Prometheus监控系统及架构原理
Prometheus 概述
在本指南中,我们将详细了解 Prometheus 架构,以有效地理解、配置和利用 Prometheus。
Prometheus 是一个用 Golang 编写的流行开源监控和警报系统,能够收集和处理来自各种目标的指标。您还可以查询、查看、分析指标并根据阈值收到警报。
此外,在当今世界,可观察性对于每个组织都变得至关重要,而 Prometheus 是开源领域的关键观测工具之一。
Prometheus是一个开源的服务监控系统和时序数据库,其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件 Prometheus server 会定期从静态配置的监控目标或者基于服务发现自动配置的目标中进行拉取数据,新拉取到的数据会持久化到存储设备当中。
每个被监控的主机都可以通过专用的 exporter 程序提供输出监控指标数据的接口,它会在目标处收集监控数据,并暴露出一个 HTTP 接口供 Prometheus server 查询, Prometheus 通过基于 HTTP 的 pull 的方式来周期性的采集数据,默认时间是 15s 抓取一次。
抓取到的指标数据会被以时间序列的形式保存在内存中,并且定时刷到磁盘上,默认是两个小时回刷一次。并且为了防止 Prometheus 发生崩溃或重启时能够恢复数据, Prometheus 也提供了类似 MySQL 中 binlog 一样的 wal 预写日志,当 Prometheus 崩溃重启时,会读这个预写日志来恢复数据。
对于短时间执行的脚本任务或者不好直接 pull 指标数据的服务,Prometheus 提供了 Pushgateway 给这些任务将服务指标数据主动 push 到 Pushgateway 并临时存储,然后等待 Prometheus server 完成数据的采集。
任何被监控的目标都需要事先纳入到监控系统中才能进行时序数据采集、存储、告警和展示,监控目标可以通过配置信息以静态形式指定,也可以让 Prometheus 通过服务发现的机制进行动态管理。
Prometheus 能够直接把K8S的 API Server 作为服务发现系统使用,进而动态发现和监控K8S集群中的所有可被监控的对象。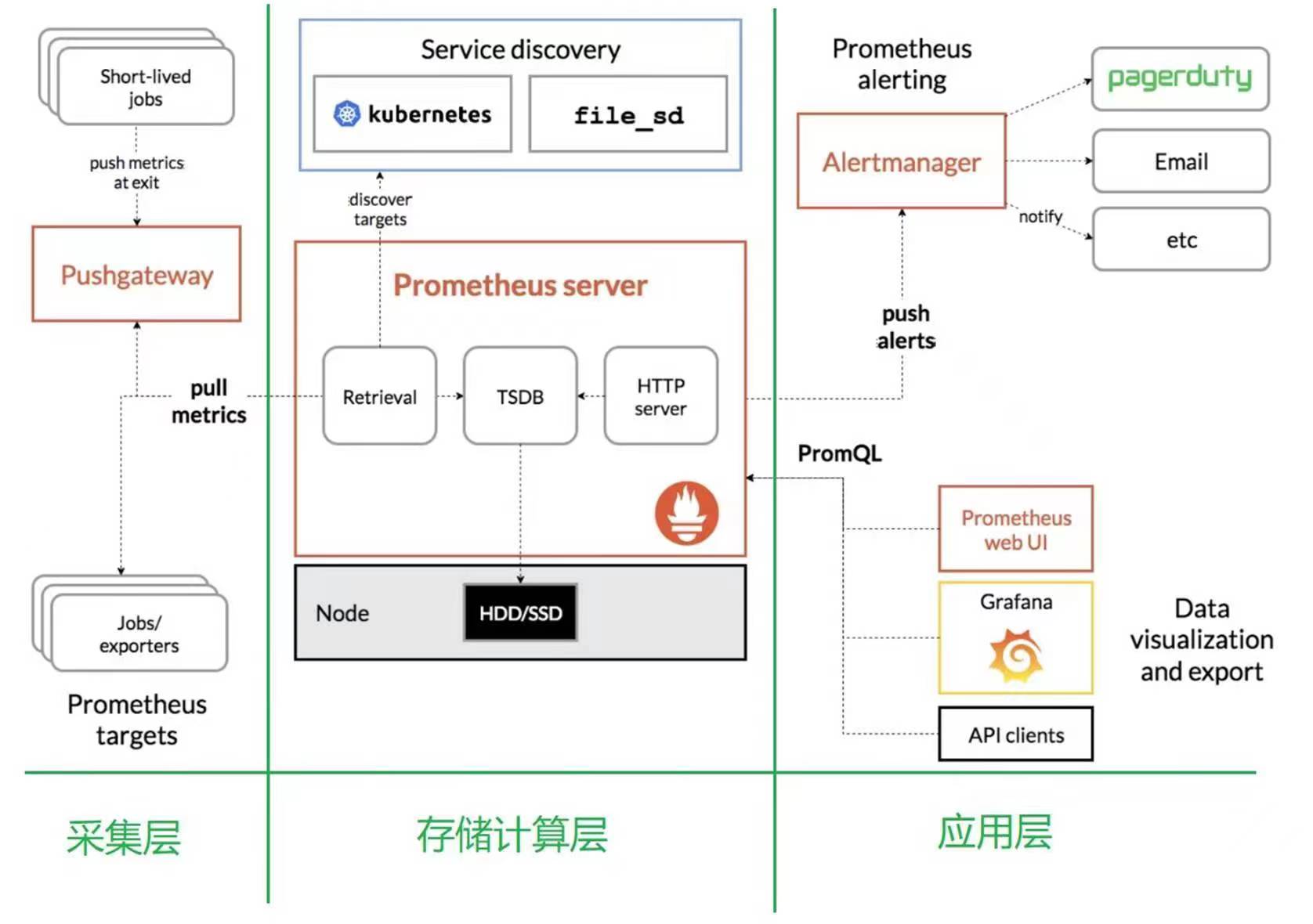
(1)TSDB 作为 Prometheus 的存储引擎完美契合了监控数据的应用场景
●存储的数据量级十分庞大
●大部分时间都是写入操作
●写入操作几乎是顺序添加,大多数时候数据都以时间排序
●很少更新数据,大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库
●删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据
●基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用
●读操作是十分典型的升序或者降序的顺序读
●高并发的读操作十分常见
(2)Prometheus 的特点
●多维数据模型:由度量名称和键值对标识的时间序列数据
时间序列数据:按照时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本;服务器指标数据、应用程序性能监控数据、网络数据等都是时序数据
●内置时间序列(Time Series)数据库:Prometheus ;外置的远端存储通常会用:InfluxDB、OpenTSDB 等
●promQL 一种灵活的查询语言,可以利用多维数据完成复杂查询
●基于 HTTP 的 pull(拉取)方式采集时间序列数据
●同时支持 PushGateway 组件收集数据
●通过静态配置或服务发现发现目标
●支持作为数据源接入 Grafana
(3)Prometheus的主要组件
(1)prometheus server
是Prometheus服务的核心组件。通过http pull拉取的方式从监控目标采集监控指标数据(时序数据);作为时序数据库持久化存储监控指标数据;
配置告警规则,当触告警时会生成告警通知发送给alertmanager;配置service discovery服务发现,可通过文件、cousul、K8S等方式自动发现监控目标target
(2)exporter
指标暴露器,用于从原生不支持prometheus直接采集监控指标数据的系统或应用等对象收集和汇总监控指标数据,并暴露http接口供prometheus server采集数据
node-exporter、kube-state-matrics、nginx/mysqld/redis-exporter、cADvisor、blackbox-exporter
(3)alertmanager
接收prometheus server发来的告警通知,负责对告警通知分组、去重,再通过邮件、钉钉、企业微信等方式发送给接收人
(4)pushgateway
作为临时中转站,接收一些短期任务或只能推送数据的任务发送的监控指标数据,临时存储这些监控指标数据并统一供prometheus server采集数据
(5)grafana
外置的监控数据展示平台,接入prometheus的数据源,通过promQL查询数据,以图形化形式展示监控数据
(4)Prometheus 的局限性
●Prometheus 是一款指标监控系统,不适合存储事件及日志等;它更多地展示的是趋势性的监控,而非精准数据;
●Prometheus 认为只有最近的监控数据才有查询的需要,其本地存储的设计初衷只是保存短期(例如一个月)数据,因而不支持针对大量的历史数据进行存储;
若需要存储长期的历史数据,建议基于远端存储机制将数据保存于 InfluxDB 或 OpenTSDB 等系统中;
●Prometheus 的集群机制成熟度不高,可基于 Thanos 或 Cortex 实现 Prometheus 集群的高可用及联邦集群。
(5)Zabbix和Prometheus的区别?如何选择?
(1)Zabbix
更适合于传统业务架构的物理机、虚拟机环境的监控,对服务器系统和传统应用组件监控比较成熟,但是对容器的支持比较差。
数据存储主要采用的是关系型数据库,会随着被监控节点数量的增加,关系型数据库的负载压力也会变大,监控数据的读写也会变慢。
对大规模集群监控的性能比prometheus要弱一些,可适用于单集群规模不超过1000台节点的场景。
(2)Prometheus
除了传统业务架构,还能支持云环境、K8S容器集群的监控,是目前容器监控最好的解决方案。
数据存储采用的是时序数据库,大大的节省存储空间,还能提升查询效率。
单集群能支持的节点规模更大,通常超过2000台节点、服务数量大于1000个的时候建议直接上Prometheus。
(6)Prometheus的工作流程
1)prometheus server通过静态配置或服务发现的方式获取监控目标target(通过exporter或pushgateway暴露的http接口)
2)prometheus server通过http pull拉取的方式从监控目标target采集监控指标数据
3)prometheus server将采集到的监控指标数据通过时序数据库持久化存储到本地磁盘或外置存储中
4)prometheus server通过将采集到的监控指标数据与本地配置的监控告警规则进行计算比对,如果触发告警则生成告警通知发送给alertmanager
5)alertmanager接收到prometheus server发来的告警通知后,对告警通知分组、去重,再通过邮件、钉钉、企业微信等方式发送给接收人
6)prometheus支持原生的web UI或grafana接入prometheus数据源,通过promQL查询数据,以图形化形式展示监控数据
Prometheus 架构概述
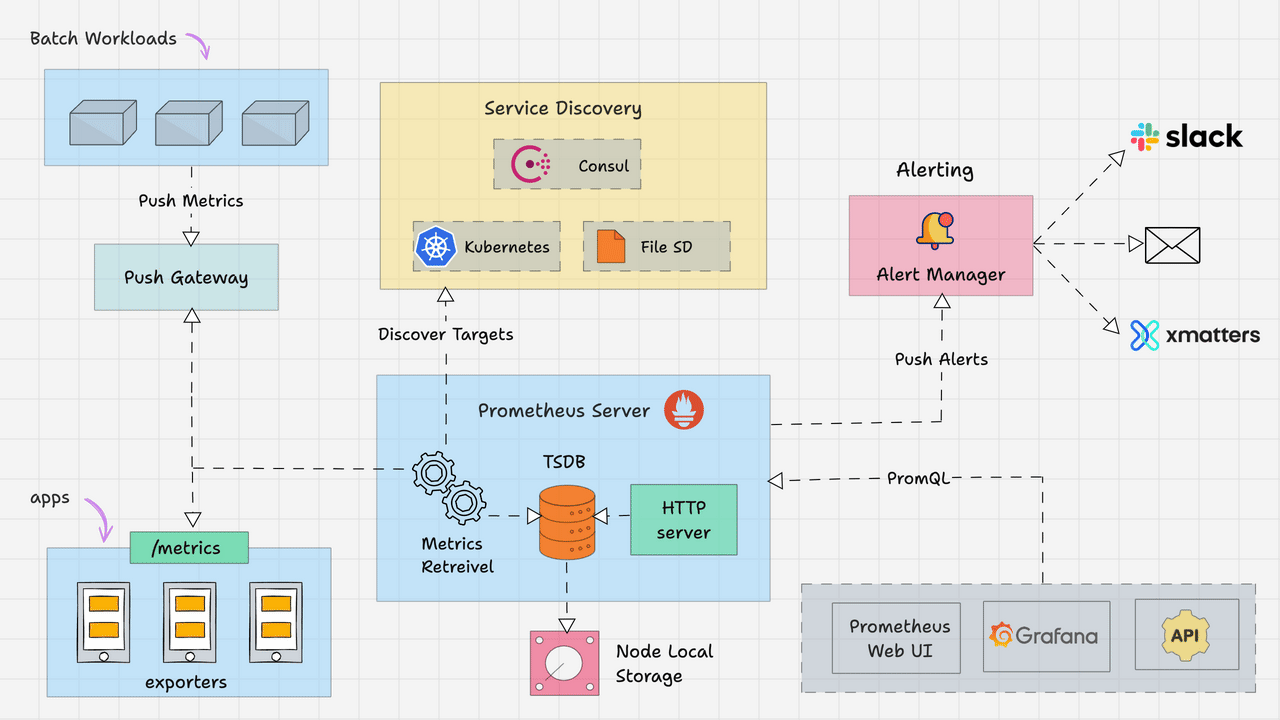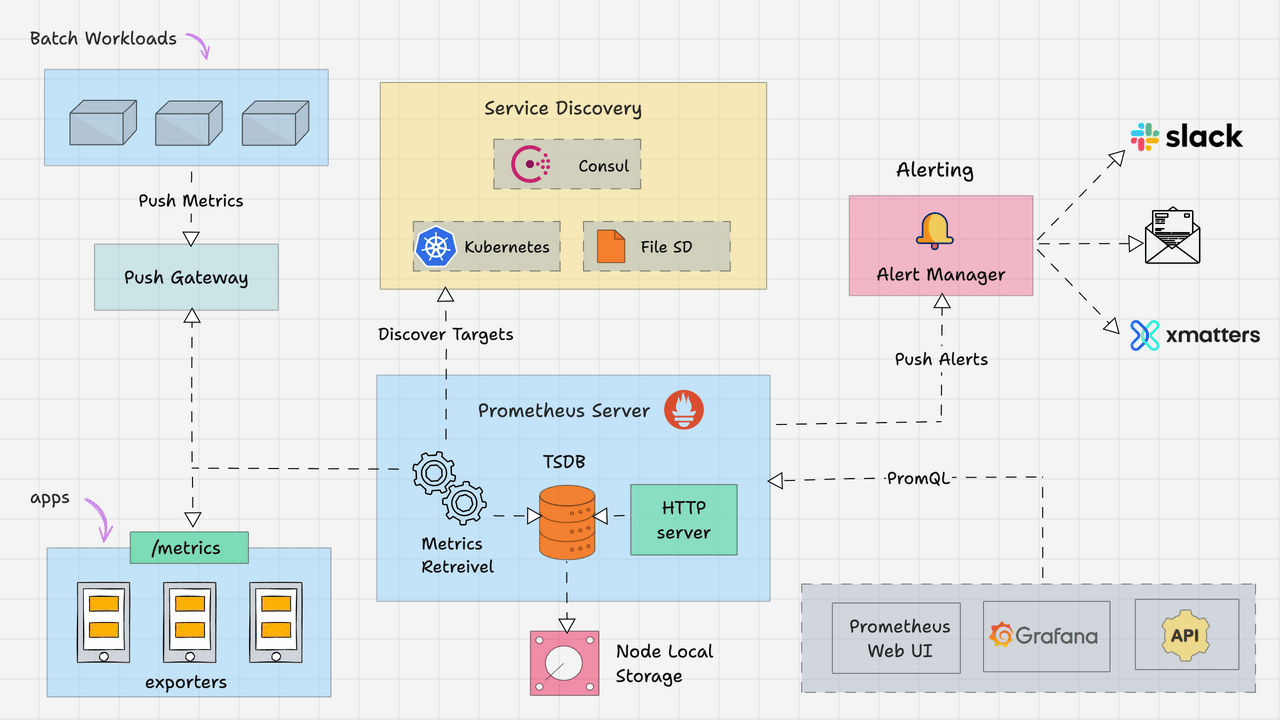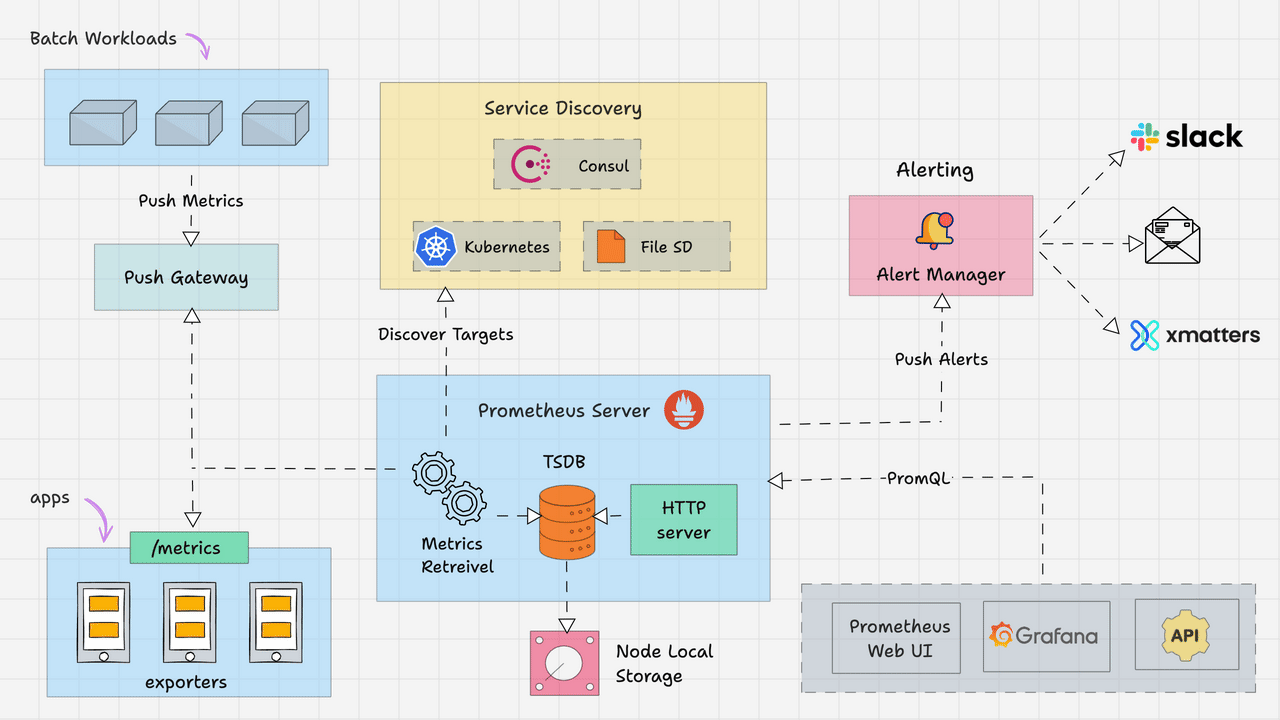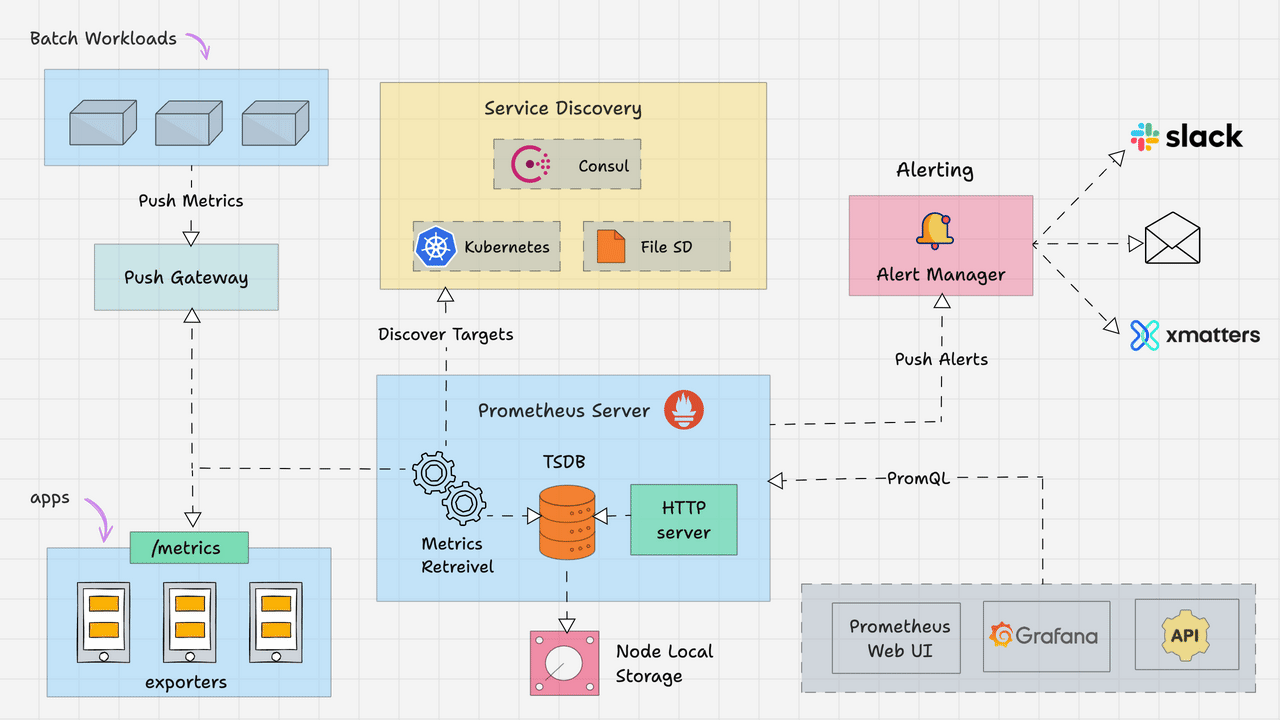
Prometheus主要由以下部分组成:
- Prometheus Server
- Service Discovery
- Time-Series Database (TSDB)
- Targets
- Exporters
- Push Gateway
- Alert Manager
- Client Libraries
- PromQL
让我们详细看看每个组件。
Prometheus Server
Prometheus 服务器是基于指标的监控系统的大脑。服务器的主要工作是使用拉模型从各个目标收集指标。目标只不过是服务器、pod、端点等。使用 Prometheus 从目标收集指标的通用术语称为抓取。
source/_posts/Prometheus监控系统及架构原理/Prometheus-arch.png
Prometheus 根据我们在 Prometheus 配置文件中给出的抓取间隔定期抓取指标。这是一个配置示例。
1 | global: |
Time-Series Database (TSDB)
prometheus 接收到的指标数据随着时间的推移而变化(CPU、内存、网络 IO 等)。它被称为时间序列数据。因此 Prometheus 使用时间序列数据库(TSDB)来存储其所有数据。默认情况下,Prometheus 以高效的格式(块)将其所有数据存储在本地磁盘中。随着时间的推移,它会压缩所有旧数据以节省空间。它还具有删除旧数据的保留策略。TSDB 具有内置的机制来管理长期保存的数据。您可以选择以下任意数据保留策略。
- 基于时间的保留:数据将保留指定的天数。默认保留期为 15 天。
- 基于大小的保留:您可以指定 TSDB 可以容纳的最大数据量。一旦达到这个限制,普罗米修斯将释放空间来容纳新数据。
Prometheus 还提供远程存储选项。这主要是存储可扩展性、长期存储、备份和灾难恢复等所需要的。
Prometheus Targets
Target 是 Prometheus 抓取指标的来源。目标可以是服务器、服务、Kubernetes Pod、应用程序端点等。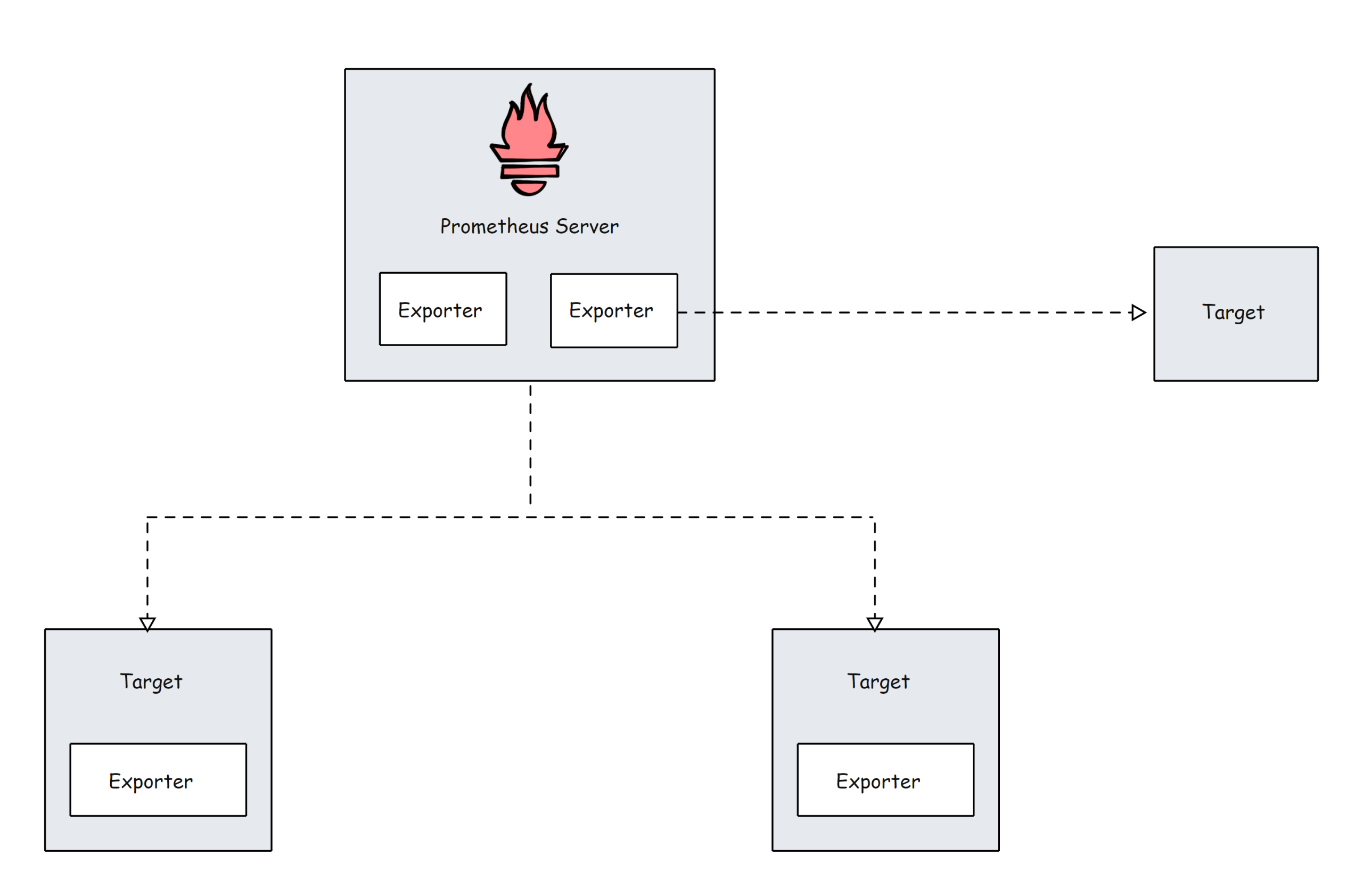
默认情况下,prometheus 会在目标的 /metrics 路径下查找指标。可以在目标配置中更改默认路径。这意味着,如果您不指定自定义指标路径,Prometheus 会在 /metrics 下查找指标。
目标配置位于 Prometheus 配置文件中的 scrape_configs 下。这是一个配置示例。
1 | scrape_configs: |
Prometheus 需要来自目标端点的特定文本格式的数据。每个指标都必须换行。通常,这些指标使用 Prometheus exporters 来暴露。Prometheus exporter 通常和 target 伴生在一起。
Prometheus Exporters
Exporter 就像在目标上运行的代理。它将指标从特定系统转换为普罗米修斯可以理解的格式。它可以是系统指标,如 CPU、内存等,也可以是 Java JMX 指标、MySQL 指标等。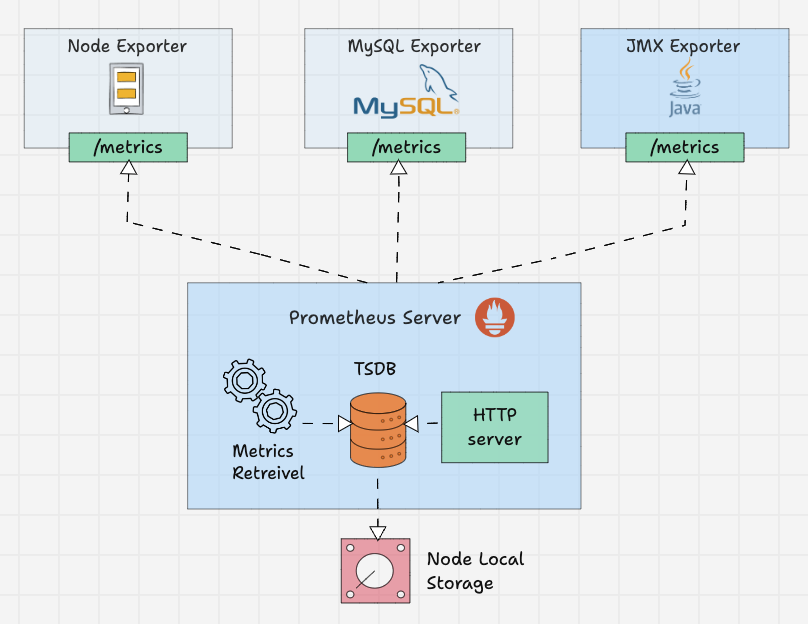
默认情况下,这些转换后的指标由 Exporter 在目标的 /metrics 路径(HTTP 端点)上公开。例如,如果要监控服务器的 CPU 和内存,则需要在该服务器上安装 Node Exporter,并且 Node Exporter 以 prometheus 指标格式在 /metrics 上公开 CPU 和内存指标。一旦 Prometheus 提取指标,它将结合指标名称、标签、值和时间戳生成结构化数据。
社区有很多 Exporters 可用,但只有其中一些获得 Prometheus 官方认可。如果您需要更多自定义采集,则需要创建自己的导出器。Prometheus 将 Exporter 分为各个部分,例如数据库、硬件、问题跟踪器和持续集成、消息系统、存储、公开 Prometheus 指标的软件、其他第三方实用程序等。您可以从官方文档中查看每个类别的 Exporter 列表。
在 Prometheus 配置文件中,所有 Exporter 的详细信息将在 scrape_configs 下给出。
1 | scrape_configs: |
Prometheus Service Discovery
Prometheus 使用两种方法从目标中获取指标。
- 静态配置:当目标具有静态 IP 或 DNS 端点时,我们可以使用这些端点作为目标。
- 服务发现:在大多数自动伸缩系统和 Kubernetes 等分布式系统中,目标不会有静态端点。在这种情况下,使用 prometheus 服务发现来发现目标端点,并且目标会自动添加到 prometheus 配置中。
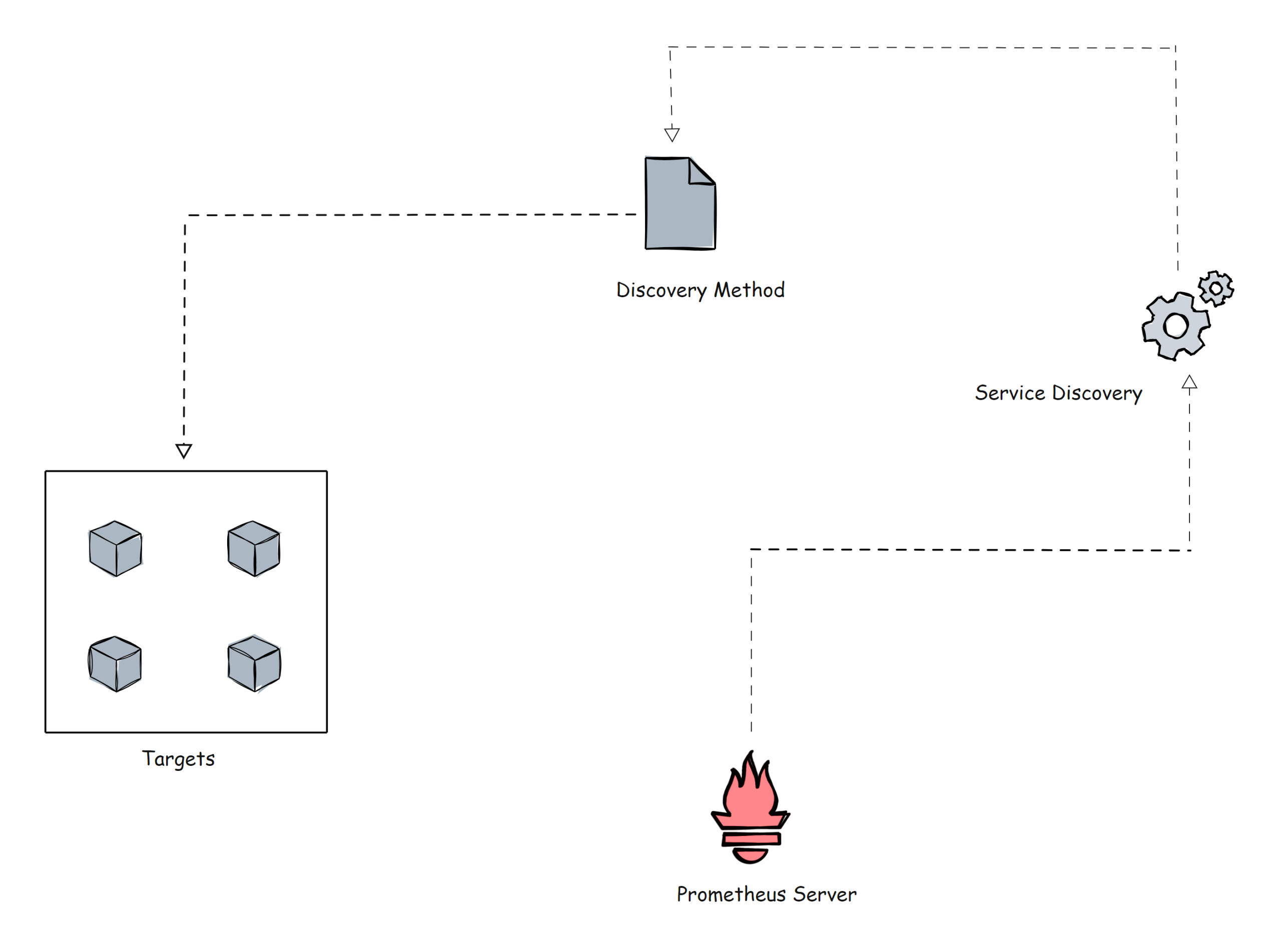
在进一步讨论之前,让我展示一个使用 kubernetes_sd_configs 的 Prometheus 配置文件的 Kubernetes 服务发现块的小示例。
1 | scrape_configs: |
Kubernetes 是动态目标的完美示例。在这里,您不能使用静态目标方法,因为 Kubernetes 集群中的目标(pod)可能是短暂存活的。
Kubernetes 中还有基于文件的服务发现 file_sd_configs 。它适用于静态目标,但经典静态配置 static_configs 和 file_sd_configs 之间的主要区别在于,在这种情况下,我们创建单独的 JSON 或 YAML 文件并将目标信息保存在文件中。Prometheus 将读取文件来识别目标。
不仅这两种,还可以使用各种服务发现方法,例如 consul_sd_configs(prometheus 从 consul 获取目标详细信息)、ec2_sd_configs 等。如需了解更多配置细节,请访问官方文档。
Prometheus Pushgateway
Prometheus 默认使用 pull 方式来抓取指标。然而,有些场景需要将指标推送到 prometheus。让我们举一个在 Kubernetes cronjob 上运行的批处理作业的示例,该作业每天根据某些事件运行 5 分钟。在这种情况下,Prometheus 将无法使用拉机制正确抓取服务级别指标。因此,我们需要将指标推送到 prometheus,而不是等待 prometheus 拉取指标。为了推送指标,prometheus 提供了一个名为 Pushgateway 的解决方案。它是一种中间网关。
Pushgateway 需要作为独立组件运行。批处理作业可以使用 HTTP API 将指标推送到 Pushgateway。然后 Pushgateway 在 /metrics 端点上公开这些指标。然后 Prometheus 从 Pushgateway 中抓取这些指标。
Pushgateway 将指标数据临时存储在内存中。它更像是一个临时缓存。Pushgateway 配置也将在 Prometheus 配置中的 scrape_configs 部分下进行配置。
1 | scrape_configs: |
要将指标发送到 Pushgateway,您需要使用 prometheus 客户端库对应用程序插桩,或使用脚本暴露指标。
Prometheus Client Libraries
Prometheus 客户端库是可用于检测应用程序代码的软件库,以 Prometheus 理解的方式公开指标。如果您需要自行埋点插桩或想要创建自己的Exporter,则可以使用客户端库。
一个非常好的用例是需要将指标推送到 Pushgateway 的批处理作业。批处理作业使用客户端库来埋点,以 prometheus 格式暴露指标。下面是一个 Python Client Library 的示例,它公开了名为 batch_job_records_processed_total 的自定义指标。
1 | from prometheus_client import start_http_server, Counter |
在使用客户端库时,prometheus_client 会在 /metrics 端点上公开指标。Prometheus 拥有几乎所有编程语言的客户端库,如果您想创建客户端库,也 OK。要了解更多创建指南和查看客户端库列表,您可以参考官方文档。
Prometheus Alert Manager
Alertmanager 是 Prometheus 监控系统的关键部分。它的主要工作是根据 Prometheus 警报配置中设置的指标阈值发送警报。警报由 Prometheus 触发(注意,是由 Prometheus 进程触发原始告警)并发送到 Alertmanager。Alertmanager 对告警去重、抑制、静默、分组,最后使用各类通知媒介(电子邮件、slack 等)发出告警事件。其具体功能:
- Alert Deduplicating:消除重复警报
- Grouping:将相关警报分组在一起
- Silencing:静默维护
- Routing:路由,根据严重性将警报路由到适当的接收者
- Inhibition:抑制,当存在中高严重性警报时停止低严重性警报的过程
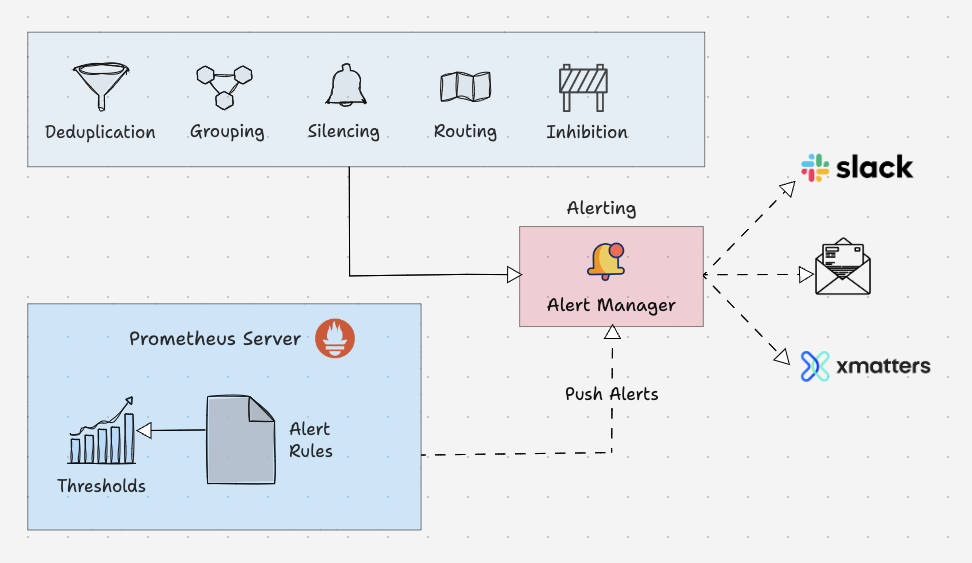
以下是警报规则的配置示例:
1 | groups: |
这是 Alertmanager 配置文件的路由配置示例:
1 | routes: |
Alertmanager 支持大多数消息和通知系统,例如 Discord、电子邮件、Slack 等,以将警报作为通知发送给接收者。
PromQL
PromQL 是一种灵活的查询语言,可用于从 prometheus 查询时间序列指标。
译者注:这是 Prometheus 生态的重中之重,我之前写过一篇《PromQL 从入门到精通》,尽量融入了生产使用场景,读者可以下载学习。
我们可以直接从 Prometheus 用户界面使用查询,也可以使用 curl 命令通过命令行界面进行查询。
Prometheus UI
另外,当您将 prometheus 作为数据源添加到 Grafana 时,您可以使用 PromQL 来查询和创建 Grafana 仪表板,如下所示。
总结
这解释了 Prometheus 架构的主要组件,并将给出 Prometheus 配置的基本概述,您还可以使用配置做很多事情。每个组织的需求会有所不同,并且 Prometheus 在不同环境(例如 VM 和 Kubernetes)中的实现也有所不同。如果您了解基础知识和关键配置,您就可以轻松地在任何平台上落地它。