Python代码解析(1) - 磁盘空间信息表格输出
Linux磁盘空间信息表格输出
这是一个获取Linux下的磁盘空间信息的脚本,通过Linux下的df命令获取到全部的磁盘空间的使用情况,然后在去掉临时空间等行的信息,只保留物理硬盘的信息。
信息包括分区的文件系统类型、空间大小、已用大小、可用大小、已用百分比、挂载点。
整体有效代码连同注释共39行,除去主入口、注释行和空白行,实际有效代码仅20行而已。
运行的结果截图: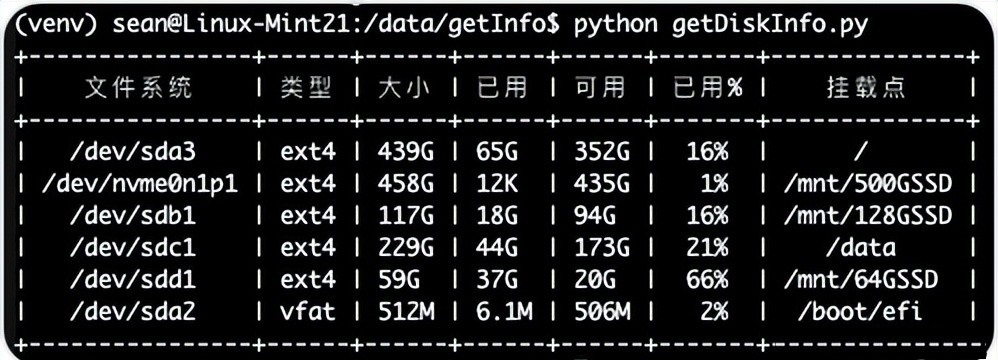
Python完整的代码
1 | import os |
代码解析
第1~2行代码
1 | import os |
这个脚本的使用到的库很少,只有两个,内置的os库和第三方的prettytable。prettytable需要安装才可以使用,否则脚本会报错。安装的命令pip install prettytable。
第38~39行代码
1 | if __name__ == '__main__': |
可以理解为运行这个文件时的主入口,在python中,文件独立运行时,它的魔法函数 name 会返回 main 而在该文件被其他文件引用调用的时候,则不是返回 main 。这个入口的意思就是,运行这个脚本文件的时候,就执行 systemInfo() 函数。函数在上面的第5~28行中已经定义了。
第7行代码
1 | disk_list = os.popen('df -hT|grep -vE "(tmpfs|overlay)"').readlines() |
代码里面的注释也已经解释得很清楚了,利用os库的popen()函数,直接在命令行里面执行df命令查看并且过滤掉临时文件系统(tmpfs)和docker的文件系统(overlay),然后赋值给变量名disk_list,为什么变量名有list,因为readlines()函数返回的就是一个list类型。df -hT命令后面的两个参数h是df命令输出的结果为符合人类阅读的格式,如xxxM、xxxG这样有M、G、T等计数单位的信息。比较方便阅读。grep -vE “(tmpfs|overlay)”‘参数v是表示这个过滤的结果为不显示的,E “(tmpfs|overlay)”参数是用正则搜索包含tmpfs或者overlay的行。包含着两个的行,都是不需要的,配合前面的参数v,就可以把包含这两种情况的行隐藏不显示。符合咱们只需要物理磁盘信息的需求。
第7行代码
1 | table = prettytable.PrettyTable() |
初始化一个表格并赋值给变量名table,这个表格用于美化后面的输出。
第13~22行代码
1 | title = disk_list[0].split(' ') |
这几行代码,主要的作用是把上面提及的df命令中获取到的信息取出来第一个元素里面的信息,这些信息是表头的内容,取出后需要用空格分割,在去掉内用的空格内容,还有去掉换行符,组成一个新的list,再将这个list赋值给表格的表头。
第25~34行代码
1 | for item in disk_list[1:]: |
和上面组合表头的代码类似,不过这行做的处理是处理第二个元素及以后的元素,一个元素为一行,同样是去空白和去换行符的处理,然后一个元素的内容处理为一个list,添加为表格的一行。
第36行代码
1 | print(table) |
将上面组合并美化为表格的内容输出到命令行。也就是最开始图片里面那样的输出结果。