Java编程之Java高并发核心编程学习之第5-8章Netty技术
《Java高并发核心编程》卷1:内容介绍
第1~4章从操作系统的底层原理开始,浅显易懂地揭秘高并发IO的底层原理,并介绍如何让单体Java应用支持百万级的高并发;从传统的阻塞式OIO开始,细致地解析Reactor高性能模式,介绍高性能网络开发的基础知识。这些非常底层的原理知识和基础知识非常重要,是开发过程中解决Java实际问题必不可少的。
第5~8章重点讲解Netty。目前Netty是高性能通信框架皇冠上当之无愧的明珠,是支撑其他众多著名的高并发、分布式、大数据框架底层的框架。这几章从Reactor模式入手,以“四两拨千斤”的方式为大家介绍Netty原理。同时,还将介绍如何通过Netty来解决网络编程中的重点难题,如Protobuf序列化问题、半包问题等。
第9~12章从TCP、HTTP入手,介绍客户端与服务端、服务端与服务端之间的高性能HTTP通信和WebSocket通信。这几章深入浅出地介绍TCP、HTTP、WebSocket三大常用的协议,以及如何基于Netty实现HTTP、WebSocket高性能通信。
第13章对ZooKeeper进行详细的介绍。除了全面地介绍Curator API之外,还从实战的角度出发介绍如何使用ZooKeeper设计分布式ID生成器,并对重要的SnowFlake算法进行详细的介绍。另外,还结合小故事以图文并茂的方式浅显易懂地介绍分布式锁的基本原理。
第14章从实战开发层面对Redis进行介绍,详细介绍Redis的5种数据类型、客户端操作指令、Jedis Java API。另外,还通过spring-data-redis来完成数据分布式缓存的实战案例,详尽地介绍Spring的缓存注解以及涉及的SpEL表达式语言。
第15章通过CrazyIM项目为大家介绍一个亿级流量的高并发IM系统模型,这个高并发架构的系统模型不仅仅限于IM系统,通过简单的调整和适配就可以应用于当前主流的Java后台系统。
《Java高并发核心编程》卷1:第5章Netty核心原理与基础实战
Netty是一个Java NIO客户端/服务器框架,是一个为了快速开发可维护的高性能、高可扩展的网络服务器和客户端程序而提供的异步事件驱动基础框架和工具。基于Netty,可以快速轻松地开发网络服务器和客户端的应用程序。与直接使用Java NIO相比,Netty给大家造出了一个非常优美的轮子,它可以大大简化网络编程流程。例如,Netty极大地简化了TCP、UDP套接字和HTTP Web服务程序的开发。
Netty的目标之一是使通信开发可以做到“快速和轻松”。使用Netty,除了能“快速和轻松”地开发TCP/UDP等自定义协议的通信程序之外,还可以做到“快速和轻松”地开发应用层协议的通信程序,如FTP、SMTP、HTTP以及其他的传统应用层协议。
Netty的目标之二是要做到高性能、高可扩展性。基于Java的NIO,Netty设计了一套优秀的、高性能的Reactor模式实现,并且基于Netty的Reactor模式实现中的Channel(通道)、Handler(处理器)等基础类库能进行快速扩展,以支持不同协议通信、完成不同业务处理的大量应用类。
第一个Netty实战案例DiscardServer
解密Netty中的Reactor模式
Java Reactor模式中IO事件的处理流程
一个IO事件从操作系统底层产生后,在Reactor模式中的处理流程如图所示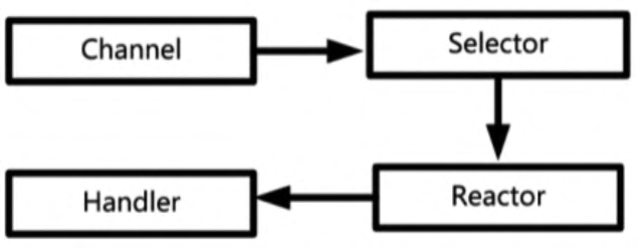
Reactor模式中IO事件的处理流程大致分为4步,具体如下:
第1步:通道注册。IO事件源于通道(Channel),IO是和通道(对应于底层连接而言)强相关的。一个IO事件一定属于某个通道。如果要查询通道的事件,首先就要将通道注册到选择器。
第2步:查询事件。在Reactor模式中,一个线程会负责一个反应器(或者SubReactor子反应器),不断地轮询,查询选择器中的IO事件(选择键)。
第3步:事件分发。如果查询到IO事件,则分发给与IO事件有绑定关系的Handler业务处理器。
第4步:完成真正的IO操作和业务处理,这一步由Handler业务处理器负责。
以上4步就是整个Reactor模式的IO处理器流程。其中,第1步和第2步其实是Java NIO的功能,Reactor模式仅仅是利用了Java NIO的优势而已。
Reactor模式的IO事件处理流程比较重要,是学习Netty的基础性和铺垫性知识。如果这里看不懂,就先回到前面有关Reactor模式详细介绍的部分内容,回头再学习一下Reactor模式原理。
Netty中的Channel
Channel组件是Netty中非常重要的组件,为什么首先要说的是Channel组件呢?原因是:Reactor模式和通道紧密相关,反应器的查询和分发的IO事件都来自Channel组件。
Netty中不直接使用Java NIO的Channel组件,对Channel组件进行了自己的封装。Netty实现了一系列的Channel组件,为了支持多种通信协议,换句话说,对于每一种通信连接协议,Netty都实现了自己的通道。除了Java的NIO,Netty还提供了Java面向流的OIO处理通道。
总结起来,对应到不同的协议,Netty实现了对应的通道,每一种协议基本上都有NIO和OIO两个版本。
对应于不同的协议,Netty中常见的通道类型如下:
- NioSocketChannel:异步非阻塞TCP Socket传输通道。
- NioServerSocketChannel:异步非阻塞TCP Socket服务端监听通道。
- NioDatagramChannel:异步非阻塞的UDP传输通道。
- NioSctpChannel:异步非阻塞Sctp传输通道。
- NioSctpServerChannel:异步非阻塞Sctp服务端监听通道。
- OioSocketChannel:同步阻塞式TCP Socket传输通道。
- OioServerSocketChannel:同步阻塞式TCP Socket服务端监听通道。
- OioDatagramChannel:同步阻塞式UDP传输通道。
- OioSctpChannel:同步阻塞式Sctp传输通道。
- OioSctpServerChannel:同步阻塞式Sctp服务端监听通道。
一般来说,服务端编程用到最多的通信协议还是TCP,对应的Netty传输通道类型为NioSocketChannel类、Netty服务器监听通道类型为NioServerSocketChannel。不论是哪种通道类型,在主要的API和使用方式上和NioSocketChannel类基本都是相同的,更多是底层的传输协议不同,而Netty帮大家极大地屏蔽了传输差异。如果没有特殊情况,本书的很多案例都将以NioSocketChannel通道为主。
在Netty的NioSocketChannel内部封装了一个Java NIO的SelectableChannel成员,通过对该内部的Java NIO通道的封装,对Netty的NioSocketChannel通道上的所有IO操作最终都会落地到Java NIO的SelectableChannel底层通道。NioSocketChannel的继承关系图如图所示。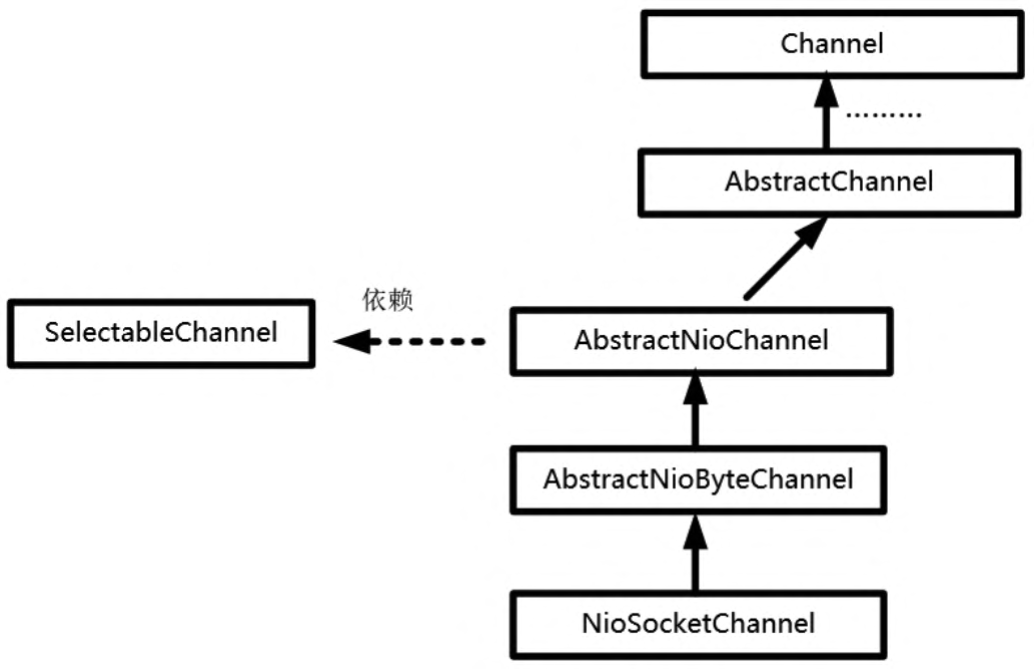
Netty中的Reactor
在Reactor模式中,一个反应器(或者SubReactor子反应器)会由一个事件处理线程负责事件查询和分发。该线程不断进行轮询,通过Selector选择器不断查询注册过的IO事件(选择键)。如果查询到IO事件,就分发给Handler业务处理器。
首先为大家介绍一下Netty中的反应器组件。Netty中的反应器组件有多个实现类,这些实现类与其通道类型相互匹配。对应于NioSocketChannel通道,Netty的反应器类为NioEventLoop(NIO事件轮询)。
NioEventLoop类有两个重要的成员属性:一个是Thread线程类的成员,一个是Java NIO选择器的成员属性。NioEventLoop的继承关系和主要成员属性如图所示。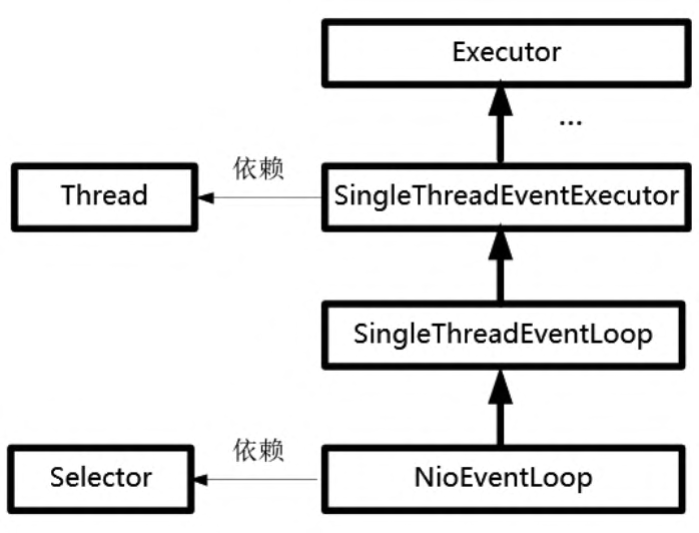
通过这个关系图可以看出:NioEventLoop和前面章节讲的反应器实现在思路上是一致的:一个NioEventLoop拥有一个线程,负责一个Java NIO选择器的IO事件轮询。
在Netty中,EventLoop反应器和Channel的关系是什么呢?理论上来说,一个EventLoop反应器和NettyChannel通道是一对多的关系:一个反应器可以注册成千上万的通道,如图所示。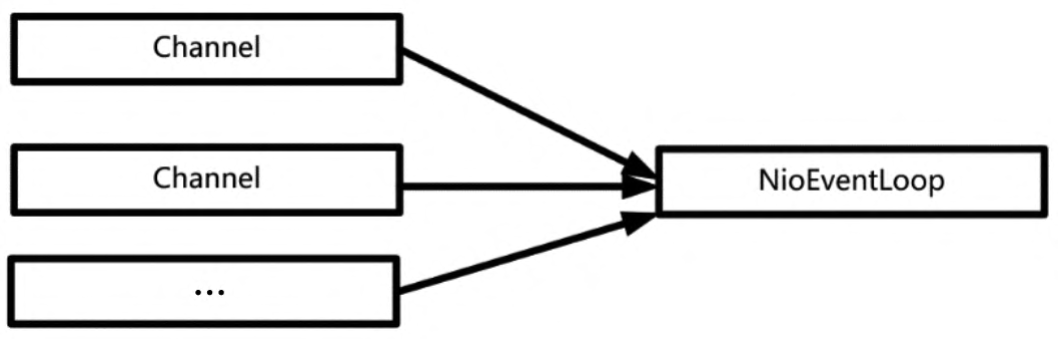
Netty中的Handler
在前面的章节介绍Java NIO的IO事件类型时讲到,可供选择器监控的通道IO事件类型包括以下4种:
可读:SelectionKey.OP_READ。
可写:SelectionKey.OP_WRITE。
连接:SelectionKey.OP_CONNECT。
接收:SelectionKey.OP_ACCEPT。
在Netty中,EventLoop反应器内部有一个线程负责Java NIO选择器的事件的轮询,然后进行对应的事件分发。事件分发(Dispatch)的目标就是Netty的Handler(含用户定义的业务处理器)。
Netty的Handler分为两大类:第一类是ChannelInboundHandler入站处理器;第二类是ChannelOutboundHandler出站处理器,二者都继
承了ChannelHandler处理器接口。有关Handler的接口与继承关系如图所示。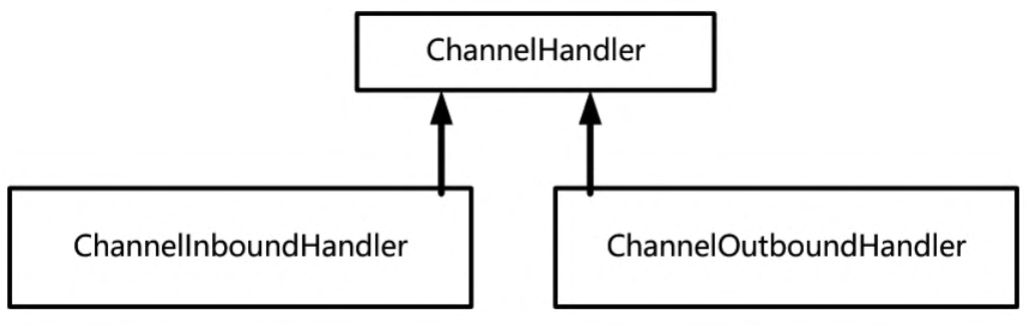
Netty入站处理的流程是什么呢?以底层的Java NIO中的OP_READ输入事件为例:在通道中发生了OP_READ事件后,会被EventLoop查询到,然后分发给ChannelInboundHandler入站处理器,调用对应的入站处理的read()方法。在ChannelInboundHandler入站处理器内部的read()方法具体实现中,可以从通道中读取数据。
Netty中的入站处理触发的方向为从通道触发,ChannelInboundHandler入站处理器负责接收(或者执行)。Netty中的入站处理不仅仅是OP_READ输入事件的处理,还包括从通道底层触发,由Netty通过层层传递,调用ChannelInboundHandler入站处理器进行的其他某个处理。
Netty中的出站处理指的是从ChannelOutboundHandler出站处理器到通道的某次IO操作。例如,在应用程序完成业务处理后,可以通过ChannelOutboundHandler出站处理器将处理的结果写入底层通道。最常用的一个方法就是write()方法,即把数据写入通道。
Netty中的出站处理不仅仅包括Java NIO的OP_WRITE可写事件,还包括Netty自身从处理器到通道方向的其他操作。OP_WRITE可写事件是Java NIO的概念,和Netty的出站处理在概念上不是一个维度,Netty的出站处理是应用层维度的。
无论是入站还是出站,Netty都提供了各自的默认适配器实现:
ChannelInboundHandler的默认实现为ChannelInboundHandlerAdapter(入站处理适配器)。
ChannelOutboundHandler的默认实现为ChannelOutBoundHandlerAdapter(出站处理适配器)。
这两个默认的通道处理适配器分别实现了基本的入站操作和出站操作功能。如果要实现自己的业务处理器,不需要从零开始去实现处理器的接口,只需要继承通道处理适配器即可。
Netty中的Pipeline
在介绍Netty的Pipeline事件处理流水线之前,先梳理一下Netty的Reactor模式实现中各个组件之间的关系:
(1)反应器(或者SubReactor子反应器)和通道之间是一对多的关系:一个反应器可以查询很多个通道的IO事件。
(2)通道和Handler处理器实例之间是多对多的关系:一个通道的IO事件可以被多个Handler实例处理;一个Handler处理器实例也能绑定到很多通道,处理多个通道的IO事件。
问题是:通道和Handler处理器实例之间的绑定关系,Netty是如何组织的呢?
Netty设计了一个特殊的组件,叫作ChannelPipeline(通道流水线)。它像一条管道,将绑定到一个通道的多个Handler处理器实例串联在一起,形成一条流水线。ChannelPipeline的默认实现实际上被设计成一个双向链表。所有的Handler处理器实例被包装成双向链表的节点,被加入到ChannelPipeline中。
一个Netty通道拥有一个ChannelPipeline类型的成员属性,该属性的名称叫作pipeline。
以入站处理为例,每一个来自通道的IO事件都会进入一次ChannelPipeline。在进入第一个Handler处理器后,这个IO事件将按照既定的从前往后次序,在流水线上不断地向后流动,流向下一个Handler处理器。
在向后流动的过程中,会出现3种情况:
(1)如果后面还有其他Handler入站处理器,那么IO事件可以交给下一个Handler处理器向后流动。
(2)如果后面没有其他的入站处理器,就意味着这个IO事件在此次流水线中的处理结束了。
(3)如果在中间需要终止流动,可以选择不将IO事件交给下一个Handler处理器,流水线的执行也被终止了。
Netty的通道流水线与普通的流水线不同,Netty的流水线不是单向的,而是双向的,而普通的流水线基本都是单向的。Netty是这样规定的:入站处理器的执行次序是从前到后,出站处理器的执行次序是从后到前。总之,IO事件在流水线上的执行次序与IO事件的类型是有关系的,如图所示。
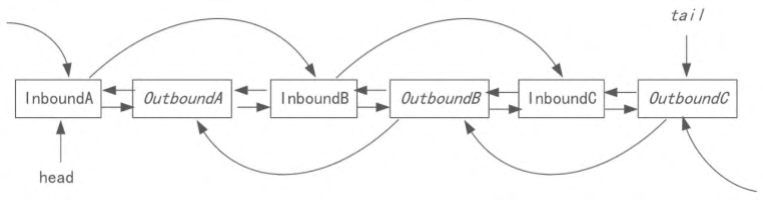
除了流动的方向与IO操作类型有关之外,流动过程中所经过的处理器类型也是与IO操作的类型有关的。入站的IO操作只能从Inbound入站处理器类型的Handler流过;出站的IO操作只能从Outbound出站处理器类型的Handler流过。
至此,在了解完流水线之后,大家应该对Netty中的通道、EventLoop反应器、处理器,以及三者之间的协作关系,有了一个清晰的认知和了解,基本可以动手开发简单的Netty程序了。为了方便开发者,Netty提供了一系列辅助类,用于把上面的三个组件快速组装起来完成一个Netty应用,这个系列的类叫作引导类。服务端的引导类叫作ServerBootstrap类,客户端的引导类叫作Bootstrap类。接下来,为大家详细介绍一下这些能提升开发效率的Bootstrap。
详解Netty Bootstrap
Bootstrap类是Netty提供的一个便利的工厂类,可以通过它来完成Netty的客户端或服务端的Netty组件的组装,以及Netty程序的初始化和启动执行。Netty的官方解释是,完全可以不用这个Bootstrap类,可以一点点去手动创建通道、完成各种设置和启动注册到EventLoop反应器,然后开始事件的轮询和处理,但是这个过程会非常麻烦。通常情况下,使用这个便利的Bootstrap工具类的效率会更高。
在Netty中有两个引导类,分别用于服务器和客户端,如图所示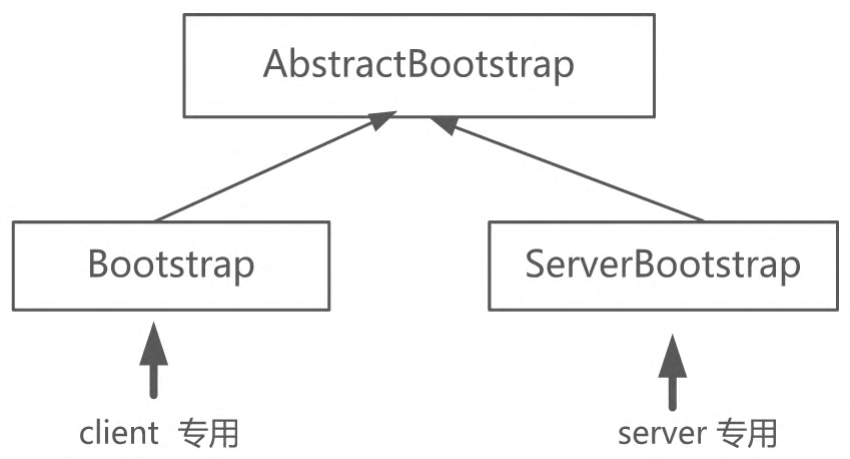
这两个引导类仅是使用的地方不同,它们大致的配置和使用方法都是相同的。下面以ServerBootstrap类作为重点介绍对象。
在介绍ServerBootstrap的服务器启动流程之前,首先介绍一下涉及的两个基础概念:父子通道、EventLoopGroup(事件轮询线程组)。
父子通道
在Netty中,每一个NioSocketChannel通道所封装的都是Java NIO通道,再往下就对应到了操作系统底层的socket文件描述符。理论上来说,操作系统底层的socket文件描述符分为两类:
- 连接监听类型。连接监听类型的socket描述符处于服务端,负责接收客户端的套接字连接;在服务端,一个“连接监听类型”的socket描述符可以接受(Accept)成千上万的传输类的socket文件描述符。
- 数据传输类型。数据传输类的socket描述符负责传输数据。同一条TCP的Socket传输链路在服务器和客户端都分别会有一个与之相对应的数据传输类型的socket文件描述符。
在Netty中,异步非阻塞的服务端监听通道NioServerSocketChannel所封装的Linux底层的文件描述符是“连接监听类型”的socket描述符;异步非阻塞的传输通道NioSocketChannel所封装的Linux的文件描述符是“数据传输类型”的socket描述符。
在Netty中,将有接收关系的监听通道和传输通道叫作父子通道。其中,负责服务器连接监听和接收的监听通道(如NioServerSocketChannel)也叫父通道(Parent Channel),对应于每一个接收到的传输类通道(如NioSocketChannel)也叫子通道(Child Channel)。
EventLoopGroup
在前面介绍Reactor模式的具体实现时,分为单线程实现版本和多线程实现版本。Netty中的Reactor模式实现不是单线程版本的,而是多线程版本的。
实际上,在Netty中一个EventLoop相当于一个子反应器(SubReactor),一个NioEventLoop子反应器拥有了一个事件轮询线程,同时拥有一个Java NIO选择器。
Netty是如何完成多线程版本的Reactor模式实现的呢?答案是使用EventLoopGroup(事件轮询组)。多个EventLoop线程放在一起,可以组成一个EventLoopGroup。反过来说,EventLoopGroup就是一个多线程版本的反应器,其中的单个EventLoop线程对应于一个子反应器(SubReactor)。
Netty的程序开发不会直接使用单个EventLoop(事件轮询器),而是使用EventLoopGroup。EventLoopGroup的构造函数有一个参数,用于指定内部的线程数。在构造器初始化时,会按照传入的线程数量在内部构造多个线程和多个EventLoop子反应器(一个线程对应一个EventLoop子反应器),进行多线程的IO事件查询和分发。
如果使用EventLoopGroup的无参数构造函数,没有传入线程数量或者传入的数量为0,那么EventLoopGroup内部的线程数量到底是多少呢?默认的EventLoopGroup内部线程数量为最大可用的CPU处理器数量的2倍。假设电脑使用的是4核的CPU,那么在内部会启动8个EventLoop线程,相当于8个子反应器实例。
从前文可知,为了及时接收新连接,在服务端,一般有两个独立的反应器,一个负责新连接的监听和接收,另一个负责IO事件轮询和分发,并且两个反应器相互隔离。对应到Netty服务器程序中,则需要设置两个EventLoopGroup,一个组负责新连接的监听和接受,另外一个组负责IO传输事件的轮询与分发,两个轮询组的职责具体如下:
(1)负责新连接的监听和接收的EventLoopGroup中的反应器完成查询通道的新连接IO事件查询。这些反应器有点像负责招工的包工头,因此,该轮询组可以形象地称为“包工头”(Boss)轮询组。
(2)负责IO事件轮询和分发的反应器完成查询所有子通道的IO事件,并且执行对应的Handler处理器完成IO处理——例如数据的输入和输出(有点儿像搬砖),这个轮询组可以形象地称为“工人”(Worker)轮询组。
Netty的EventLoopGroup与EventLoop之间、EventLoop与Channel之间的关系如图所示。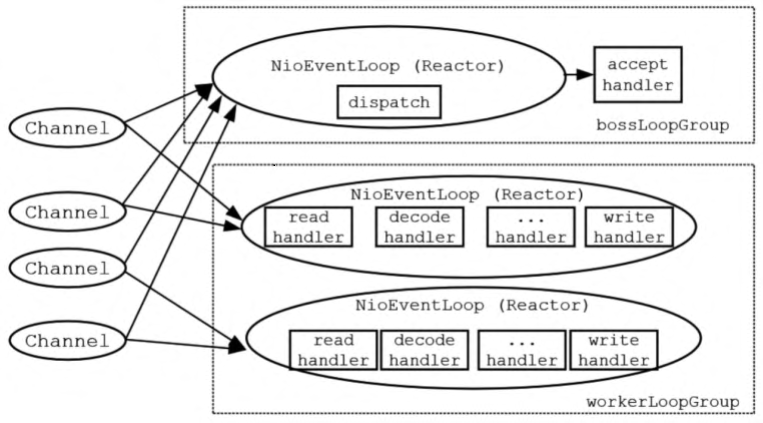
至此,介绍完了两个重要的基础概念:父子通道与EventLoopGroup。有了这些基础知识作为铺垫,接下来可以正式介绍ServerBootstrap的启动流程了。
Bootstrap启动流程
Bootstrap的启动流程也就是Netty组件的组装、配置,以及Netty服务器或者客户端的启动流程。在本节中对启动流程进行了梳理,大致分成8个步骤。
第1步:创建反应器轮询组,并设置到ServerBootstrap引导类实例
第2步:设置通道的IO类型。Netty不止支持Java NIO,也支持阻塞式的OIO
第3步:设置监听端口。
第4步:设置传输通道的配置选项
第5步:装配子通道的Pipeline。每一个通道都用一条ChannelPipeline流水线,它的内部有一个双向的链表。装配流水线的方式是:将业务处理器ChannelHandler实例包装之后加入双向链表中
第6步:开始绑定服务器新连接的监听端口
第7步:自我阻塞,直到监听通道关闭
第8步:关闭EventLoopGroup,关闭反应器轮询组,同时会关闭内部的子反应器线程,也会关闭内部的选择器、内部的轮询线程以及负责查询的所有子通道。在子通道关闭后,会释放掉底层的资源,如Socket文件描述符等。
ChannelOption
无论是对于NioServerSocketChannel父通道类型还是对于NioSocketChannel子通道类型,都可以设置一系列的ChannelOption(通道选项)。ChannelOption类中定义了一系列选项,下面介绍一些常见的选项。
- SO_RCVBUF和SO_SNDBUF
- TCP_NODELAY
- SO_KEEPALIVE
- SO_REUSEADDR
- SO_LINGER
- SO_BACKLOG
- SO_BROADCAST:此为TCP传输选项,表示设置为广播模式。
详解Channel
Channel的主要成员和方法
通道是Netty的核心概念之一,代表网络连接,由它负责同对端进行网络通信,既可以写入数据到对端,也可以从对端读取数据。
EmbeddedChannel(专用通道)
在Netty的实际开发中,底层通信传输的基础工作Netty已经替大家完成。实际上,更多的工作是设计和开发ChannelHandler业务处理器。处理器开发完成后,需要投入单元测试。一般单元测试的大致流程是:先将Handler业务处理器加入到通道的Pipeline流水线中,接下来先后启动Netty服务器、客户端程序,相互发送消息,测试业务处理器的效果。这些复杂的工序存在一个问题:如果每开发一个业务处理器都进行服务器和客户端的重复启动,那么整个的过程是非常烦琐和浪费时间的。如何解决这种徒劳、低效的重复工作呢?Netty提供了一个专用通道,即EmbeddedChannel(嵌入式通道)。
EmbeddedChannel仅仅是模拟入站与出站的操作,底层不进行实际传输,不需要启动Netty服务器和客户端。除了不进行传输之外,EmbeddedChannel的其他事件机制和处理流程和真正的传输通道是一模一样的。因此,使用EmbeddedChannel,开发人员可以在单元测试用例中方便、快速地进行hannelHandler业务处理器的单元测试。
为了模拟数据的发送和接收,EmbeddedChannel提供了一组专门的方法,具体如表所示。
最为重要的两个方法为writeInbound()和writeOutbound()方法。
详解Handler
在Reactor经典模型中,反应器查询到IO事件后会分发到Handler业务处理器,由Handler完成IO操作和业务处理。
整个IO处理操作环节大致包括从通道读数据包、数据包解码、业务处理、目标数据编码、把数据包写到通道,然后由通道发送到对端,如图所示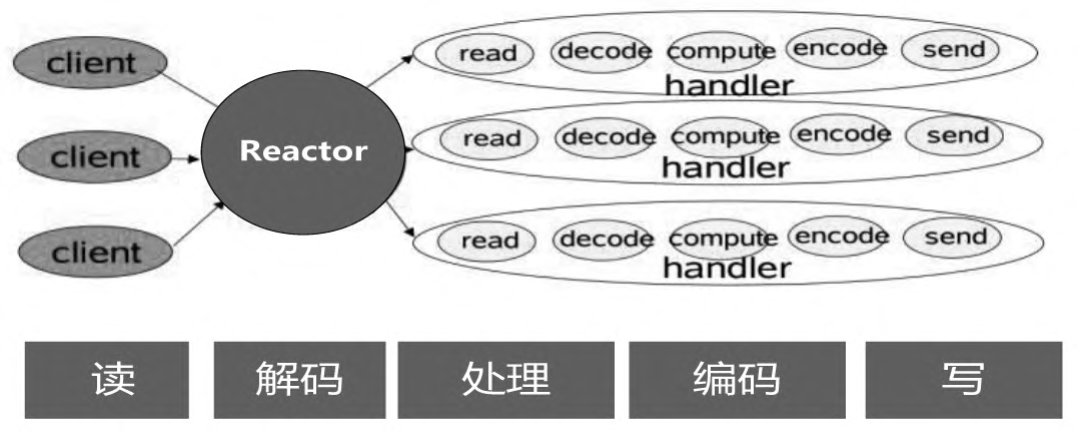
整个的IO处理操作环节的前后两个环节(包括从通道读数据包和由通道发送到对端),由Netty的底层负责完成,不需要用户程序负责。
用户程序主要涉及的Handler环节为数据包解码、业务处理、目标数据编码、把数据包写到通道中。
前面已经介绍过,从应用程序开发人员的角度来看有入站和出站两种类型操作。
- 入站处理触发的方向为自底向上,从Netty的内部(如通道)到ChannelInboundHandler入站处理器。
- 出站处理触发的方向为自顶向下,从ChannelOutboundHandler出站处理器到Netty的内部(如通道)。
按照这种触发方向来区分,IO处理操作环节前面的数据包解码、业务处理两个环节属于入站处理器的工作;后面目标数据编码、把数据包写到通道中两个环节属于出站处理器的工作。
ChannelInboundHandler入站处理器
当对端数据入站到Netty通道时,Netty将触发ChannelInboundHandler入站处理器所对应的入站API,进行入站操作处理。
ChannelOutboundHandler出站处理器
当业务处理完成后,需要操作Java NIO底层通道时,通过一系列的ChannelOutboundHandler出站处理器完成Netty通道到底层通道的操作,比如建立底层连接、断开底层连接、写入底层Java NIO通道等。ChannelOutboundHandler接口定义了大部分的出站操作。
ChannelInitializer通道初始化处理器
在前面已经讲到,Channel和Handler业务处理器的关系是:一条Netty的通道拥有一条Handler业务处理器流水线,负责装配自己的Handler业务处理器。装配Handler的工作发生在通道开始工作之前。现在的问题是:如果向流水线中装配业务处理器呢?这就得借助通道的初始化处理器——ChannelInitializer。
详解Pipeline
前面讲到,一条Netty通道需要很多业务处理器来处理业务。每条通道内部都有一条流水线(Pipeline)将Handler装配起来。Netty的业务处理器流水线ChannelPipeline是基于责任链设计模式(Chain of Responsibility)来设计的,内部是一个双向链表结构,能够支持动态地添加和删除业务处理器。
Pipeline入站处理流程
Pipeline出站处理流程
ChannelHandlerContext
在Netty的设计中Handler是无状态的,不保存和Channel有关的信息。Handler的目标是将自己的处理逻辑做得很通用,可以给不同的Channel使用。与Handler不同的是,Pipeline是有状态的,保存了Channel的关系。于是,Handler和Pipeline之间需要一个中间角色将它们联系起来。这个中间角色是谁呢?ChannelHandlerContext(通道处理器上下文)!
不管我们定义的是哪种类型的业务处理器,最终它们都是以双向链表的方式保存在流水线中。这里流水线的节点类型并不是前面的业务处理器基类,而是其包装类型ChannelHandlerContext类。当业务处理器被添加到流水线中时会为其专门创建一个ChannelHandlerContext实例,主要封装了hannelHandler(通道处理器)和ChannelPipeline(通道流水线)之间的关联关系。所以,流水线ChannelPipeline中的双向链接实质是一个由hannelHandlerContext
组成的双向链表。作为Context的成员,无状态的Handler关联在ChannelHandlerContext中。
ChannelPipeline流水线的示意图大致如图所示。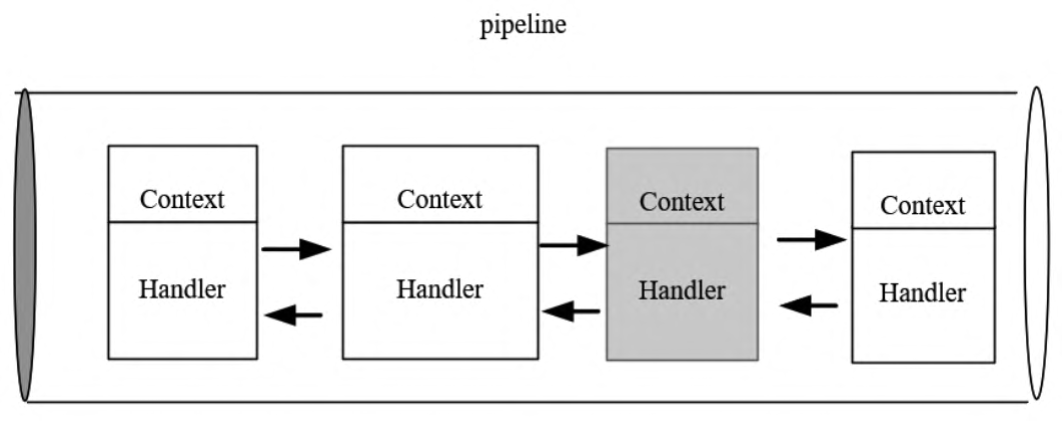
ChannelHandlerContext中包含了许多方法,主要可以分为两类:
第一类是获取上下文所关联的Netty组件实例,如所关联的通道、所关联的流水线、上下文内部Handler业务处理器实例等;
第二类是入站和出站处理方法。
在Channel、ChannelPipeline、ChannelHandlerContext三个类中,都存在同样的出站和入站处理方法,这些出现在不同的类中的相同方法,功能有何不同呢?
如果通过Channel或ChannelPipeline的实例来调用这些出站和入站处理方法,它们就会在整条流水线中传播。如果是通过ChannelHandlerContext调用出站和入站处理方法,就只会从当前的节点开始往同类型的下一站处理器传播,而不是在整条流水线从头至尾进行完整的传播。
总结一下Channel、Handler、ChannelHandlerContext三者的关系:Channel拥有一条ChannelPipeline,每一个流水线节点为一个
ChannelHandlerContext上下文对象,每一个上下文中包裹了一个ChannelHandler。在ChannelHandler的入站/出站处理方法中,Netty会传递一个Context实例作为实际参数。处理器中的回调代码可以通过Context实参,在业务处理过程中去获取ChannelPipeline实例或者Channel实例。
HeadContext与TailContext
通道流水线在没有加入任何处理器之前装配了两个默认的处理器上下文:一个头部上下文HeadContext,一个尾部上下文TailContext。pipeline的创建、初始化除了保存一些必要的属性外,核心就在于创建了HeadContext头节点和TailContext尾节点。
每个流水线中双向链表结构从一开始就存在了HeadContext和TailContext两个节点,后面添加的处理器上下文节点都添加在HeadContext实例和TailContext实例之间。在添加了一些必要的解码器、业务处理器、编码器之后,一条流水线的结构大致如图所示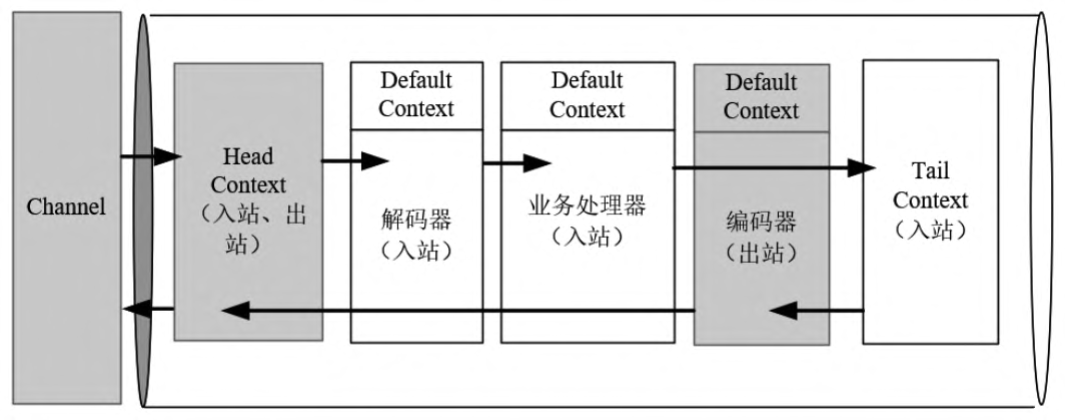
流水线尾部的TailContext不仅仅是一个上下文类,还是一个入站处理器类,实现了所有入站处理回调方法,这些回调实现的主要工作基本上都是有关收尾处理的,如释放缓冲区对象、完成异常处理等。
Pipeline入站和出站的双向链接操作
截断流水线的入站处理传播过程
在流水线上热插拔Handler
详解ByteBuf
Netty提供了ByteBuf缓冲区组件来替代Java NIO的ByteBuffer缓冲区组件,以便更加快捷和高效地操纵内存缓冲区。
### ByteBuf的优势
与Java NIO的ByteBuffer相比,ByteBuf的优势如下:
- Pooling(池化),减少了内存复制和GC,提升了效率。
- 复合缓冲区类型,支持零复制。
- 不需要调用flip()方法去切换读/写模式。
- 可扩展性好。
- 可以自定义缓冲区类型。
- 读取和写入索引分开。
- 方法的链式调用。
- 可以进行引用计数,方便重复使用。
ByteBuf的组成部分
ByteBuf是一个字节容器,内部是一个字节数组。从逻辑上来分,字节容器内部可以分为四个部分,具体如图所示。
第一部分是已用字节,表示已经使用完的废弃的无效字节;
第二部分是可读字节,这部分数据是ByteBuf保存的有效数据,从ByteBuf中读取的数据都来自这一部分;
第三部分是可写字节,写入ByteBuf的数据都会写到这一部分中;
第四部分是可扩容字节,表示的是该ByteBuf最多还能扩容的大小。
ByteBuf的重要属性
ByteBuf通过三个整数类型的属性有效地区分可读数据和可写数据的索引,使得读写之间相互没有冲突。这三个属性定义在AbstractByteBuf抽象类中,分别是:
- readerIndex(读指针):指示读取的起始位置。每读取一个字节,readerIndex自动增加1。一旦readerIndex与writerIndex相等,则表示ByteBuf不可读了。
- writerIndex(写指针):指示写入的起始位置。每写一个字节,writerIndex自动增加1。一旦增加到writerIndex与capacity()容量相等,则表示ByteBuf不可写了。注意,capacity()是一个成员方法,不是一个成员属性,表示ByteBuf中可以写入的容量,而且它的值不一定是最大容量值。
- maxCapacity(最大容量):表示ByteBuf可以扩容的最大容量。当向ByteBuf写数据的时候,如果容量不足,可以进行扩容。扩容的最大限度由maxCapacity来设定,超过maxCapacity就会报错。
ByteBuf的这三个重要属性的含义如图所示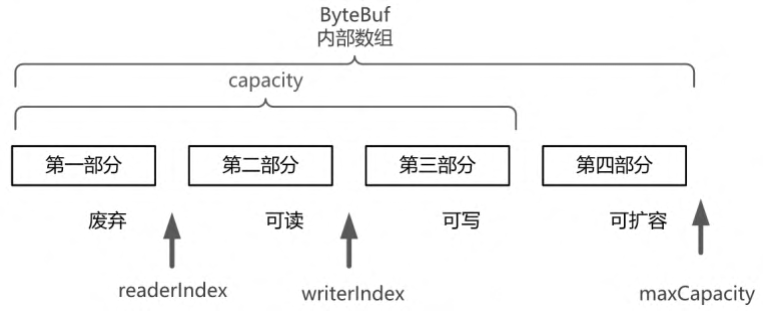
ByteBuf的方法
ByteBuf的方法大致可以分为三组。
第一组:容量系列
- capacity():表示ByteBuf的容量,是废弃的字节数、可读字节数和可写字节数之和。
- maxCapacity():表示ByteBuf能够容纳的最大字节数。当向ByteBuf中写数据的时候,如果发现容量不足,则进行扩容,直至扩容到maxCapacity设定的上限。
第二组:写入系列 - isWritable():表示ByteBuf是否可写。如果capacity()容量大于writerIndex指针的位置,则表示可写,否则为不可写。注意:isWritable()返回false并不代表不能再往ByteBuf中写数据了。如果Netty发现往ByteBuf中写数据写不进去,就会自动扩容ByteBuf。
- writableBytes():取得可写入的字节数,它的值等于容量capacity()减去writerIndex。
- maxWritableBytes():取得最大的可写字节数,它的值等于最大容量maxCapacity减去writerIndex。
- writeBytes(byte[] src):把入参src字节数组中的数据全部写到ByteBuf。这是最为常用的一个方法。
- writeTYPE(TYPE value):写入基础数据类型的数据。TYPE表示基础数据类型,这里包含了八种大基础数据类型:writeByte()、writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble()。
- setTYPE(TYPE value):基础数据类型的设置,不改变writerIndex指针值。TYPE表示基础数据类型这里包含了八大基础数据类型的设置,即setByte()、setBoolean()、setChar()、setShort()、setInt()、setLong()、setFloat()、setDouble()。setTYPE系列与writeTYPE系列的不同点是setTYPE系列不改变写指针writerIndex的值,writeTYPE系列会改变写指针writerIndex的值。
- markWriterIndex()与resetWriterIndex():前一个方法表示把当前的写指针writerIndex属性的值保存在markedWriterIndex标记属性中;后一个方法表示把之前保存的markedWriterIndex的值恢复到写指针writerIndex属性中。这两个方法都用到了标记属性markedWriterIndex,相当于一个写指针的暂存属性。
第三组:读取系列 - isReadable():返回ByteBuf是否可读。如果writerIndex指针的值大于readerIndex指针的值,则表示可读,否则为不可读。
- readableBytes():返回表示ByteBuf当前可读取的字节数,它的值等于writerIndex减去readerIndex。
- readBytes(byte[] dst):将数据从ByteBuf读取到dst目标字节数组中,这里dst字节数组的大小通常等于readableBytes()可读字节数。这个方法也是最为常用的方法之一。
- readTYPE():读取基础数据类型。可以读取八大基础数据类型:readByte()、readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble()。
- getTYPE():读取基础数据类型,并且不改变readerIndex读指针的值,具体为getByte()、getBoolean()、getChar()、getShort()、getInt()、getLong()、getFloat()、getDouble()。getTYPE系列与readTYPE系列的不同点是getTYPE系列不会改变读指针readerIndex的值,readTYPE系列会改变读指针readerIndex的值。
- markReaderIndex()与resetReaderIndex():前一种方法表示把当前的读指针readerIndex保存在markedReaderIndex属性中;后一种方法表示把保存在markedReaderIndex属性的值恢复到读指针readerIndex中。markedReaderIndex属性定义在AbstractByteBuf抽象基类中,是一个标记属性,相当于一个读指针的暂存属性。
ByteBuf的引用计数
JVM中使用“计数器”(一种GC算法)来标记对象是否“不可达”进而收回,Netty也使用了这种手段来对ByteBuf的引用进行计数。(注:GC是Garbage Collection的缩写,即Java中的垃圾回收机制。)Netty的ByteBuf的内存回收工作是通过引用计数方式管理的。
Netty之所以采用“计数器”来追踪ByteBuf的生命周期,一是能对Pooled ByteBuf进行支持,二是能够尽快“发现”那些可以回收的ByteBuf(非Pooled),以便提升ByteBuf的分配和销毁的效率。
什么是池化(Pooled)的ByteBuf缓冲区呢?从Netty 4版本开始,新增了ByteBuf的池化机制,即创建一个缓冲区对象池,将没有被引用的ByteBuf对象放入对象缓存池中,需要时重新从对象缓存池中取出,而不需要重新创建。
在通信程序的数据传输过程中,Buffer缓冲区实例会被频繁创建、使用、释放,从而频繁创建对象、内存分配、释放内存,这样会导致系统的开销大、性能低。如何提升性能、提高Buffer实例的使用率呢?池化ByteBuf是一种非常有效的方式。
ByteBuf引用计数的大致规则如下:在默认情况下,当创建完一个ByteBuf时,引用计数为1;每次调用retain()方法,引用计数加1;每次调用release()方法,引用计数减1;如果引用为0,再次访问这个ByteBuf对象,将会抛出异常;如果引用为0,表示这个ByteBuf没有哪个进程引用,它占用的内存需要回收。
ByteBuf的分配器
ByteBuf缓冲区的类型
ByteBuf的自动创建与自动释放
ByteBuf浅层复制的高级使用方式
Netty的零拷贝
大部分场景下,在Netty接收和发送ByteBuffer的过程中会使用直接内存进行Socket通道读写,使用JVM的堆内存进行业务处理,会涉及直接内存、堆内存之间的数据复制。内存的数据复制其实是效率非常低的,Netty提供了多种方法,以帮助应用程序减少内存的复制。
Netty的零拷贝(Zero-Copy)主要体现在五个方面:
(1)Netty提供CompositeByteBuf组合缓冲区类,可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各个ByteBuf之间的拷贝。
(2)Netty提供了ByteBuf的浅层复制操作(slice、duplicate),可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf,避免内存的拷贝。
(3)在使用Netty进行文件传输时,可以调用FileRegion包装的transferTo()方法直接将文件缓冲区的数据发送到目标通道,避免普通的循环读取文件数据和写入通道所导致的内存拷贝问题。
(4)在将一个byte数组转换为一个ByteBuf对象的场景下,Netty提供了一系列的包装类,避免了转换过程中的内存拷贝。
(5)如果通道接收和发送ByteBuf都使用直接内存进行Socket读写,就不需要进行缓冲区的二次拷贝。如果使用JVM的堆内存进行Socket读写,那么JVM会先将堆内存Buffer拷贝一份到直接内存再写入Socket中,相比于使用直接内存,这种情况在发送过程中会多出一次缓冲区的内存拷贝。所以,在发送ByteBuffer到Socket时,尽量使用直接内存而不是JVM堆内存。
Netty中的零拷贝和操作系统层面上的零拷贝是有区别的,不能混淆,我们所说的Netty零拷贝完全是基于Java层面或者说用户空间的,它更多的是偏向于应用中的数据操作优化,而不是系统层面的操作优化。
通过CompositeByteBuf实现零拷贝
通过wrap操作实现零拷贝
EchoServer的实战案例
Decoder与Encoder核心组件
Netty从底层Java通道读取ByteBuf二进制数据,传入Netty通道的流水线,随后开始入站处理。在入站处理过程中,需要将ByteBuf二进制类型解码成Java POJO对象。这个解码过程可以通过Netty的Decoder(解码器)去完成。
在出站处理过程中,业务处理后的结果(出站数据)需要从某个Java POJO对象编码为最终的ByteBuf二进制数据,然后通过底层Java通道发送到对端。在编码过程中,需要用到Netty的Encoder(编码器)去完成数据的编码工作。
本章专门为大家解读Netty非常核心的组件:编码器和解码器
Decoder原理与实战
什么是Netty的解码器呢?
首先,它是一个InBound入站处理器,负责处理“入站数据”。
其次,它能将上一站Inbound入站处理器传过来的输入(Input)数据进行解码或者格式转换,然后发送到下一站Inbound入站处理器。
一个标准的解码器的职责为:将输入类型为ByteBuf的数据进行解码,输出一个一个的Java POJO对象。Netty内置了ByteToMessageDecoder解码器。
Netty中的解码器都是Inbound入站处理器类型,都直接或者间接地实现了入站处理的超级接口ChannelInboundHandler。
ByteToMessageDecoder解码器处理流程
自定义Byte2IntegerDecoder整数解码器
ReplayingDecoder解码器
MessageToMessageDecoder解码器
常用的内置Decoder
LineBasedFrameDecoder解码器
DelimiterBasedFrameDecoder解码器
LengthFieldBasedFrameDecoder解码器
Encoder原理与实战
在Netty的业务处理完成后,业务处理的结果往往是某个Java POJO对象需要编码成最终的ByteBuf二进制类型,通过流水线写入底层的Java通道,这就需要用到Encoder(编码器)。
在Netty中,什么叫编码器?首先,编码器是一个Outbound出站处理器,负责处理“出站”数据;其次,编码器将上一站Outbound出站处理器传过来的输入(Input)数据进行编码或者格式转换,然后传递到下一站ChannelOutboundHandler出站处理器。
编码器与解码器相呼应,Netty中的编码器负责将“出站”的某种Java POJO对象编码成二进制ByteBuf,或者转换成另一种Java POJO对象。
编码器是ChannelOutboundHandler的具体实现类。一个编码器将出站对象编码之后,数据将被传递到下一个ChannelOutboundHandler出站处理器进行后面的出站处理。
由于最后只有ByteBuf才能写入通道中,因此可以肯定通道流水线上装配的第一个编码器一定是把数据编码成了ByteBuf类型。为什么编码成的最终ByteBuf类型数据包的编码器是在流水线的头部,而不是在流水线的尾部呢?原因很简单:出站处理的顺序是从后向前的。
MessageToByteEncoder编码器
MessageToMessageEncoder编码器
解码器和编码器的结合
在实际的开发中,由于数据的入站和出站关系紧密,因此编码器和解码器的关系很紧密。编码和解码更是一种紧密的、相互配套的关系。在流水线处理时,数据的流动往往一进一出,进来时解码,出去时编码。所以,在同一个流水线上,加了某种编码逻辑,常常需要加上一个相对应的解码逻辑。
前面讲到编码器和解码器是分开实现的。例如,通过继承ByteToMessageDecoder基类或者其子类,完成ByteBuf数据包到POJO的解码工作;通过继承基类MessageToByteEncoder或者其子类,完成POJO到ByteBuf数据包的编码工作。总之,具有相反逻辑的编码器和解码器分开实现在两个不同的类中,导致的一个结果是相互配套的编码器和解码器在加入通道的流水线时常常需要分两次添加。
现在的问题是:具有相互配套逻辑的编码器和解码器能否放在同一个类中呢?答案是肯定的,这需要用到Netty的新类型—— Codec(编解码器)。
ByteToMessageCodec编解码器
CombinedChannelDuplexHandler组合器
序列化与反序列化:JSON和Protobuf
我们在开发一些远程过程调用(RPC)的程序时通常会涉及对象的序列化/反序列化问题,例如一个Person对象从客户端通过TCP方式发送到服务端。由于TCP(或者UDP等类似低层协议)只能发送字节流,因此需要应用层将Java POJO对象“序列化”成字节流,发送过去之后,数据接收端再将字节流“反序列化”成Java POJO对象即可。
“序列化”和“反序列化”一定会涉及POJO的编码和格式化(Encoding & Format),目前我们可选择的编码方式有:
- 使用JSON。将Java POJO对象转换成JSON结构化字符串。基于HTTP,在Web应用、移动开发方面等,这种是常用的编码方式,因为JSON的可读性较强。这种方式的缺点是它的性能稍差。
- 基于XML。和JSON一样,数据在序列化成字节流之前需要转换成字符串。这种方式的可读性强,性能差,异构系统、Open API类型的应用中常用。
- 使用Java内置的编码和序列化机制,可移植性强,性能稍差,无法跨平台(语言)。
- 开源的二进制的序列化/反序列化框架,例如Apache Avro、Apache Thrift、Protobuf等。前面的两个框架和Protobuf相比,性能非常接近,而且设计原理如出一辙。其中,Avro在大数据存储(RPC数据交换、本地存储)时比较常用;Thrift的亮点在于内置了RPC机制,所以在开发一些RPC交互式应用时,客户端和服务端的开发与部署都非常简单。
如何选择序列化/反序列化框架呢?
评价一个序列化框架的优缺点大概从两方面着手:
(1)结果数据大小:原则上说,序列化后的数据尺寸越小,传输效率越高。
(2)结构复杂度:会影响序列化/反序列化的效率,结构越复杂越耗时。
理论上来说,对于对性能要求不是太高的服务器程序,可以选择JSON文本格式的序列化框架;对于性能要求比较高的服务器程序,应该选择传输效率更高的二进制序列化框架,建议是Protobuf。
Protobuf是一个高性能、易扩展的序列化框架,性能比较高,其性能的有关数据可以参看官方文档。Protobuf本身非常简单,易于开发,而且结合Netty框架,可以非常便捷地实现一个通信应用程序。反过来,Netty也提供了相应的编解码器,为Protobuf解决了有关Socket通信中“半包、粘包”等问题。
无论是使用JSON、Protobuf还是其他的传输协议,我们必须保证在数据包的反序列化之前,接收端的ByteBuf二进制数据包一定是一个完整的应用层二进制包,不能是一个半包或者粘包,这就涉及通信过程中的拆包技术。
详解粘包和拆包
使用JSON协议通信
使用Protobuf协议通信
Protobuf(Protocol Buffer)是Google提出的一种数据交换格式,是一套类似JSON或者XML的数据传输格式和规范,用于不同应用或进程之间的通信。Protobuf具有以下特点:
(1)语言无关,平台无关
Protobuf支持Java、C++、Python、JavaScript等多种语言,支持跨多个平台。
(2)高效
比XML更小(310倍)、更快(20100倍)、更为简单。
(3)扩展性、兼容性好
可以更新数据结构,而不影响和破坏原有的旧程序。
Protobuf既独立于语言又独立于平台。Google官方提供了多种语言的实现:Java、C#、C++、GO、JavaScript和Python。Protobuf的编码过程为:使用预先定义的Message数据结构将实际的传输数据进行打包,然后编码成二进制的码流进行传输或者存储。Protobuf的解码过程刚好与编码过程相反:将二进制码流解码成Protobuf自己定义的Message结构的POJO实例。
与JSON、XML相比,Protobuf算是后起之秀,只是Protobuf更加适合于高性能、快速响应的数据传输应用场景。Protobuf数据包是一种二进制格式,相对于文本格式的数据交换(JSON、XML)来说,速度要快很多。Protobuf优异的性能使得它更加适用于分布式应用场景下的数据通信或者异构环境下的数据交换。
JSON、XML是文本格式,数据具有可读性;Protobuf是二进制数据格式,数据本身不具有可读性,只有反序列化之后才能得到真正可读的数据。正因为Protobuf是二进制数据格式,所以数据序列化之后体积相比JSON和XML要小,更加适合网络传输。
总体来说,在一个需要大量数据传输的应用场景中,数据量很大,选择Protobuf可以明显地减少传输的数据量和提升网络IO的速度。对于打造一款高性能的通信服务器来说,Protobuf传输协议是最高性能的传输协议之一。微信的消息传输就采用了Protobuf协议。
Protobuf编解码的实战案例
详解Protobuf协议语法
在Protobuf中,通信协议的格式是通过proto文件定义的。一个proto文件有两大组成部分:头部声明、消息结构体的定义。头部声明部分主要包含了协议的版本、包名、特定语言的选项设置等;消息结构体部分可以定义一个或者多个消息结构体。
在Java中,当用Protobuf编译器(如protoc3.6.1.exe)来编译.proto文件时,编译器将生成Java语言的POJO消息类和Builder构造者类。通过POJO消息类和Builder构造者,Java程序可以很容易地操作在proto文件中定义的消息和字段,包括获取、设置字段值,将消息序列化到一个输出流中(序列化),以及从一个输入流中解析消息(反序列化)。
基于Netty单体IM系统的开发实战
自定义Protobuf编解码器
IM的登录流程
客户端的登录处理的实战案例
服务端的登录响应的实战案例
详解Session服务器会话
点对点单聊的实战案例
详解心跳检测
<第5-8章>