C&C++编程之CPU眼里的C&C++内容学习
C&C++编程之CPU眼里的C&C++内容简介
从CPU的视角,多角度地揭秘编程语言背后的运行原理和设计之美。
全书共6章:
第1章:介绍本书所使用到的主要工具和一些需要心里有数的预备知识;
第2章:解析最简单、常用的基础语法,帮助读者适应本书的节奏;
第3章:为进阶知识,会从CPU、操作系统的角度,深入分析函数的工作原理和实现细节;
第4章:解析经典的C语法,背后的实现逻辑,并介绍“面向对象”的编程思想及优缺点;
第5章:讨论跟操作系统强相关的软件技术,会将所有章节的内容贯穿起来,初步形成一个现代操作系统的运作模型;
第6章:我们会讨论一些经典的面试、笔试题,跟读者一起分享工作、学习、求职中的苦与乐。
第1章 预备知识
1.1 工具介绍
Compiler Explorer反编译工具
1.2 CPU眼里的程序运行
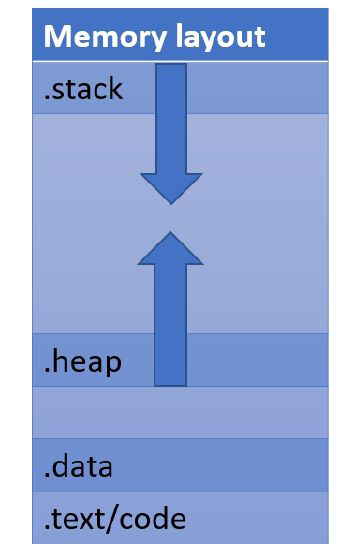
程序执行时读入到内存的位置
1.3 CPU眼里的汇编语言
CPU的初始状态,所有的寄存器初始值都是0x100。
其中寄存器rax,一般用来存放数值,有点类似C语言的普通变量;而寄存器rbp,rsp,一般用来存放内存地址,有点类似C语言的指针变量
有些机构给出的结论显示:CPU的内存读写,占据了CPU 90%的工作负荷。
这也是为什么苹果的M系列CPU,在没有显著提高CPU核心频率的情况下,也能产生秒杀同类的炸裂性能,因为它着重优化了CPU读、写内存的效率。
总结
(1)虽然完整的CPU寄存器和指令集比较庞大。但编译器只会用到很小的一部分,而且使用的套路也很单一。一旦克服恐惧心理,就很容易掌握。
(2)C/C++语言对应的汇编指令存在大量的类似“指针”的操作,我们也叫它寄存器间接寻址。夸张地说“指针”不仅是C语言的灵魂,也是汇编语言的灵魂。
(3)相比于精简指令集,复杂指令集对程序员而言,更加接近C语言。在那个只有汇编语言的年代,复杂指令集,十分有助于提高编程效率。
第2章 基础语法
2.1 CPU眼里的main函数
链接错误,找不到main函数!让我们修改一下编译选项,通过设置-efunc给它指定一个程序起点,即函数func,编译通过,运行也成功
2.2 CPU眼里的变量
一般来说,无论是什么型号的内存,它们的“金手指”连接线都存在两类重要的信号线:数据信号线和地址信号线。顾名思义,数据信号线用来在计算机和内存之间传递数据信息。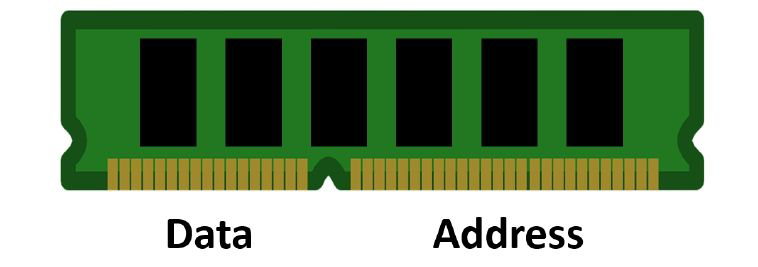
如上图所示,右边是内存的存储单元,用来存放各种数据;左边则是用来指示其存储单元位置的内存地址。
2.3 CPU眼里的goto、if else
总结
(1)程序在需要跳转的时候,往往都存在一个goto语句,虽然代码上看不到goto,但编译器已经生成了goto对应的CPU指令。
(2)goto作为代码的重要技巧,有时候也有其独特的优势,完全禁止程序员使用,或许有点武断。
(3)只有真正明白goto的意义和风险,我们才可以对其充分利用,扬长避短
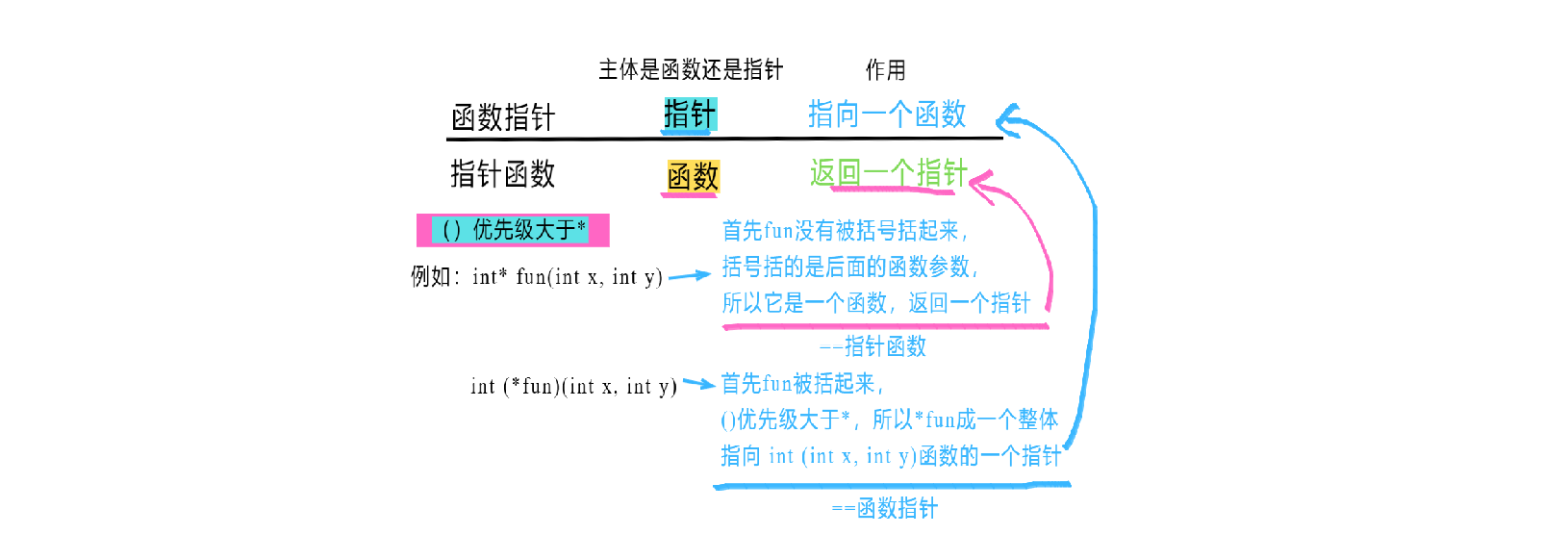
2.4 CPU眼里的指针变量
提出问题
指针变量
指针*操作
好了,知道了指针变量是用来记录内存地址的。那么得到内存地址后,下一步会做什么?毫无疑问,当然是疯狂、自由地内存读写。夸张地说,如果不是为了实现内存的自由读写,指针就没有存在的必要。
指针±操作
总结
- 普通变量,通过变量名称(内存地址的别名),来避免程序员直接读、写内存;
- 指针变量,则反其道而行之,需要获得明确的内存地址,让程序通过*操作,直接去读、写内存。
2.5 CPU眼里的指针本质和风险
提出问题
代码分析
最熟悉的变量读、写,其本质还是等同于对变量地址的指针操作。正如变量的定义所言,变量不过是内存地址的别名。
指针的风险
所以,暴露任何数据、函数的内存地址,都是巨大的风险!因为这些地址,都可以用来做违规、不受控的指针、->操作。或许这也是大家对指针又爱又恨的原因吧!而当今比较流行的编程语言C#、Java、JavaScript、Python、Rust,干脆就禁用内存地址和指针了。
总结
(1)指针操作(*、->)不是指针变量的专利,普通变量,甚至立即数,也可以做指针操作。夸张地说:所有变量、对象的读、写操作,都是基于指针来实现的。
(2)计算机的世界里面,万物皆有地址,所以,万物皆可指针。
热点问题
2.6 CPU眼里的数组
提出问题
一维数组
多维数组
所以,无论数组是一维的还是多维的,都是一段连续的一维内存。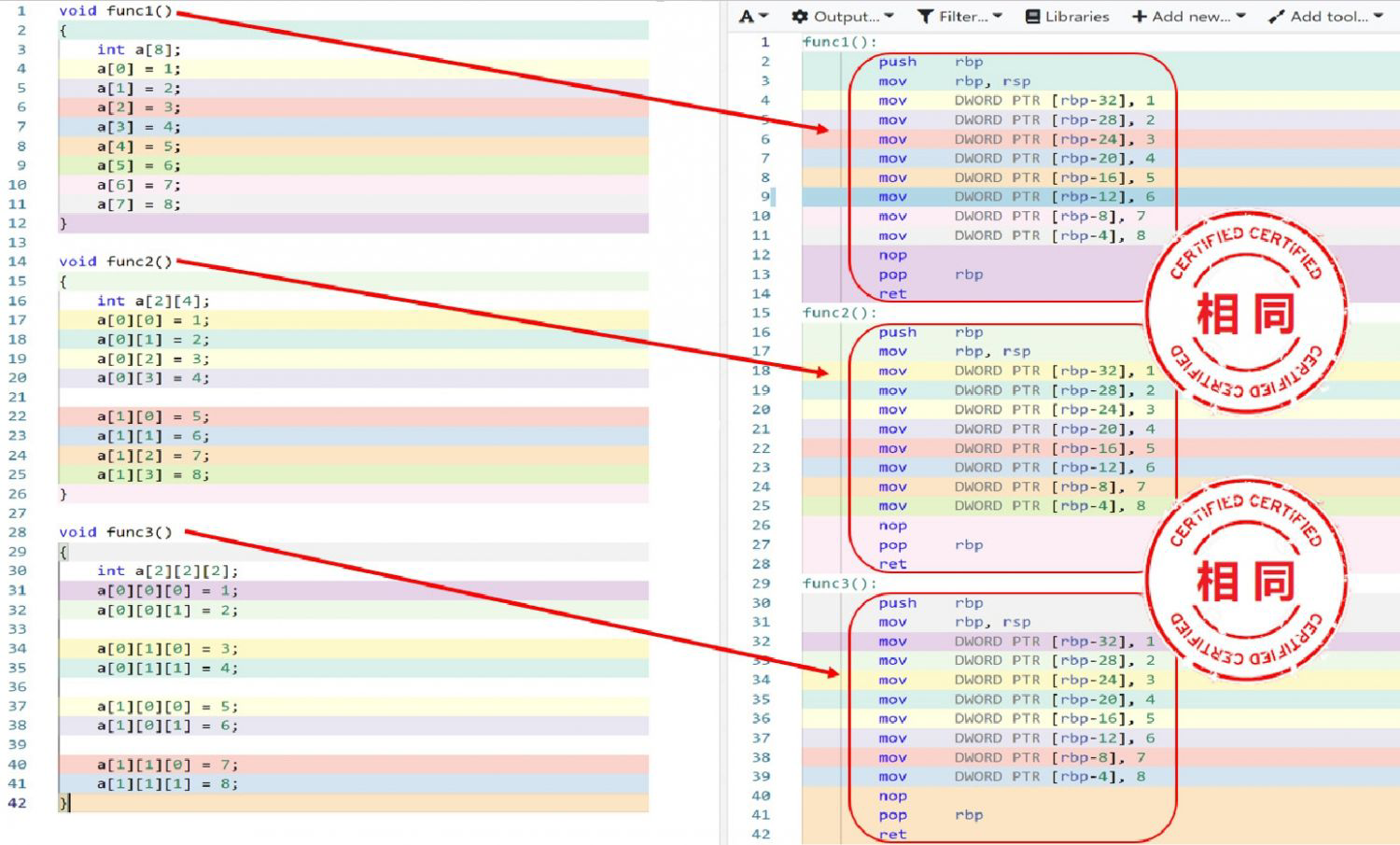
总结
(1)数组是一段连续的内存,除了常规读、写数组元素的方法;也会用指针来表示数组,并用指针的*操作来读、写数组元素。
(2)传递数组参数,本质上是传递指针,所以,在函数内改变数组的值,也会改变函数外数组的值。
(3)多维数组本质上还是一维数组,只是索引的方式不同,应用的场景不同,特别是3D领域,用多维数组编程,会给开发者带来诸多方便
2.7 CPU眼里的数组越界
总结
(1)数组向高端地址越界(内卷),会修改堆栈中的关键数据,程序往往会立刻崩溃(segmentation fault);同时,这也容易被黑客利用,用来执行事前准备好的恶意代码。
(2)明枪易躲,暗箭难防!数组向低端地址越界(拓展),程序往往不会马上崩溃。可一旦与其他函数变量冲突时,其诡异行为绝对超出你的想象。所以,无论哪种越界,都要积极避免
2.8 CPU眼里的引用
总结
(1)“引用变量”也是变量,在底层实现上面,跟“指针变量”完全相同。
(2)“引用变量”也被称为某个变量的别名,这非常形象。但似乎很难解释为什么在函数func4中改变r的值,会同时改变外部变量a的值。但如果你把“引用”当作“指针”看待的话,这个问题就迎刃而解了。
2.9 CPU眼里的i++与++i
提出问题
代码分析
差异分析
总结
(1)对于简单数据类型(int、short、char、long),前加(++i)和后加(i++)几乎没有效率上的差异,在不同的编译环境下,前加(++i)可能会略快,但优势可以忽略不计。
(2)对于复杂数据结构,特别是class,后加(i++)需要构建临时对象,会放大后加(i++)的劣势。所以,对象的++运算,首选前加(++i)
2.10 代码陷阱类型转换
提出问题
代码分析
解决办法
编程轶事
第3章 函数原理
函数本身也是非常成功的软件技术,它在占用很少内存的情况下,实现了程序的高效跳转和原路返回,以及分配临时变量,也叫“栈”变量
3.1 CPU眼里的参数传递
提出问题
代码分析
传值:变量值,不可改
传指针:变量值,可改
传引用vs传指针
总结
(1)在CPU眼里,没有传值、传指针的概念,或许它们唯一的区别只是传递的数值、意义略有不同。需要注意的是,传递指针是在传递某个内存地址的值,它是内存的身份ID,十分敏感,需要相当慎重。
(2)传递参数,就是在给CPU寄存器赋值,CPU寄存器是“主调函数”向“被调函数”输入参数的载体。
(3)如果传递的参数比较复杂,例如传递对象,仅仅靠有限的CPU寄存器就不行了,而往往会使用堆栈,但无论使用哪种载体,其工作原理都是完全一致的,都是在“主调函数”与“被调函数”之间传递信息
3.2 CPU眼里的函数括号{}
提出问题
代码分析
总结
(1)操作系统会为每个任务(进程或线程)分配一段内存当作任务“堆栈”;CPU则提供两个寄存器esp、ebp,用来标识当前函数对“堆栈”的使用情况。随着函数的逐层调用,函数的“栈帧”会逐次堆叠,互不重合;随着函数的逐层返回,函数的“栈帧”会被就地放弃,但不会清理内存
(2)正括号,用来保护上层主调函数(main)的“栈帧”,并设置被调函数(func)的“栈帧”。反括号,用来放弃被调函数(func)的“栈帧”,同时,恢复主调函数(main)的“栈帧”。这样,被调函数执行完后,主调函数就能继续执行。
(3)寄存器ebp作为当前函数的“栈帧”基地址,配合一定的偏移,就可以读、写函数体的临时变量。如果一个变量是通过ebp寄存器间接访问的,那么它往往是临时变量,也叫“栈”变量。
(4)不同编译器对“栈帧”的实现方法略有不同,但思路一致,一通百通
3.3 CPU眼里的调用和返回
提出问题
代码分析
热点问题
总结
(1)主调函数,在调用函数时,会把返回地址偷偷存放在“堆栈”中。
(2)被调函数返回时,会从“堆栈”中取出返回地址,引导CPU跳回到主调函数。
(3)不同编译器在实现函数返回上会略有不同,但殊途同归,一通百通。
最后,函数返回的设计方法简洁、高效;但缺点是返回地址这种关键数据离临时变量太近。容易被越界访问,导致程序意外崩溃,也为黑客攻击留下了难以弥补的窟窿。
所以,用C/C++编写代码对程序员的要求很高。即便语法规则滚瓜烂熟,也难以百毒不侵;需要眼中有代码,心中有指令;强大的内功才是避坑的关键
3.4 CPU眼里的函数指针
提出问题
代码分析
总结
(1)如2.5节“CPU眼里的指针本质和风险”所说的万物皆有地址,万物皆可指针,函数指针跟指针变量一样,都是用来存放内存地址的。指针变量往往存放着某个变量的内存首地址,而函数指针往往存放着某个函数的内存首地址。
当然,用普通变量存放变量或函数的地址也是可以的,但不提倡!
(2)普通变量因为用法、字节长度的不同,需要定义不同的变量类型。函数也不例外,因为参数、返回值的不同,也需要事先定义(typedef)相应类型的函数指针,从而帮助主调函数正确地给函数指针传递参数和获取返回值。
(3)传递函数指针其实就是在传递某个函数的内存首地址。谁能得到某个函数的内存地址,就能随时调用这个函数。这为编程带来了极大的便利和灵活性,例如回调函数、虚函数,都是利用函数指针来实现的。
(4)函数指针虽然灵活,但因为无法直接看出它在调用哪个函数,因此,函数指针会损害代码的可读性;随着函数指针的增多,程序的维护成本也会越来越高。
最后,无论是普通变量、指针变量,还是函数指针,它们都是变量,都是某个内存地址的别名,都是用来存放数据的。只是因为数据本身的用途不同,做了细分,透过繁华,看清本质,能减少不必要的语法记忆
3.5 CPU眼里的函数返回值
提出问题
代码分析
总结
(1)对于返回原生的数据类型(int、short、long)和指针、引用类型时,往往会使用寄存器rax,向主调函数传递返回值。
(2)对于返回复杂数据类型,例如结构体、类对象、数组、字符串时,则需要避免返回“栈”变量或“栈”对象。这往往需要开发者提前预留或申请(malloc/new)内存,用于保存函数的返回结果。
(3)返回值问题的本质还是内存问题。“堆栈”内存中的数据是不稳定的,随时可能被某次的函数调用改写。所以,“堆栈”内存中的数据,无论是用来作返回值,还是其他用途,都是不可靠的!C/C++默认不会对“堆栈”数据进行内存管理和垃圾回收,所以在返回数据时,需要对数据的生命周期有精确、严密的控制。相比之下,Java、C#、Python则没有这样的烦恼,这也让它们的API看上去更加易用。
3.6 CPU眼里的堆和栈
提出问题
“栈”的分析
“栈”的生长方向
“堆”的分析
“堆”的生长方向
总结
(1)“栈”内存由操作系统分配给每个任务(线程)私用,不可共享。但由于“栈”往往得不到MMU的特殊保护,所以,这种愿望或许是难以实现的。因为只要得到某个栈变量的地址,线程A和线程B就可以相互攻击、黑化对方的“栈”。而“堆”内存,往往可以被多个任务(线程)共享,所以,保证数据的完整性就显得非常必要。
(2)“栈”内存的空间一般比较小,多用于存放“栈”变量、返回地址等函数的栈帧信息。但过深的函数调用或者递归调用,会有“爆栈”(也叫“堆栈”溢出、stack overflow)的风险。一般随着函数的逐层调用,函数会自动地申请“栈”内存;随着函数的逐层返回,函数也会自动地回收“栈”内存。一般情况下,不会产生内存碎片和内存泄漏。而堆的内存空间相对比较大,可用于存放较大的数据。堆内存的申请、释放,只能由程序员编写相应的代码,调用特定的函数,手动申请、释放。但随着程序的复杂,内存碎片、内存泄漏会时有发生。
(3)“栈”的访问效率极高,特别是申请、释放内存的操作,都被编译器高度优化。往往只需要一条CPU指令(push、pop),改变一下CPU寄存器rsp的值,就能完成任务。而堆的申请、释放函数就会复杂许多,多次使用后还会产生内存碎片。
至于在没有操作系统的时候,“堆”和“栈”就需要程序员手动划分内存空间。相信做过单片机开发的同学,对此一定不陌生。
3.7 函数实验回溯函数调用关系
提出问题
代码分析
traceback可以将一系列的函数调用轨迹回溯出来
第4章 C++特性
4.1 CPU眼里的this
提出问题
代码分析
总结
(1)this指针不是幽灵,它不能凭空产生。它是每一个成员函数必须具备的“隐藏参数”,其实现方式跟有参数的普通函数完全一致。
(2)调用成员函数时,必须为成员函数传递this指针,也就是该对象本身的内存地址。不要忘了,指针的本质就是内存地址。
最后,阿布很欣赏this这种简洁的语法操作。但如果能大方地承认,成员函数都会有一个隐藏参数this,这样,会不会更清晰呢
4.2 CPU眼里的构造函数
提出问题
代码分析
总结
(1)构造函数跟普通函数一样,都需要夹带一个隐形的参数:this指针。
(2)派生类的构造函数,还会夹带调用基类的构造函数。
(3)如果存在虚函数,构造函数会记录虚函数表的地址,并保存在一个隐藏的成员变量里面,随身携带,随用随取;这个隐藏的成员变量,往往位于对象的内存首地址
4.3 CPU眼里的虚函数
提出问题
代码分析
总结
(1)虚函数在函数体的实现方面跟普通函数没有任何区别。
(2)虚函数的调用,需要借助类对象的隐藏变量V来完成,隐藏变量V会在构造函数中被初始化成虚函数表的内存地址。
当然,虚函数的实现,本质上还是通过函数指针实现的,虽然避免了程序员使用函数指针,但也让虚函数的语法规则变得相对复杂、诡异。
4.4 CPU眼里的多态
提出问题
代码分析
总结
(1)多态,常会用基类指针指向派生类对象。
(2)多态,会利用派生类的结构特点复用基类的属性(变量/函数)。
(3)多态,会利用虚函数来扩展派生类的特性。
最后,多态不是C++的专利,很多语言都支持多态,例如Java。与其说多态是语法规则,不如说是设计技巧。
4.5 CPU眼里的模板
提出问题
代码分析
总结
(1)CPU对模板是无感的,模板本质上是编译器根据我们提供的脚本自动补充代码,涉及的数据类型越多,代码版本也就越多。
(2)编译器自动补充的代码对程序员是不可见的。所以,在单步调试的时候,会出现源代码无法一一对应的问题,模板的相关代码,往往只能黑盒测试,很难找到有效的调试方法。
(3)在对类进行模板化操作的时候,如果涉及数学、逻辑运算,由于编译器往往无法提供默认的运算符操作,就需要程序员手动为类重载这些运算符,避免可能的编译错误。
最后,很多情况下你是不需要亲手写模板的。相比从头写一个高风险的模板,直接使用STL (也就是标准模板库)显得更加高效、稳定、可靠。
4.6 CPU眼里的malloc和new
提出问题
代码分析
总结
(1)malloc和free都是单纯的函数,用来申请内存和归还内存。
(2)new包含了两个操作。第一个操作,跟malloc类似,也是申请内存;第二个操作,是对申请到的内存,也就是类A的实例对象,进行初始化,没错,就是调用类A的构造函数。至于delete操作,则正好相反。
(3)无论是malloc还是new,它们都是可以被重载的,特别是开发操作系统和嵌入式系统时,往往没有可以直接使用的默认函数,开发者需要根据硬件配置和具体需要,重写合适的内存分配函数。
最后,默认情况下,系统提供的malloc和new都会从“堆”上申请内存,但如果自己重载了malloc和new,那到底从哪里申请内存,就全靠自己把握了。
4.7 面向对象实践依赖反转
提出问题
GuiLite介绍
代码结构
总结
(1)面向对象和面向过程,总是你中有我,我中有你;但如果代码小于100行,面向对象就很难有发挥的空间了。
(2)C语言也可以实现面向对象。但会相当烦琐,会伴随大量的函数指针;相反,用C++实现面向对象,会更加优雅、简洁。这是因为编译器隐藏了这些函数指针,这也让C++语法看上去非常魔幻。
(3)尽量使用class,相比struct,它的优势不是一丁点儿。良好的设计,能让你有效地重塑代码结构,实现代码复用。
(4)为了实现灵活扩展,可以采用依赖反转原则,对关键接口进行抽象。良好的设计,能帮你稳定程序结构,用最少、最必要的代码,实现功能扩展。但每一次抽象,都是对代码可读性的伤害,所以,每次抽象,一定要切中要害,切勿随心所欲。
第5章 高级编程
5.1 CPU眼里的虚拟内存
提出问题
虚拟内存原理
减少内存碎片
简化运行条件
隔离进程
内存共享
SWAP
总结
(1)虚拟内存是操作系统和硬件MMU的结合体,为了不损失效率,往往由MMU来做虚拟内存到物理内存的地址翻译工作。相信做过FPGA的同学,实现起来问题不大。
(2)虚拟内存一方面简化了应用程序的开发过程,让程序员无须关心与软件功能没有直接关系的信息,例如目标机的内存环境;它也能充分地利用计算机的内存资源、硬盘资源,还实现了进程间的安全隔离;但另一方面,它也增加了操作系统的开发难度、学习成本和CPU的硬件成本。
(3)不是所有的计算机系统都需要虚拟内存,例如STM32单片机和嵌入式环境,它们很多是不支持虚拟内存的,甚至Linux也有无虚拟内存的版本ucLinux。
5.2 坐井观天的进程
进程、线程、虚拟地址、物理地址
5.3 CPU眼里的地址映射
提出问题
问题分析
总结
(1)MMU通过程序员或者操作系统提供的页表,进行虚拟地址到物理地址的转换。该转换过程由MMU自动完成,CPU全程无感。
(2)每个进程,都有一张自己的页表;若它们的页表不同,则它们的进程空间是被隔离的;若页表相同或部分相同,则是在做进程间的内存共享,如图5-31所示。
而线程没有独立的页表,它们共享同一个进程的页表,所以,线程之间,天生就可以内存共享。
(3)“分页”不仅针对物理地址,也应用于虚拟地址;它能有效地减小地址映射表的体量。页表里的值,不仅可以是真实的内存地址,也可以是硬盘上的扇区信息,这样,在内存不够用时,也可以用硬盘来补位。在内存十分珍贵、紧张的年代,这种技术无疑是革命性的。
当然,很多程序都不会用尽全部的内存,但一级页表却为整个内存建立映射,实在有点浪费。为了按需分配,现代操作系统往往会引进二级页表,可以用来进一步缩小页表的体量
5.4 CPU眼里的volatile
提出问题
代码分析
总结
(1)编译器可能对代码中的变量读、写进行适当的优化,避免没有必要的内存读、写操作,这往往会大幅度提升程序的执行效率。但编译器也是程序,只能针对特定情况做特定的优化,当程序变得复杂时,编译器也未必能完全领会程序员的意图,所以,有些时候这种优化是有害的。
(2)volatile关键字,就是用来避免编译器的优化操作,用来保证每次对变量的读、写都是对内存的真实操作;特别是不会让编译器把某些变量当作常量对待。
(3)在编译器不开优化的情况下,很多时候,是否加volatile,不会有任何差异。这也让volatile的使用场景变得十分模糊。判定volatile是否有存在的必要,往往需要查看代码对应的CPU(汇编)指令,看看它是否合乎程序员的预期。
最后,不得不说,随着编译器的技术进步和各大编译器之间的巨大差异,判定一个变量是否可以被优化,也没有一个统一的标准。这也让volatile成为了一个最为生僻、晦涩的语法之一。
而逐个分析每一个变量是否需要volatile,也非常不现实。所以,谨慎使用优化,或使用统一的编译器,并确保各个软件版本的优化等级一致,就显得非常必要
5.5 CPU眼里的常量
提出问题
代码分析
总结
(1)常量并不仅仅是不能改变初值的变量,也是不允许对其二次写入的变量。除此之外,它跟普通变量一样,也是某个内存地址的别名。
(2)编译器可以通过对代码的解读,阻止明显的、针对常量的写操作。但由于常量跟变量一样,也只是内存地址的别名,所以程序员很容易通过指针或类型转换的方式,逃过编译器的检查。
(3)真正保证常量不被写入的安全阀是MMU,它能从物理上阻止对特定内存的读写。如果常量所在的内存页是不可读写的,例如read only数据段,那么写操作会被MMU阻止,并产生CPU异常。
但如果常量所在的内存页是可读、写的,例如函数内部定义的临时的“栈”常量,由于“堆栈”本身是可读、可写的,所以在逃过编译器检查后,“栈”常量也是可以顺利写入的.
5.6 CPU眼里的系统调用
提出问题
代码分析
总结
(1)“系统调用”跟“函数调用”一样,都可以通过寄存器来传递参数,但会用syscall指令触发CPU异常,从而让操作系统,接管后面的功能实现。
(2)系统调用会引发CPU状态切换,CPU在用户态准备参数,然后切换到内核态完成功能。
(3)系统调用能够有效的隔离应用程序和操作系统核心,提高整个系统的安全性。
(4)系统调用的实现,会因为CPU指令集的不同而不同。几乎所有重要的库函数,都需要通过系统调用来实现.
5.7 CPU眼里的大端、小端
提出问题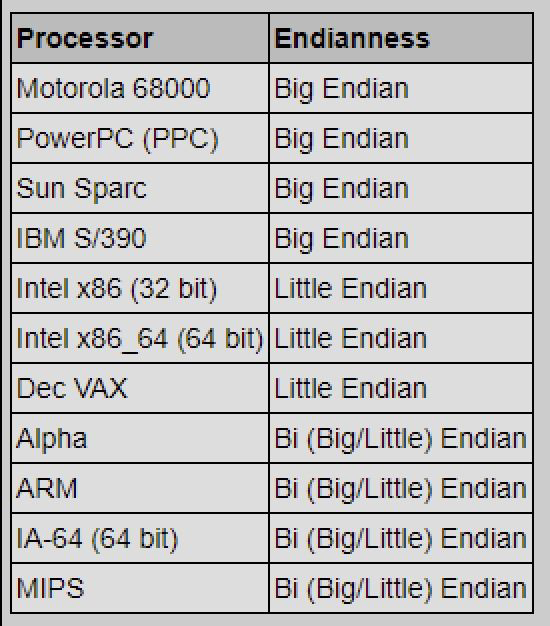
代码分析
总结
(1)CPU在从内存中读、写多字节数据(long、int、short)时,不同的模式,对数据的高、低位的解读顺序是不同的,也就是CPU的大、小端差异。
(2)为了克服因为大、小端差异,造成的数据解读歧义,我们可以用单字节的字符串,进行数据共享,例如在物联网中,广泛使用的JSON格式。
(3)今天仍然有很多设备,例如I2C、SPI设备还是会发送、接收多字节数据,开发者需要根据设备手册来确定设备是先发高位字节,还是先发低位字节。并根据自己的CPU类型,手动适配。
最后,大小端问题,仅仅针对于多字节的数据类型,对单字节里面的每个位(bit)是没有影响的。正因如此,我们在传递单个字节或字符的时候,并不会产生颠倒问题。
5.8 CPU眼里的上下文
总结
(1)简单地说:上下文,就是CPU当前的寄存器信息。保存、恢复上下文的过程,就像是保存和恢复一个人的记忆,通过恢复CPU过去的记忆,让CPU回到过去的状态。
(2)除了中断、任务调度会强行保存、恢复上下文,程序也可以主动保存上下文。例如:通过调用sleep、mutex、semaphore主动放弃线程或进程的运行机会,迫使操作系统保存上下文。
(3)不同线程的代码、数据、堆栈也可以放在同一个内存颗粒上,一般来说,不同线程的代码、数据,是不会被混淆的。当然为了安全,也可以进程的形式运行,因为MMU可以实现进程间,在内存空间上的隔离。
最后,实际情况下,程序用到的寄存器不止我们提到的4个,需要对更多的寄存器进行保存和恢复工作。不同的操作系统、CPU在实现上下文上面,也会有所差异。
5.9 CPU眼里的锁
总结
(1)Mutex的本质还是Semaphore,只是可用的共享资源上限是1而已,从而变相的实现了互斥。
(2)加锁操作,会让当前线程消耗1份共享资源;但如果资源已经枯竭,当前线程只能就地休眠,等待资源。而死锁,优先级反转问题,也往往在这个阶段产生,需要十分慎重。
(3)解锁操作,会返还1份资源,并试图唤醒还在等待资源的线程。
如你所见,锁通过线程主动放弃运行机会的方法,来协调多线程对公路、停车场等共享资源的竞争,实现线程之间的协调,也就是我们常说的同步。
需要注意的是我们用“锁”保护的是资源、数据,而不是保护某个操作或者某个函数。所以,在进行“锁”操作的时候,我们要把影响范围尽量控制在一个小的范围,不要为了保护某一个变量,而锁住整个或者大片的函数。
第6章 面试挑战
6.1 static、global以及local
总结
(1)全局变量和静态变量的内存地址是固定的,但临时变量的内存地址,往往不是固定的。
(2)静态变量,除了作用域跟全局变量有所差异外,其存储原则、生命周期跟全局变量类似。
(3)无论是全局变量还是静态变量,如果它们没有被初始化,或者被初始化为0。都会被安置在未初始化数据段,一定程度上可以节省二进制文件a.out的存储空间
6.2 数组和双重指针
6.3 指针为什么这么难
提出问题
学习指针的困境
指针的普通性和特殊性
多重指针
数组、指针的混用
6.4 auto的工作原理
提出问题
代码分析
总结
(1)auto在一定程度上,会简化程序代码,增加代码的可读性。
(2)auto在一定程度上,可以减少代码对数据类型的依赖,从而提高代码的稳定性和重构效率、扩展效率。
(3)过度使用auto,也可能适得其反,因为auto并不能提供足够的类型信息,当推理过程过于复杂时,反而会损失代码的可读性。如果只是简单地用auto定义一个有初值的变量,请放心使用auto。但如果用auto替代指针和引用类型时,就可能产生一些非预期的错误,需要谨慎使用。
最后,弱类型和强类型哪个更为合理也颇有争议。虽然弱类型有很多问题,但其良好的易用性仍然让JavaScript年年可以轻松登顶编程语言排行榜。而号称专门用来改善JavaScript的弱类型缺点的TypeScript,尽管跟JavaScript完全兼容,但影响力远远不如JavaScript
6.5 thread_local的工作原理
总结
(1)操作系统在创建线程的时候,除了会给每个线程创建函数“堆栈”,还会划出一部分区域来存储一个或多个thread_local变量。
(2)类似于用寄存器esp来标识线程当前“堆栈”栈顶的内存地址,编译器也常用寄存器fs来标识所有thread_local变量,所在的内存首地址配合偏移量,就可以精确寻找到每一个thread_local变量。
这是非常聪明的设计,不仅实现起来非常简洁,而且几乎没有增加任何运行成本。
(3)thread_local并非没有替代方案,例如在创建线程之前,我们可以申请一段内存块,交给该线程私用。并通过参数传递的方式,将内存首地址传递给该线程的主函数
6.6 面试的技巧
常见问题
应对技巧