Java编程之Java高并发核心编程学习之第13-15章ZooKeeper-Redis-CrazyIM
《Java高并发核心编程》卷1:内容介绍
第1~4章从操作系统的底层原理开始,浅显易懂地揭秘高并发IO的底层原理,并介绍如何让单体Java应用支持百万级的高并发;从传统的阻塞式OIO开始,细致地解析Reactor高性能模式,介绍高性能网络开发的基础知识。这些非常底层的原理知识和基础知识非常重要,是开发过程中解决Java实际问题必不可少的。
第5~8章重点讲解Netty。目前Netty是高性能通信框架皇冠上当之无愧的明珠,是支撑其他众多著名的高并发、分布式、大数据框架底层的框架。这几章从Reactor模式入手,以“四两拨千斤”的方式为大家介绍Netty原理。同时,还将介绍如何通过Netty来解决网络编程中的重点难题,如Protobuf序列化问题、半包问题等。
第9~12章从TCP、HTTP入手,介绍客户端与服务端、服务端与服务端之间的高性能HTTP通信和WebSocket通信。这几章深入浅出地介绍TCP、HTTP、WebSocket三大常用的协议,以及如何基于Netty实现HTTP、WebSocket高性能通信。
第13章对ZooKeeper进行详细的介绍。除了全面地介绍Curator API之外,还从实战的角度出发介绍如何使用ZooKeeper设计分布式ID生成器,并对重要的SnowFlake算法进行详细的介绍。另外,还结合小故事以图文并茂的方式浅显易懂地介绍分布式锁的基本原理。
第14章从实战开发层面对Redis进行介绍,详细介绍Redis的5种数据类型、客户端操作指令、Jedis Java API。另外,还通过spring-data-redis来完成数据分布式缓存的实战案例,详尽地介绍Spring的缓存注解以及涉及的SpEL表达式语言。
第15章通过CrazyIM项目为大家介绍一个亿级流量的高并发IM系统模型,这个高并发架构的系统模型不仅仅限于IM系统,通过简单的调整和适配就可以应用于当前主流的Java后台系统。
《Java高并发核心编程》卷1:第13章ZooKeeper分布式协调
高并发系统为了应对流量增长需要进行节点的横向扩展,所以高并发系统往往都是分布式系统。高并发系统基本都需要进行节点与节点之间的配合协调,这就需要用到分布式协调中间件(如ZooKeeper)。
ZooKeeper(本书简称ZK)是Hadoop的正式子项目,是一个针对大型分布式系统的可靠协调系统,提供的功能包括配置维护、名字服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂、易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。ZooKeeper在实际生产环境中应用非常广泛,比如SOA的服务监控系统,大数据基础平台Hadoop、Spark的分布式调度系统。
ZooKeeper伪集群安装和配置
ZooKeeper的运行一般是集群模式,而不是单节点模式,现在我们开始使用一台机器来搭建一个ZooKeeper学习集群。由于没有多余的服务器,因此这里将三个ZooKeeper节点都安装到一台机器上,故称之为“伪集群模式”。
伪集群模式只便于开发、单元测试,不能用于生产环境。实际上,伪集群模式下的安装和配置与生产环境下的步骤差不多
使用ZooKeeper进行分布式存储
详解ZooKeeper存储模型
ZooKeeper的存储模型非常简单,和Linux的文件系统非常类似。简单地说,ZooKeeper的存储模型是一棵以”/“为根节点的树,存储模型中的每一个节点叫作ZNode(ZooKeeper Node)节点。所有的ZNode节点通过树的目录结构按照层次关系组织在一起,构成一棵ZNode树。
每个ZNode节点都用一个完整路径来唯一标识,完整路径以”/“(斜杠)符号分隔,而且每个ZNode节点都有父节点(根节点除外)。例如,”/foo/bar”表示一个ZNode节点,它的父节点为”/foo”节点,祖父节点的路径为”/“。”/“节点是ZNode树的根节点,没有父节点。
通过ZNode树,ZooKeeper提供一个多层级的树状命名空间。该树状命名空间与文件目录系统中的目录树有所不同,这些ZNode节点可以保存二进制负载数据(Payload)。文件系统目录树中的目录只能存放路径信息,而不能存放负载数据。
一个节点的负载数据(Payload)能放多少二进制数据呢?
ZooKeeper为了保证高吞吐和低延迟,整个树状的目录结构全部都放在内存中。与硬盘和其他的外存设备相比,机器的内存比较有限,使得ZooKeeper的目录结构不能用于存放大量的数据。ZooKeeper官方的要求是,每个节点存放的Payload负载数据的上限仅仅为1MB。
ZooKeeper应用开发实战
ZooKeeper应用开发主要通过Java客户端API去连接和操作ZooKeeper集群。可以供选择的Java客户端API有:
(1)ZooKeeper官方的Java客户端API。
(2)第三方的Java客户端API。
ZooKeeper官方的客户端API提供了基本的操作,比如创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。对于实际开发来说,ZooKeeper官方API有一些不足之处,具体如下:
(1)ZooKeeper的Watcher监测是一次性的,每次触发之后都需要重新进行注册。
(2)Session超时之后没有实现重连机制。
(3)异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道该如何处理这些异常信息。
(4)只提供了简单的byte[]数组类型的接口,没有提供Java POJO级别的序列化数据处理接口。
(5)创建节点时如果节点存在抛出异常,就需要自行检查节点是否存在。
(6)无法实现级联删除。
总之,ZooKeeper官方API的功能比较简单,在实际开发过程中比较笨重,一般不推荐使用。可以使用的第三方开源客户端API主要有ZkClient和Curator。
ZooKeeper节点有四种类型,具体定义和联系如下:
(1)持久化节点(PERSISTENT)。所谓持久节点,是指在节点创建后就一直存在,直到有删除操作来主动清除这个节点。持久节点的生命周期是永久有效的,不会因为创建该节点的客户端会话失效而消失。
(2)持久化顺序节点(PERSISTENT_SEQUENTIAL)。这类节点的生命周期和持久节点是一致的。额外的特性是,持久化顺序节点的每个父节点会为它的第一级子节点维护一份次序,会记录每个子节点创建的先后顺序。如果在创建子节点的时候可以设置这个属性,那么在创建节点的过程中ZK会自动为给定节点名加上一个表示次序的数字后缀作为新的节点名。这个次序后缀的最大值可以是整数类型的最大值。比如,在创建持久化顺序节点的时候只需要传入节点
“/test_”,之后ZooKeeper就会自动给“test_”后面补充数字次序。
(3)临时节点(EPHEMERAL)。与持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提到的是会话失效,而非连接断开。这里还要注意一件事,就是当客户端会话失效后,所产生的临时节点不是一下子就消失,要过一段时间,大概是10秒以内。可以试着在本机操作生成节点,在服务端用命令来查看当前的节点数目,当客户端停下来后,我们就会发现临时节点短时间之内还在。另外,在临时节点下面不能创建子节点。
(4)临时顺序节点(EPHEMERAL_SEQUENTIAL)。此节点属于临时节点,不过带有顺序编号,客户端会话结束节点就会消失。
分布式命名服务实战
命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的次序维护能力为分布式系统中的资源命名。
典型的分布式命名服务场景如下。
1. 分布式API目录
为分布式系统中各种API接口服务的名称、链接地址提供类似JNDI(Java命名和目录接口)中文件系统的能力。借助于ZooKeeper的树形分层结构就能提供分布式的API调用的能力。
典型的应用著名的Dubbo分布式框架就是应用了ZooKeeper分布式的JNDI能力。在Dubbo中,使用ZooKeeper维护全局的服务接口API地址列表。大致的思路为:
(1)服务提供者(Provider)在启动的时候向ZK上的指定节点写入自己的API地址,这个操作就相当于服务的公开。类似的API地址节点如下:
/dubbo/${serviceName}/providers
(2)服务消费者(Consumer)启动的时候,订阅节点/dubbo/{serviceName}/providers下的Provider服务提供者URL地址,获得所有访问提供者的API。
2. 分布式ID生成器
在分布式系统中,为每一个数据资源提供唯一的ID标识能力。在单体服务环境下,通常可以利用数据库的主键自增功能唯一标识一个数据资源。但是,在大量服务器集群的场景下,依赖单体服务的数据库主键自增生成唯一ID的方式没有办法满足高并发和高负载的需求。这时就需要分布式的ID生成器,保障分布式场景下的ID唯一性。
3. 分布式节点的命名
一个分布式系统通常会由很多节点组成,而且节点的数量不是固定的,是不断动态变化的。比如说,当业务不断膨胀和流量洪峰到来时,可能会动态加入大量的节点到集群中。一旦流量洪峰过去,就需要下线大量的节点。再比如说,由于机器或者网络的原因,一些节点会主动离开集群。
如何为大量的动态节点命名呢?一种简单的办法是,通过配置文件手动进行每一个节点的命名。如果节点数据量太大,或者说变动频繁,手动命名是不现实的,这就需要用到分布式节点的命名服务。疯狂创客圈的高并发“CrazyIM实战项目”也会使用分布式命名服务为每一个IM节点动态命名。
上面列举了三个分布式的命名服务场景,实际上需要用到分布式资源标识能力的场景远不止这些,这里只是抛砖引玉。
分布式事件监听的重点
实现对ZooKeeper服务端节点操作事件的监听是客户端操作服务器的一项重点工作。在Curator的API中,事件监听有两种模式:第一种是标准的观察者模式,通过Watcher监听器去实现;第二种是缓存监听模式,通过引入一种本地缓存视图Cache机制去实现。第二种Cache事件监听机制可以理解为一个本地缓存视图与远程ZooKeeper视图的对比过程。简单来说,Cache在客户端缓存了ZNode的各种状态,当感知到ZooKeeper集群的ZNode状态变化会触发事件时,注册在这些事件上的监听器会处理这些事件。
虽然Cache是一种缓存机制,但是可以借助Cache实现事件的监听。另外,Cache提供了事件监听器反复注册的能力,而观察模式的Watcher监听器只能监听一次。
在类型上,Watcher监听器比较简单,只有一种。Cache事件监听的种类有三种,包括PathCache、NodeCache、TreeCache。
分布式锁原理与实战
在单体的应用开发场景中涉及并发同步的时候,大家往往采用synchronized或者Lock的方式来解决多线程间的同步问题。在分布式集群工作的开发场景中需要一种更加高级的锁机制来处理跨JVM进程之间的数据同步问题,这就是分布式锁。
公平锁和可重入锁的原理
最经典的分布式锁是可重入的公平锁。什么是可重入的公平锁呢?直接讲解概念和原理会比较抽象难懂,这里用一个简单的故事来类比一下。
故事发生在没有自来水的古代,在一个村子里有一口井,水质非常好,村民都抢着取井里的水。井就一口,村里的人很多,村民为争抢取水而打架,甚至头破血流。
问题总是要解决的,村委会主任绞尽脑汁想出了一个凭号取水的方案。井边安排一个看井人,维护取水的秩序。取水秩序很简单:
(1)取水之前先取号。
(2)号排在前面的可以先取水。
(3)先到的排在前面,后到的一个一个挨着在井边排成一队。
取水示意图如图所示。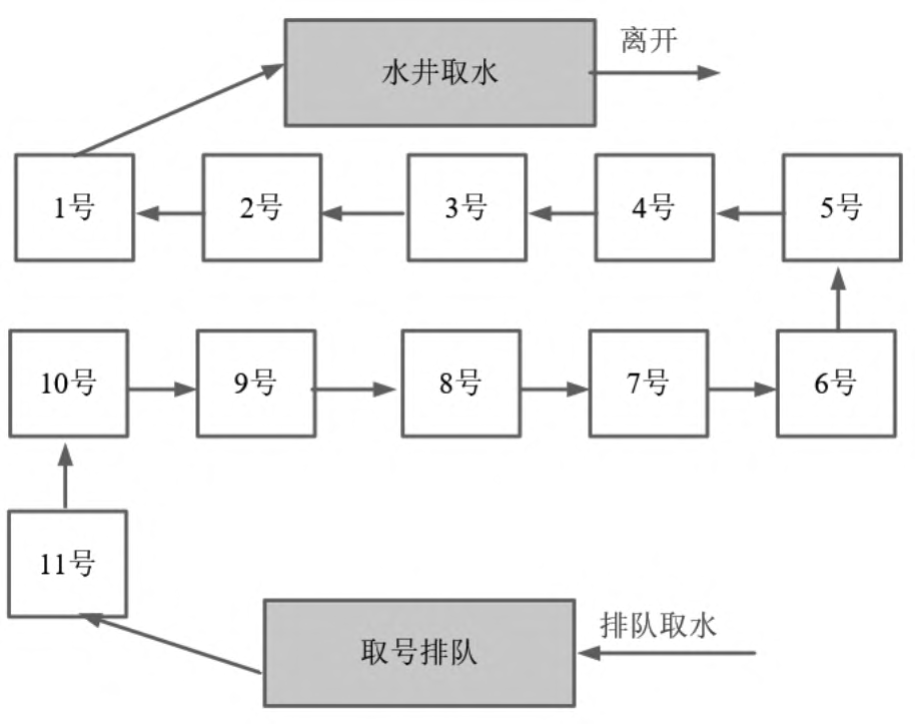
这种排队取水模型就是一种锁的模型。排在最前面的号拥有取水权,就是一种典型的独占锁。另外,先到先得,号排在前面的人先取到水,取水之后就轮到下一个号取水,挺公平的,说明它是一种公平锁。
什么是可重入锁?假定取水时以家庭为单位,家庭的某人拿到号,其他的家庭成员过来打水,这时不用再取号,如图所示。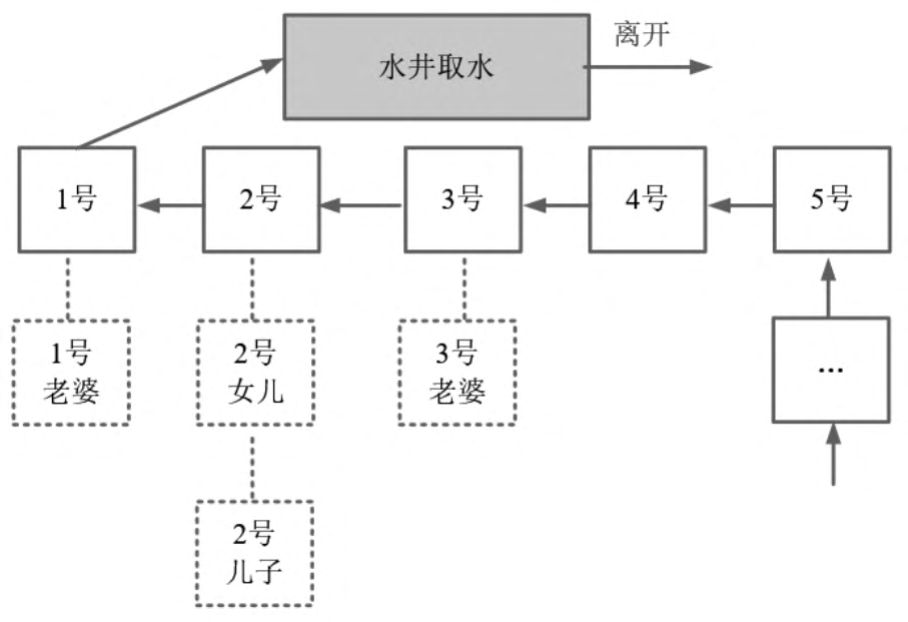
在图中,排在1号的家庭,老公取号,假设其老婆来了,直接排第一个。再看2号,父亲正在打水,假设其儿子和女儿也到井边了,直接排第二个。总之,如果取水时以家庭为单位,则同一个家庭可以直接复用排号,不用从后面排起重新取号。
在上面这个故事模型中,取号一次,可以多次取水,其原理为可重入锁的模型。在重入锁模型中,一把独占锁可以被多次锁定,这就叫作可重入锁。
ZooKeeper分布式锁的原理
理解了经典的公平可重入锁的原理后,再来看在分布式场景下的公平可重入锁的原理。通过前面的分析基本可以判定:ZooKeeper的临时顺序节点天生就有一副实现分布式锁的胚子。为什么呢?
(1)ZooKeeper的每一个节点都是一个天然的顺序发号器。
在每一个节点下面创建临时顺序节点(EPHEMERAL_SEQUENTIAL)类型,新的子节点后面会加上一个次序编号,而这个生成的次序编号是上一个生成的次序编号加一。
例如,有一个用于发号的节点“/test/lock”为父节点,可以在这个父节点下面创建相同前缀的临时顺序子节点,假定相同的前缀为“/test/lock/seq-”。第一个创建的子节点基本上应该为/test/lock/seq-0000000000,下一个节点则为/test/lock/seq-0000000001,以此类推,如图所示。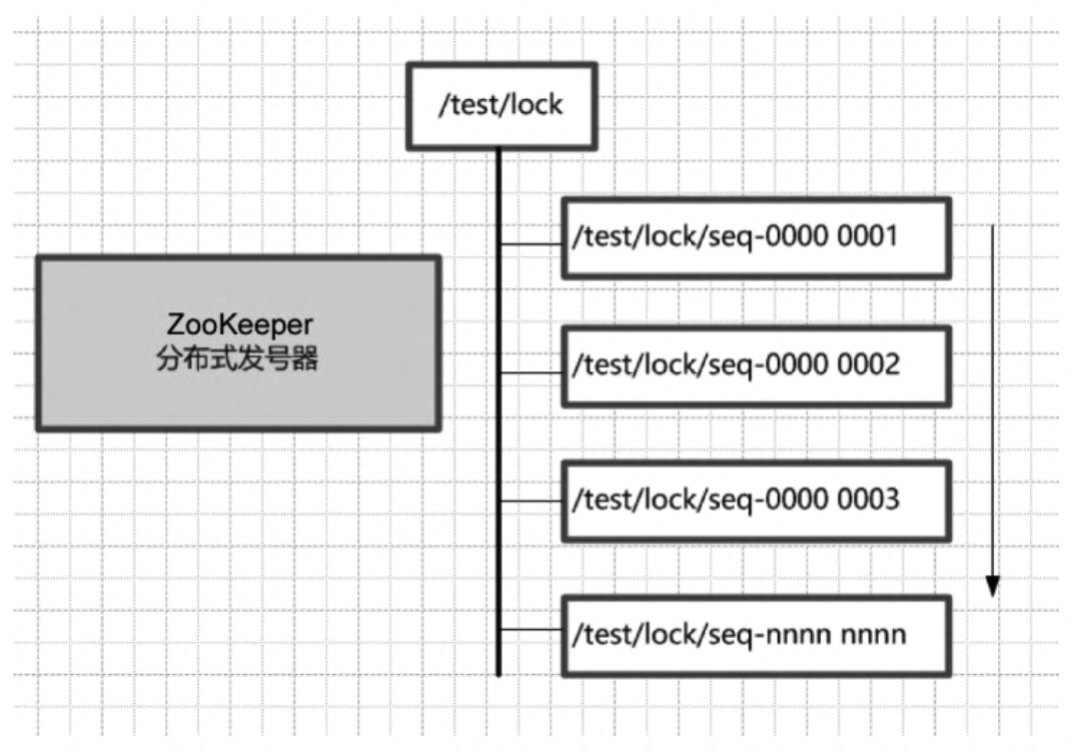
(2)ZooKeeper节点的递增有序性可以确保锁的公平。
一个ZooKeeper分布式锁需要创建一个父节点,尽量是持久节点(PERSISTENT类型),然后每个要获得锁的线程都在这个节点下创建一个临时顺序节点,因为ZooKeeper节点是按照创建的次序依次递增的。
为了确保公平,可以简单地规定:编号最小的那个节点表示获得了锁。所以,每个线程在尝试占用锁之前首先判断自己的排号是不是当前最小,如果是就获取锁。
(3)ZooKeeper的节点监听机制可以保障占有锁的传递有序而且高效。
每个线程抢占锁之前,先尝试创建自己的ZNode。同样,释放锁的时候需要删除创建的ZNode。创建成功后,如果不是排号最小的节点,就处于等待通知的状态。前一个ZNode删除的时候,会触发ZNode事件,当前节点监听到删除事件就是轮到了自己占有锁的时候。第一个通知第二个,第二个通知第三个,击鼓传花似的依次向后。
ZooKeeper的节点监听机制能够非常完美地实现这种击鼓传花似的信息传递。具体的方法是,每一个等通知的ZNode节点只需要监听(listen)或者监视(watch)排号在自己前面的那个,而且紧挨在自己前面的那个节点就能收到其删除事件了。只要上一个节点被删除了,就进行再一次判断,看看自己是不是序号最小的那个节点,如果是,自己就获得锁。
另外,ZooKeeper的内部优越机制能保证由于网络异常或者其他原因,集群中占用锁的客户端失联时锁能够被有效释放。一旦占用ZNode锁的客户端与ZooKeeper集群服务器失去联系,这个临时ZNode也将自动删除。排在它后面的那个节点也能收到删除事件,从而获得锁。正是由于这个原因,在创建取号节点的时候尽量创建临时ZNode节点。
(4)ZooKeeper的节点监听机制能避免羊群效应。
ZooKeeper这种首尾相接、后面监听前面的方式可以避免羊群效应。所谓羊群效应,就是一个节点挂掉,所有节点都去监听,然后做出反应,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反应。
分布式锁的基本流程
加锁的实现
释放锁的实现
分布式锁的使用
Curator的InterProcessMutex可重入锁
ZooKeeper分布式锁的优缺点
总结一下ZooKeeper分布式锁:
优点:ZooKeeper分布式锁(如InterProcessMutex)能有效地解决分布式问题、不可重入问题,使用起来较为简单。
缺点:ZooKeeper实现的分布式锁性能不太高。因为每次在创建锁和释放锁的过程中都要动态创建、销毁瞬时节点。在ZooKeeper中,创建和删除节点只能通过Leader服务器来执行,然后Leader服务器还需要将数据同步到所有的Follower机器上,这样频繁的网络通信,性能的短板是非常突出的。
总之,在高性能、高并发的场景下,不建议使用ZooKeeper的分布式锁。由于ZooKeeper具有高可用特性,因此在并发量不是太高的场景推荐使用ooKeeper的分布式锁。
在目前分布式锁的实现方案中,比较成熟、主流的方案有两种:
(1)基于ZooKeeper的分布式锁,适用于高可靠(高可用)而并发量不是太大的场景。
(2)基于Redis的分布式锁,适用于并发量很大、性能要求很高、可靠性问题可以通过其他方案去弥补的场景。
总之,没有谁好谁坏的问题,而是谁更适合的问题。
《Java高并发核心编程》卷1:第14章分布式缓存Redis实战
数据库的查询比较耗时,使用缓存能大大节省数据访问的时间。例如,表中有两千万个用户信息,在加载用户信息时,一次数据库查询大致的时间在数百毫秒级别。这仅仅是一次查询,如果是频繁多次的数据库查询,效率就会更低。
提升效率的通用做法是把数据加入缓存,每次加载数据之前先去缓存中加载,如果为空,就再去查询数据库并将数据加入缓存。这样可以大大提高数据访问的效率。
从大的层面来说,在开发高并发系统时,有三把利器用来保护系统:缓存、降级和限流。其中,缓存是最为重要的一个应对高并发的方式。Redis缓存中间件目前已经成为缓存的事实标准。
Redis入门
Redis的安装和配置
Redis客户端命令
Redis键的命名规范
Redis数据类型
Redis中有5种数据类型:String(字符串类型)、Hash(哈希类型)、List(列表类型)、Set(集合类型)、ZSet(有序集合类型)
Jedis基础编程的实战案例
JedisPool连接池的实战案例
使用spring-data-redis完成CRUD的实战案例
Spring的Redis缓存注解
前面讲的Redis缓存实现都是基于Java代码实现的。在Spring中,合理地添加缓存注解也能实现和前面示例程序中一样的缓存功能。
为了方便地提供缓存能力,Spring提供了一组缓存注解。这组注解不仅仅是针对Redis,本质上不是一种具体的缓存实现方案(例如Redis、EHCache等),而是对缓存使用的统一抽象。利用这组缓存注解,以及与具体缓存相匹配的Spring配置,不用编码就可以快速达到缓存的效果
详解SpEL
SpEL(Spring Expression Language,Spring表达式语言)。提供一种强大、简洁的Spring Bean的动态操作表达式。SpEL表达式可以在运行期间执行,其值可以动态装配到Spring Bean属性或构造函数中。SpEL表达式可以调用Java静态方法、访问Properties文件中的配置值等。SpEL能够与Spring功能完美整合,给静态Java语言增加了动态功能。
《Java高并发核心编程》卷1:第15章亿级高并发IM架构与实战
本章结合分布式缓存Redis、分布式协调ZooKeeper、高性能通信Netty,从架构的维度设计一套亿级IM的高并发架构方案,并从学习和实战的角度出发,联合“疯狂创客圈”社群的高性能发烧友一起持续进行一个支持亿级流量的IM项目开发与迭代,该项目暂时被命名为CrazyIM。
支撑亿级流量的高并发IM架构的理论基础
支撑亿级流量的高并发IM通信需要用到Netty集群、ZooKeeper集 群、Redis集群、MySQL集群、Spring Cloud Web服务集群、RocketMQ 消息队列集群等,具体如图所示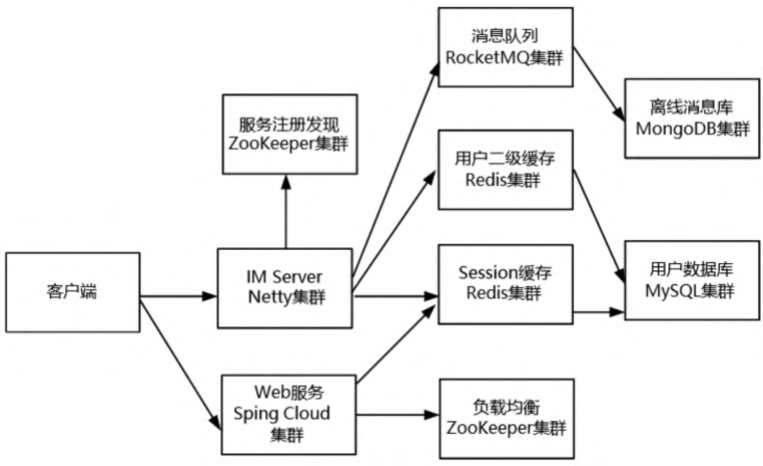
分布式IM的命名服务的实战案例
Worker集群的负载均衡的实战案例
即时通信消息的路由和转发的实战案例
在线用户统计的实战案例
<未完待续>