
TensorFlow深度学习技术
第1章 人工智能绪论
1.1 人工智能
人工智能、机器学习、神经网络和深度学习关系: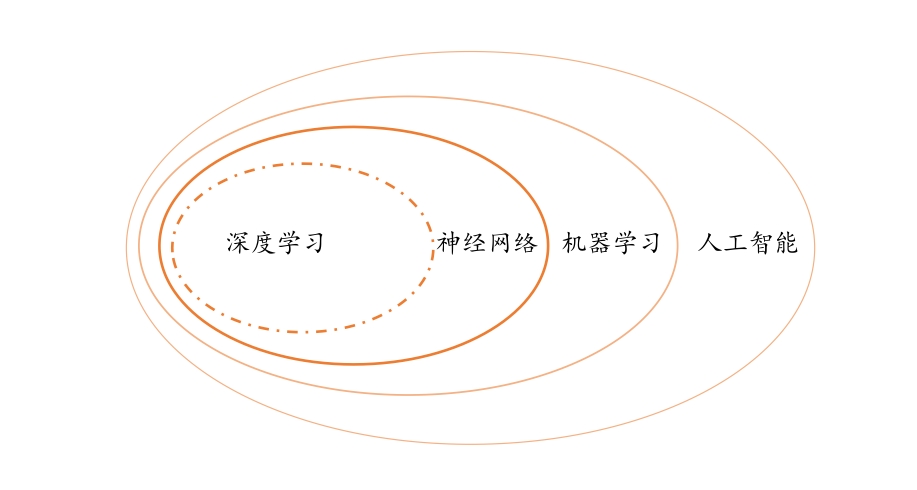
机器学习分类: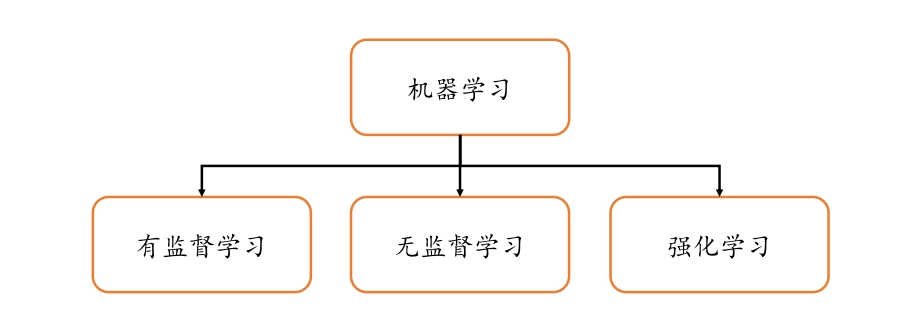
深度学习与其它算法区别: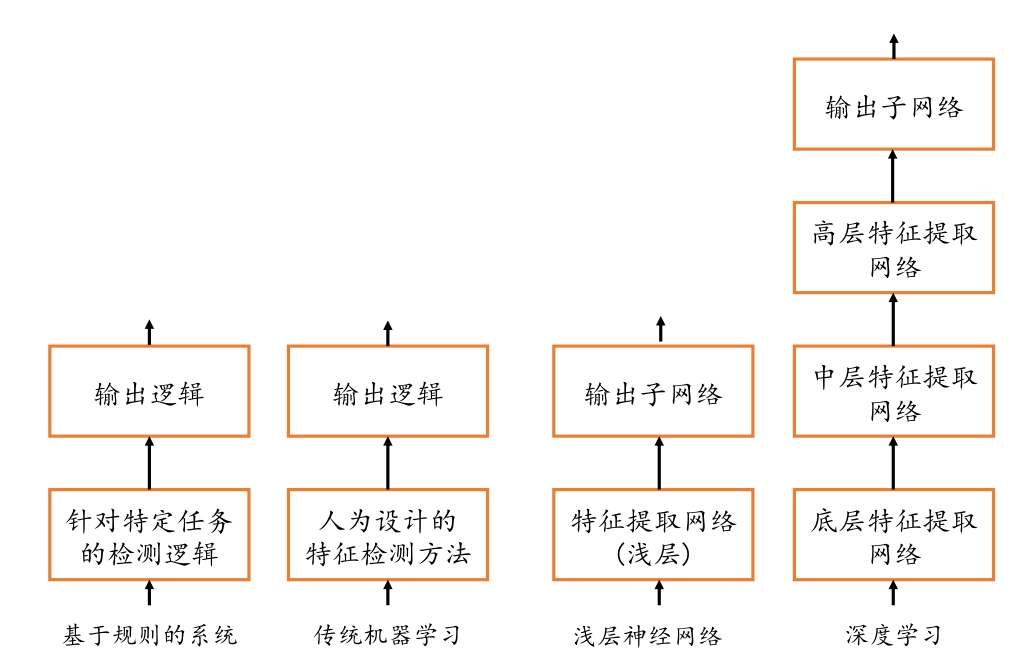
1.2 神经网络发展简史
浅层神经网络发展: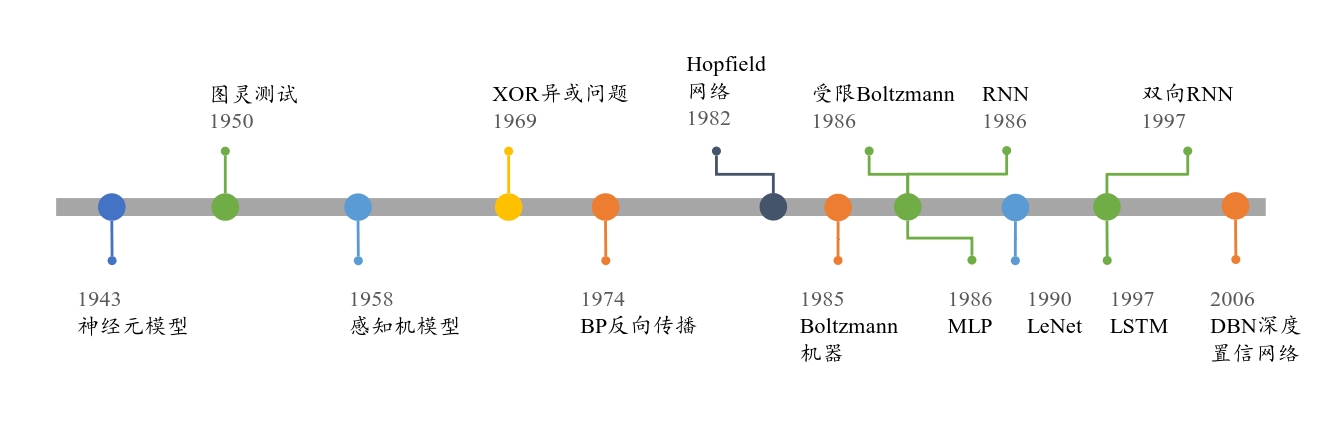
深度神经网络发展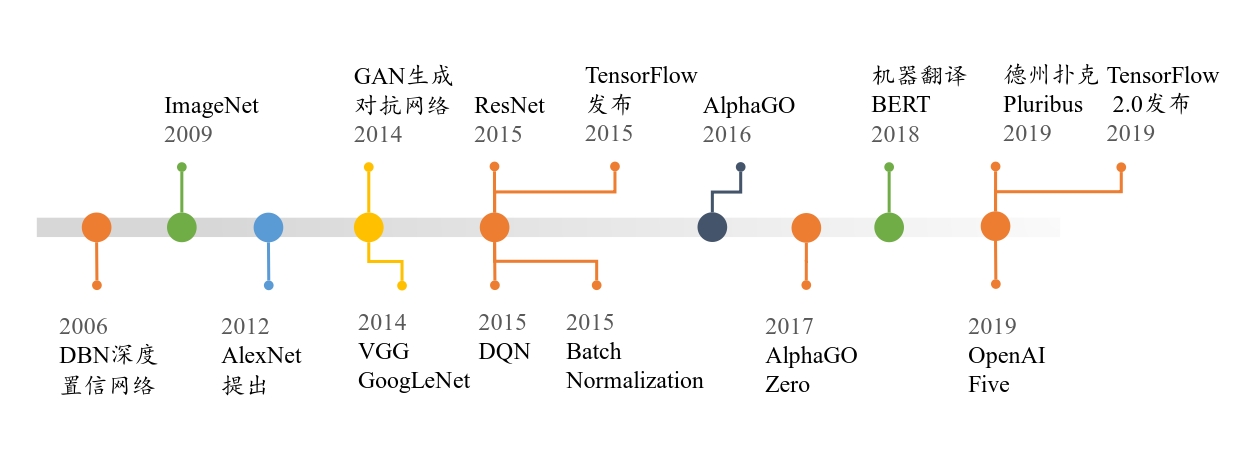
1.3 深度学习特点
1.4 深度学习应用
1.5 深度学习框架
❑ Theano 是最早的深度学习框架之一,由 Yoshua Bengio 和 Ian Goodfellow 等人开发,是一个基于 Python 语言、定位底层运算的计算库,Theano 同时支持 GPU 和 CPU 运算。由于 Theano 开发效率较低,模型编译时间较长,同时开发人员转投 TensorFlow等原因,Theano 目前已经停止维护。
❑ Scikit-learn 是一个完整的面向机器学习算法的计算库,内建了常见的传统机器学习算法支持,文档和案例也较为丰富,但是 Scikit-learn 并不是专门面向神经网络而设计的,不支持 GPU 加速,对神经网络相关层的实现也较欠缺。
❑ Caffe 由华人贾扬清在 2013 年开发,主要面向使用卷积神经网络的应用场合,并不适合其它类型的神经网络的应用。Caffe 的主要开发语言是 C++,也提供 Python 语言等接口,支持 GPU 和 CPU。由于开发时间较早,在业界的知名度较高,2017 年Facebook 推出了 Caffe 的升级版本 Cafffe2,Caffe2 目前已经融入到 PyTorch 库中。
❑ Torch 是一个非常优秀的科学计算库,基于较冷门的编程语言 Lua 开发。Torch 灵活性较高,容易实现自定义网络层,这也是 PyTorch 继承获得的优良基因。但是由于 Lua语言使用人群较少,Torch 一直未能获得主流应用。
❑ MXNet 由华人陈天奇和李沐等人开发,是亚马逊公司的官方深度学习框架。采用了命令式编程和符号式编程混合方式,灵活性高,运行速度快,文档和案例也较为丰
富。
❑ PyTorch 是 Facebook 基于原 Torch 框架推出的采用 Python 作为主要开发语言的深度学习框架。PyTorch 借鉴了 Chainer 的设计风格,采用命令式编程,使得搭建网络和调试网络非常方便。尽管 PyTorch 在 2017 年才发布,但是由于精良紧凑的接口设计,PyTorch 在学术界获得了广泛好评。在 PyTorch 1.0 版本后,原来的 PyTorch 与 Caffe2进行了合并,弥补了 PyTorch 在工业部署方面的不足。总的来说,PyTorch 是一个非常优秀的深度学习框架。
❑ Keras 是一个基于 Theano 和 TensorFlow 等框架提供的底层运算而实现的高层框架,提供了大量快速训练、测试网络的高层接口。对于常见应用来说,使用 Keras 开发效率非常高。但是由于没有底层实现,需要对底层框架进行抽象,运行效率不高,灵活性一般。
❑ TensorFlow 是 Google 于 2015 年发布的深度学习框架,最初版本只支持符号式编程。得益于发布时间较早,以及 Google 在深度学习领域的影响力,TensorFlow 很快成为最流行的深度学习框架。但是由于 TensorFlow 接口设计频繁变动,功能设计重复冗余,符号式编程开发和调试非常困难等问题,TensorFlow 1.x 版本一度被业界诟病。2019年,Google 推出 TensorFlow 2 正式版本,将以动态图优先模式运行,从而能够避免TensorFlow 1.x 版本的诸多缺陷,已获得业界的广泛认可。
目前来看,TensorFlow 和 PyTorch 框架是业界使用最为广泛的两个深度学习框架,TensorFlow 在工业界拥有完备的解决方案和用户基础,PyTorch 得益于其精简灵活的接口设计,可以快速搭建和调试网络模型,在学术界获得好评如潮。TensorFlow 2 发布后,弥补了 TensorFlow 在上手难度方面的不足,使得用户既能轻松上手 TensorFlow 框架,又能无缝部署网络模型至工业系统。本书以 TensorFlow 2.0 版本作为主要框架,实现深度学习算法。
这里特别介绍 TensorFlow 与 Keras 之间的联系与区别。Keras 可以理解为一套高层 API的设计规范,Keras 本身对这套规范有官方的实现,在 TensorFlow 中也实现了这套规范,称为 tf.keras 模块,并且 tf.keras 将作为 TensorFlow 2 版本的唯一高层接口,避免出现接口重复冗余的问题。如无特别说明,本书中 Keras 均指代 tf.keras。
1.6 开发环境安装
1.7 参考文献
第2章 回归问题
2.1 神经元模型
2.2 优化方法
2.3 线性模型实战
2.4 线性回归
2.5 参考文献
第3章 分类问题
3.1 手写数字图片数据集
3.2 模型构建
3.3 误差计算
3.4 真的解决了吗
3.5 非线性模型
3.6 表达能力
3.7 优化方法
3.8 手写数字图片识别体验
3.9 小结
3.10 参考文献
第4章 TensorFlow基础
4.1 数据类型
4.2 数值精度
4.3 待优化张量
4.4 创建张量
4.5 张量的典型应用
4.6 索引与切片
4.7 维度变换
4.8 Broadcasting
4.9 数学运算
4.10 前向传播实战
4.11 参考文献
第5章 TensorFlow进阶
5.1 合并与分割
5.2 数据统计
5.3 张量比较
5.4 填充与复制
5.5 数据限幅
5.6 高级操作
5.7 经典数据集加载
5.8 MNIST 测试实战
5.9 参考文献
第6章 神经网络
6.1 感知机
6.2 全连接层
6.3 神经网络
6.4 激活函数
6.5 输出层设计
6.6 误差计算
6.7 神经网络类型
6.8 油耗预测实战
6.9 参考文献
第7章 反向传播算法
7.1 导数与梯度
7.2 导数常见性质
7.3 激活函数导数
7.4 损失函数梯度
7.5 全连接层梯度
7.6 链式法则
7.7 反向传播算法
7.8 Himmelblau 函数优化实战
7.9 反向传播算法实战
7.10 参考文献
第8章 Keras高层接口
8.1 常见功能模块
8.2 模型装配、训练与测试
8.3 模型保存与加载
8.4 自定义类
8.5 模型乐园
8.6 测量工具
8.7 可视化
8.8 参考文献
第9章 过拟合
9.1 模型的容量
9.2 过拟合与欠拟合
9.3 数据集划分
9.4 模型设计
9.5 正则化
9.6 Dropout
9.7 数据增强
9.8 过拟合问题实战
9.9 参考文献
第10章 卷积神经网络
10.1 全连接网络的问题
10.2 卷积神经网络
10.3 卷积层实现
10.4 LeNet-5 实战
10.5 表示学习
10.6 梯度传播
10.7 池化层
10.8 BatchNorm 层
10.9 经典卷积网络
10.10 CIFAR10 与 VGG13实战
10.11 卷积层变种
10.12 深度残差网络
10.13 DenseNet
10.14 CIFAR10 与 ResNet18 实战
10.15 参考文献
第11 章 循环神经网络
11.1 序列表示方法
11.2 循环神经网络
11.3 梯度传播
11.4 RNN 层使用方法
11.5 RNN 情感分类问题实战
11.6 梯度弥散和梯度爆炸
11.7 RNN 短时记忆
11.8 LSTM 原理
11.9 LSTM 层使用方法
11.10 GRU 简介
11.11 LSTM/GRU 情感分类问题再战
11.12 预训练的词向量
11.13 参考文献
第12章 自编码器
12.1 自编码器原理
12.2 MNIST 图片重建实战
12.3 自编码器变种
12.4 变分自编码器
12.5 VAE 实战
12.6 参考文献
第13章 生成对抗网络
13.1 博弈学习实例
13.2 GAN原理
13.3 DCGAN实战
13.4 GAN变种
13.5 纳什均衡
13.6 GAN训练难题
13.7 WGAN原理
13.8 WGAN-GP实战
13.9 参考文献
第14章 强化学习
14.1 先睹为快
14.2 强化学习问题
14.3 策略梯度方法
14.4 值函数方法
14.5 Actor-Critic 方法
14.6 小结
14.7 参考文献
第15章 自定义数据集
15.1 精灵宝可梦数据集
15.2 自定义数据集加载流程
15.3 宝可梦数据集实战
15.4 迁移学习
15.5 Saved_model
15.6 模型部署
15.7 参考文献
<未完待续>





