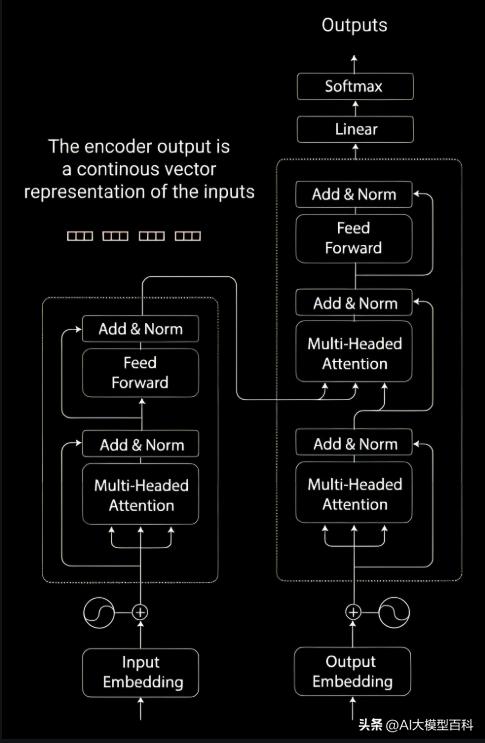
重要性:★★★★★
说明:
Transformer彻底取代了RNN和CNN在序列建模中的地位,其核心是自注意力机制(Self-Attention)和多头注意力(Multi-Head Attention),支持并行计算并有效捕捉长距离依赖关系。
- 位置编码:通过正弦/余弦函数注入位置信息,弥补了Transformer对序列顺序的敏感性。
- 编码器-解码器结构:编码器负责上下文表征,解码器生成目标序列,广泛应用于机器翻译、文本生成等任务。
优势:高并行性、全局依赖建模能力强。
2. 预训练方法
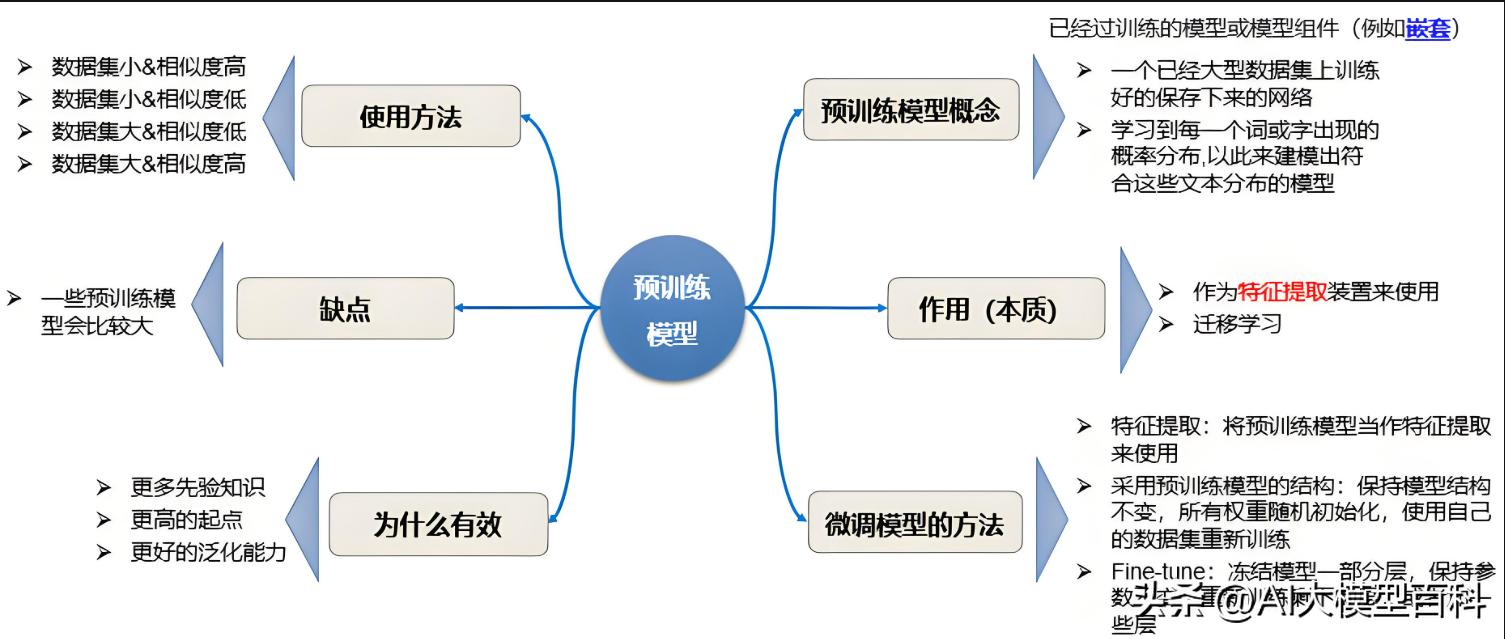
重要性:★★★★★
说明:
通过大规模无监督数据训练模型,学习通用表征,再通过微调适配具体任务。
- 掩码语言建模(MLM):BERT的核心方法,通过预测被掩盖的Token学习双向上下文。
- 自回归建模(Autoregressive):GPT系列采用从左到右的生成式预训练,擅长文本生成。
- 多模态预训练:如CLIP联合学习文本与图像表征,支持跨模态任务。
作用:提升模型泛化能力,减少下游任务训练成本。
3. 分布式训练与优化技术
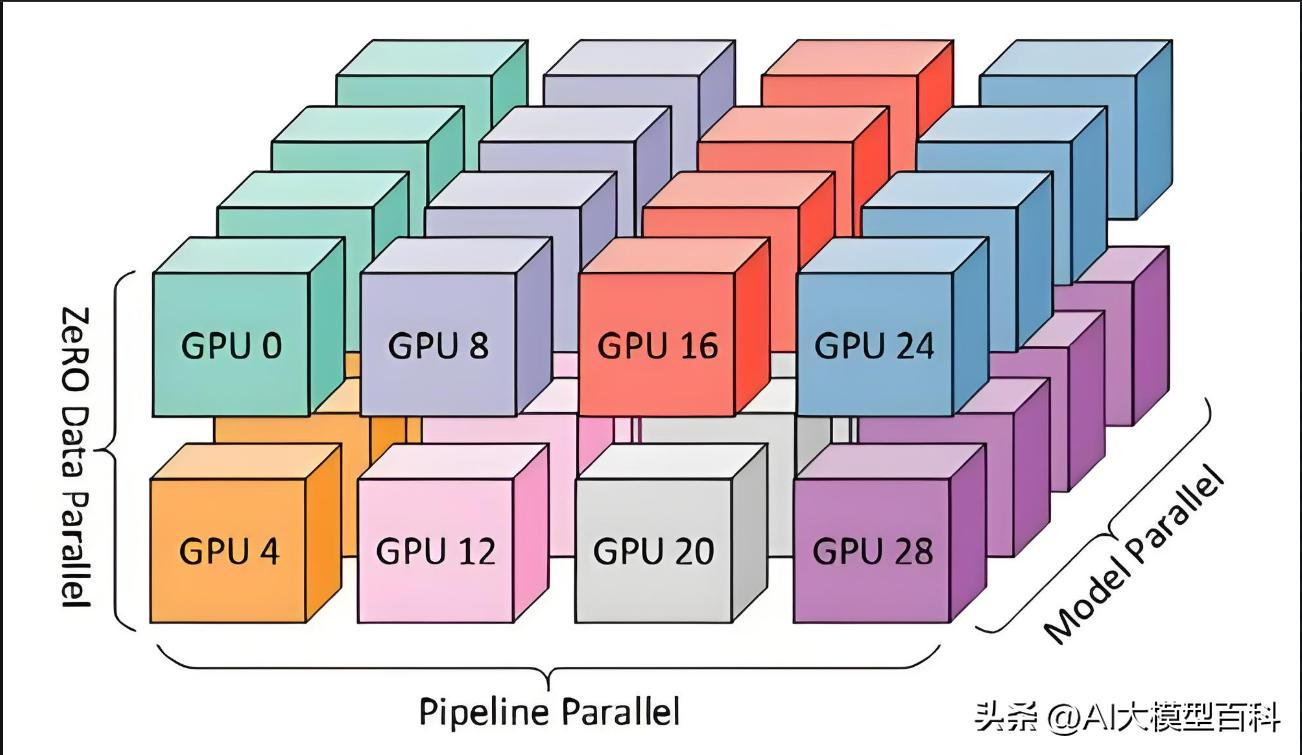
重要性:★★★★☆
说明:
支撑千亿参数模型的训练效率与稳定性。
数据并行与模型并行:分片数据或拆分模型参数到多设备,解决显存与计算瓶颈。
混合精度训练:使用FP16/FP8降低计算开销,结合梯度缩放避免数值溢出。
优化算法:AdamW、LAMB等自适应优化器,结合学习率预热(Warmup)提升收敛稳定性。
4. 缩放定律(Scaling Laws)
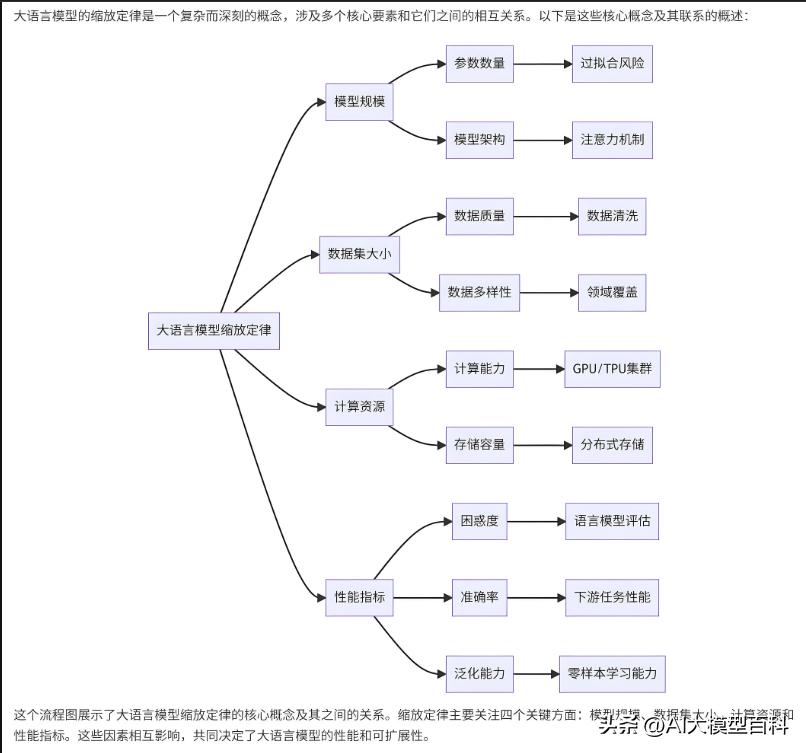
重要性:★★★☆☆
说明:
揭示模型性能与参数量、数据量、计算资源的指数级增长关系,指导模型规模的扩展策略。
- 核心发现:增加模型规模(参数、数据、训练时间)可显著提升性能,但边际收益递减。
- 应用:推动GPT-3、PaLM等万亿参数模型的研发。
二、关键扩展技术(应用层)
这些技术针对大模型的落地瓶颈(如效率、知识局限、交互能力)提供解决方案。
1. 模型压缩技术
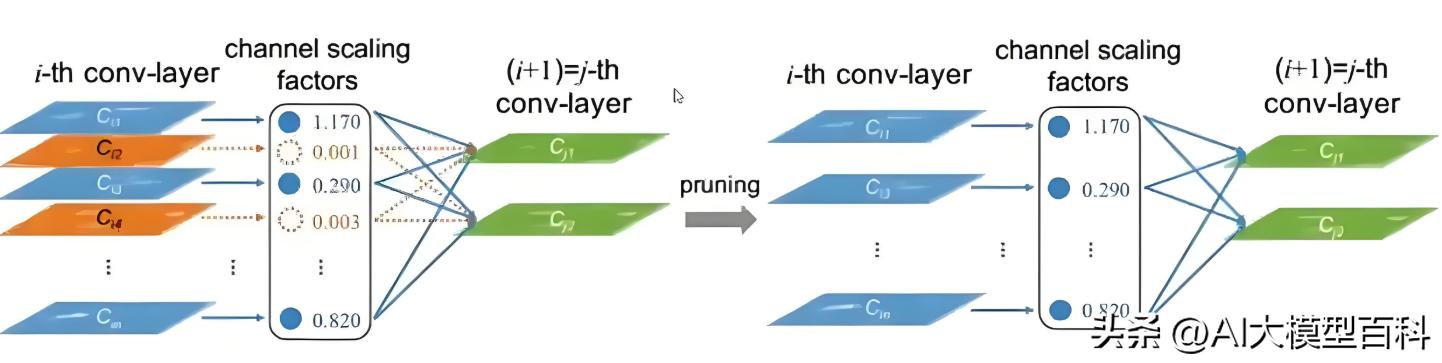
重要性:★★★★☆
说明:
解决大模型的高计算成本与部署难题。
- 知识蒸馏(Knowledge Distillation):将大模型(教师)的知识迁移至小模型(学生),如DistilBERT。
- 量化(Quantization):将参数从FP32转为INT8/INT4,减少存储与计算需求。
- 模型剪枝(Pruning):移除冗余参数,保留关键连接。
2. 知识库集成(RAG)
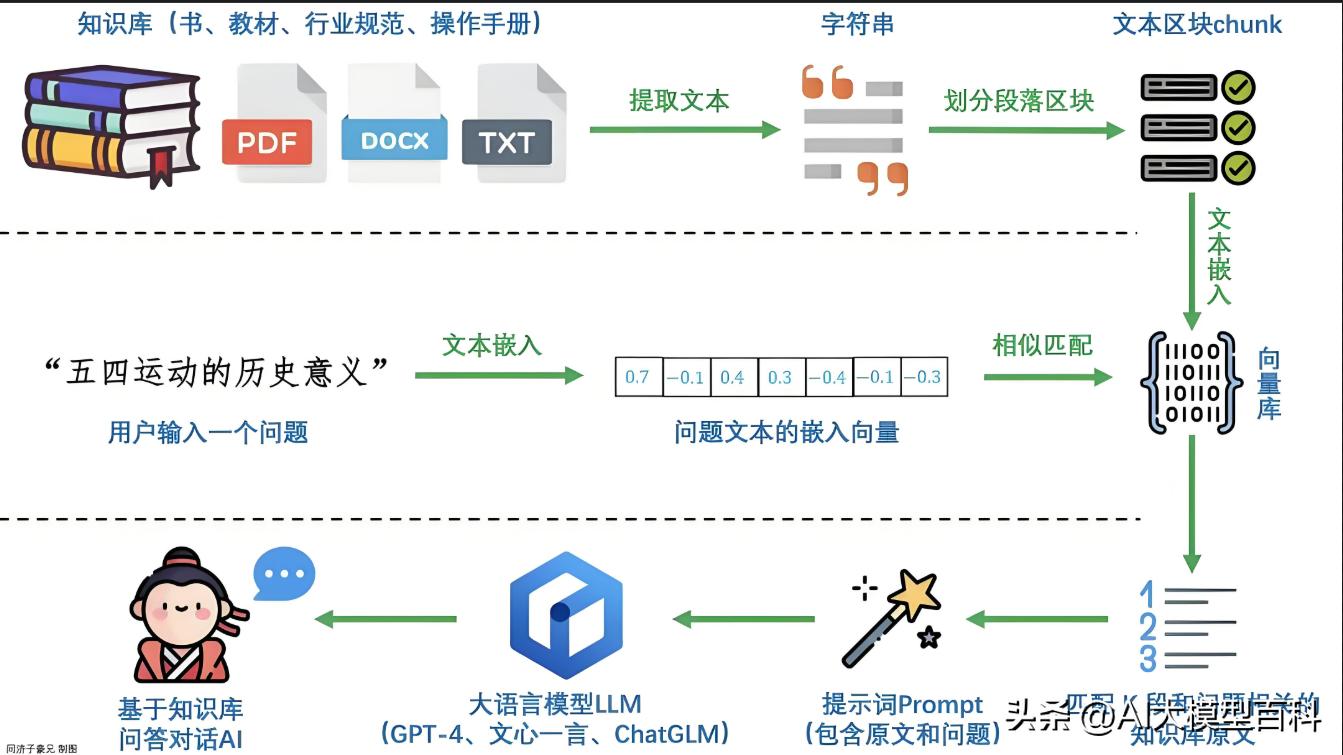
重要性:★★★☆☆
说明:
增强模型的事实性与时效性,减少“幻觉”问题。
- 检索增强生成(RAG):在生成时动态检索外部知识库(如维基百科),结合生成结果提升准确性。
- 知识图谱嵌入:如K-BERT在预训练阶段注入结构化知识。
3. 多模态融合
重要性:★★★☆☆
说明:
整合文本、图像、音频等多模态数据,提升模型感知能力。
- 跨模态对齐:如CLIP通过对比学习对齐文本与图像特征。
- 多任务学习:如Flamingo同时处理图像描述、视频问答等任务。
4. 人类反馈强化学习(RLHF)
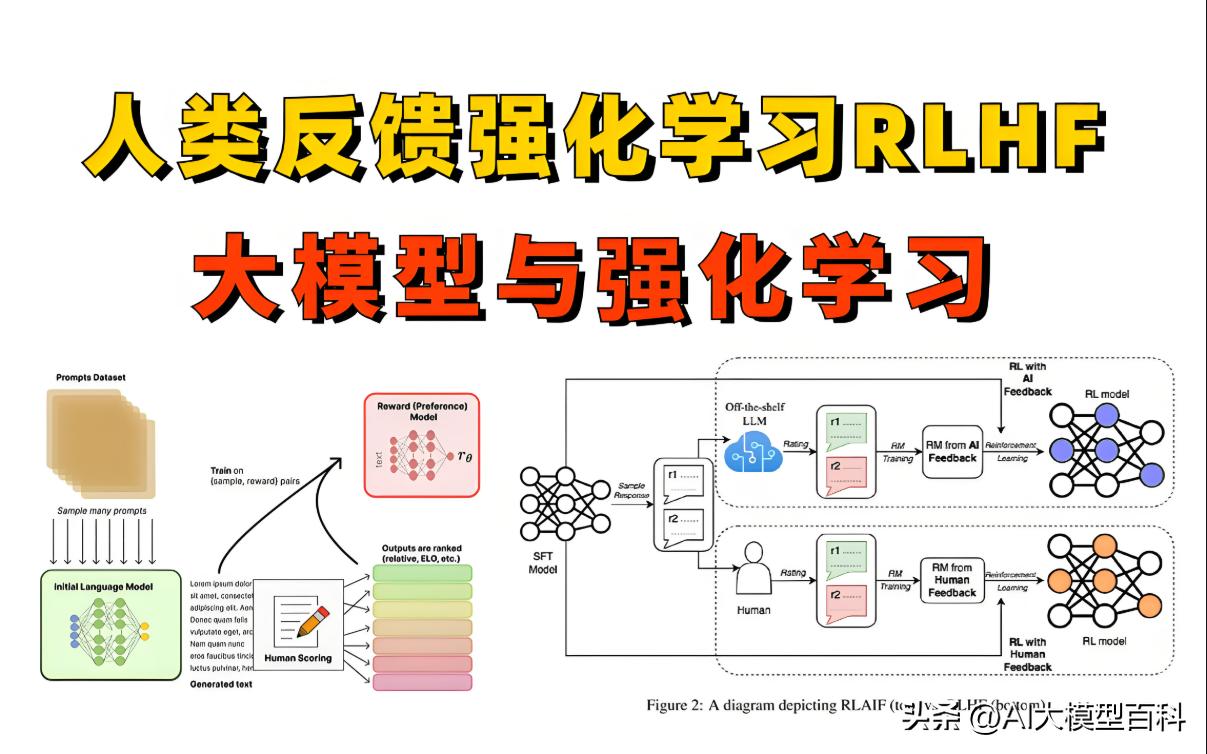
重要性:★★★☆☆
说明:
通过人类偏好数据微调模型,使其输出更符合价值观。
- 训练步骤:预训练→监督微调→奖励模型训练→近端策略优化(PPO)。
- 应用:ChatGPT通过RLHF优化对话安全性与有用性。
5. AI Agent(智能体)
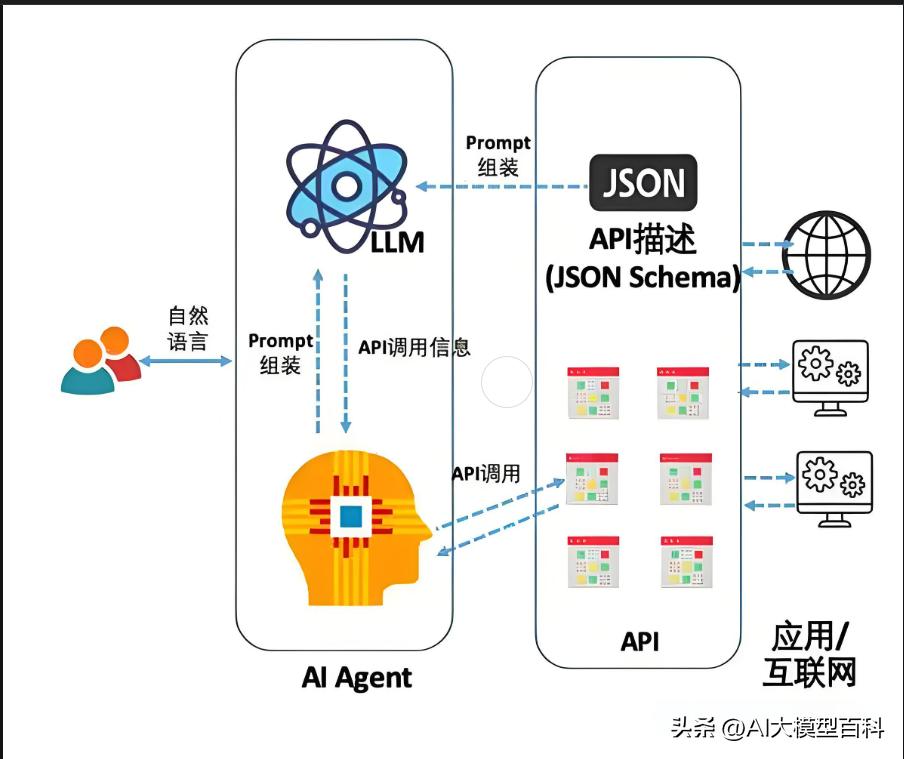
重要性:★★☆☆☆
说明:
赋予大模型自主决策与工具调用能力。
- 规划与推理:如Chain-of-Thought(CoT)分步推理,ReAct框架结合推理与行动。
- 工具集成:调用API、数据库或物理设备(如AutoGPT调用浏览器搜索)。
三、技术关联与未来趋势
1、核心与扩展技术的协同
2、预训练模型(如GPT-4)结合知识库(RAG)提升事实性。
3、模型压缩技术(蒸馏+量化)推动边缘端部署。
4、未来方向
5、通用智能体:融合多模态感知、规划与工具调用(如Meta的CICERO)。
6、绿色AI:通过稀疏化、低秩近似降低能耗。
总结
- 核心技术:构建模型的基础能力(Transformer、预训练、分布式训练)。
- 扩展技术:解决落地瓶颈(效率、知识局限、交互能力)。
- 核心引用:Transformer架构、预训练方法、模型压缩。
参考文献或转载相关:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 AI-X!

相关推荐




评论


