
大语言模型优化技术之-RAG模型和HyDE模型
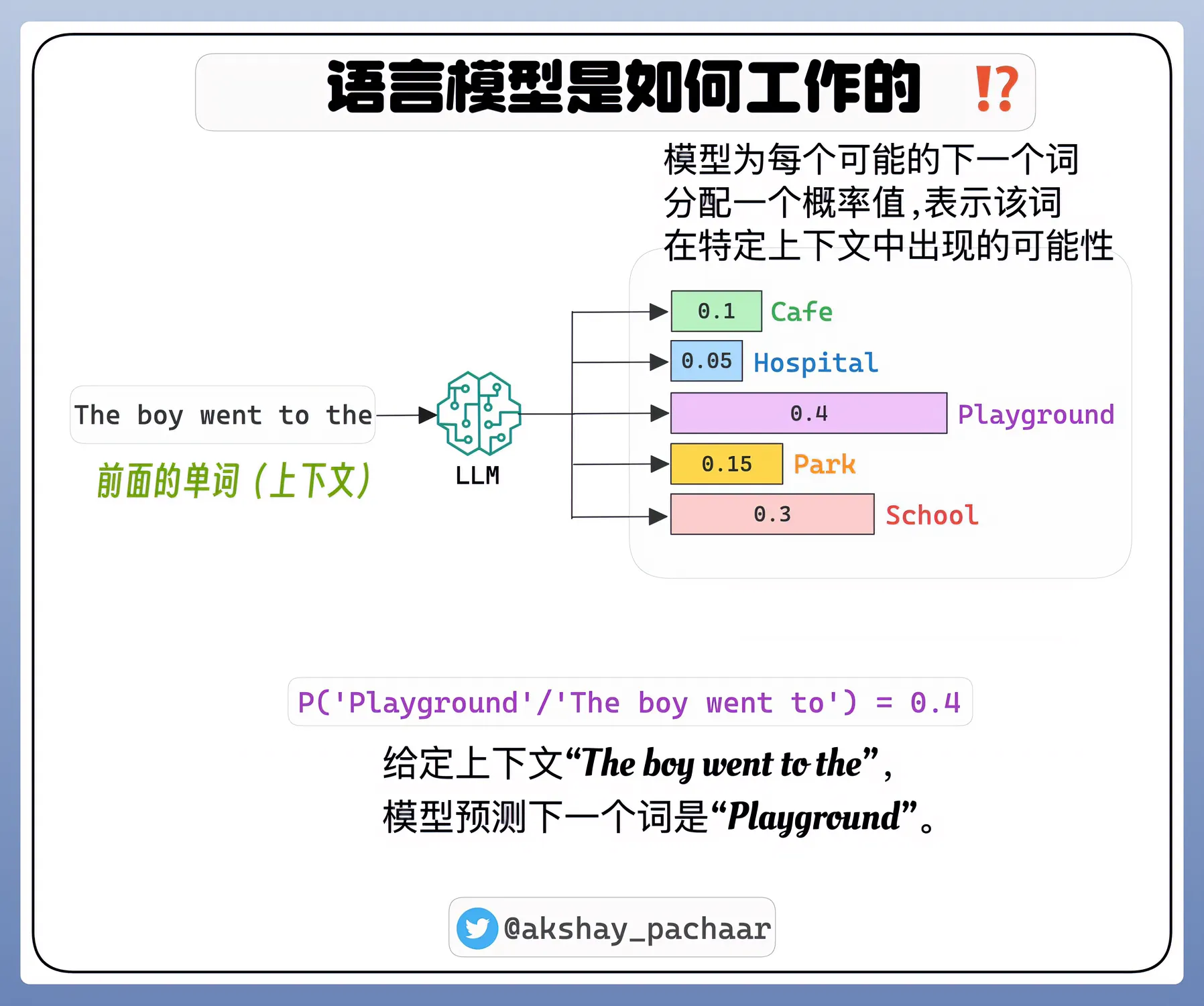
👋大型语言模型(LLMs)的基本工作原理
1、RAG模型:
- 接收用户查询后,会编码查询信息。
- 然后在向量数据库中检索相关的文档。
- 最后利用查询信息和检索到的文档内容来生成响应。
2、HyDE模型:
- 同样接收用户查询后,也会对查询进行编码。
- 但不同于RAG直接检索文档,HyDE会利用编码后的查询生成一段”假设性文本”作为补充上下文。
- 然后将查询和生成的假设性文本一起输入到下游的学习模型中。
- 最终基于查询和生成的假设性文本,输出响应。
RAG模型依赖于实际检索到的相关文档,而HyDE模型则自主生成了一段假设性文本作为补充上下文。这使得HyDE可以更好地理解和回应用户的查询,不受实际检索结果的限制。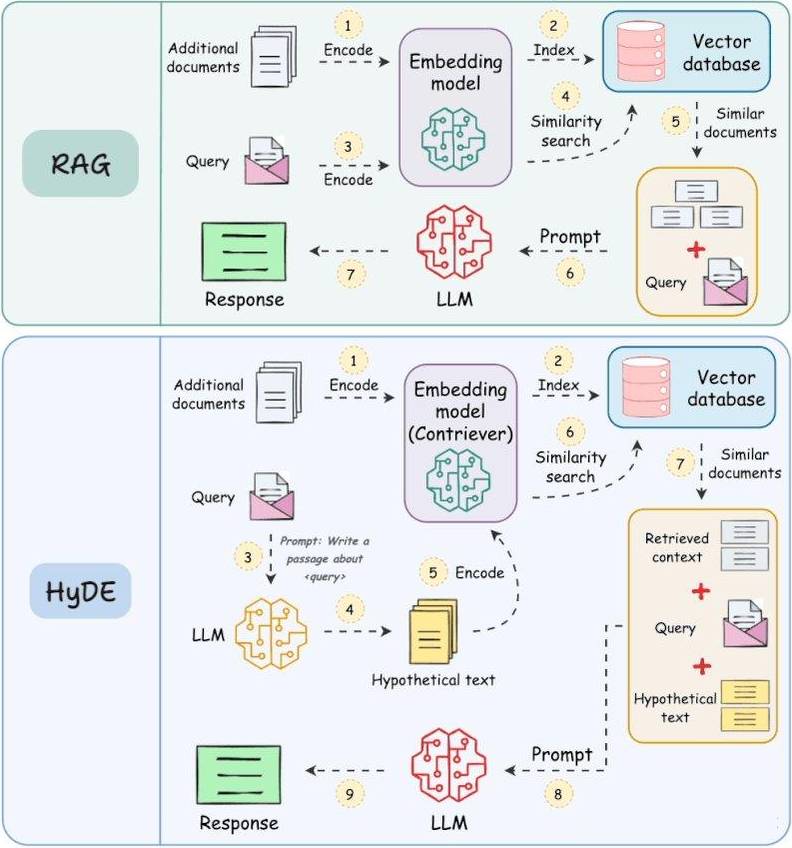
参考文献或转载相关:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 AI-X!

相关推荐



评论


