ELFK企业级日志系统架构技术-ELFK(Elasticsearch、Filebeat、Kafka、Logstash、Kibana)
一、什么是ELFK
1、ELK已经成为目前最流行的集中式日志解决方案,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
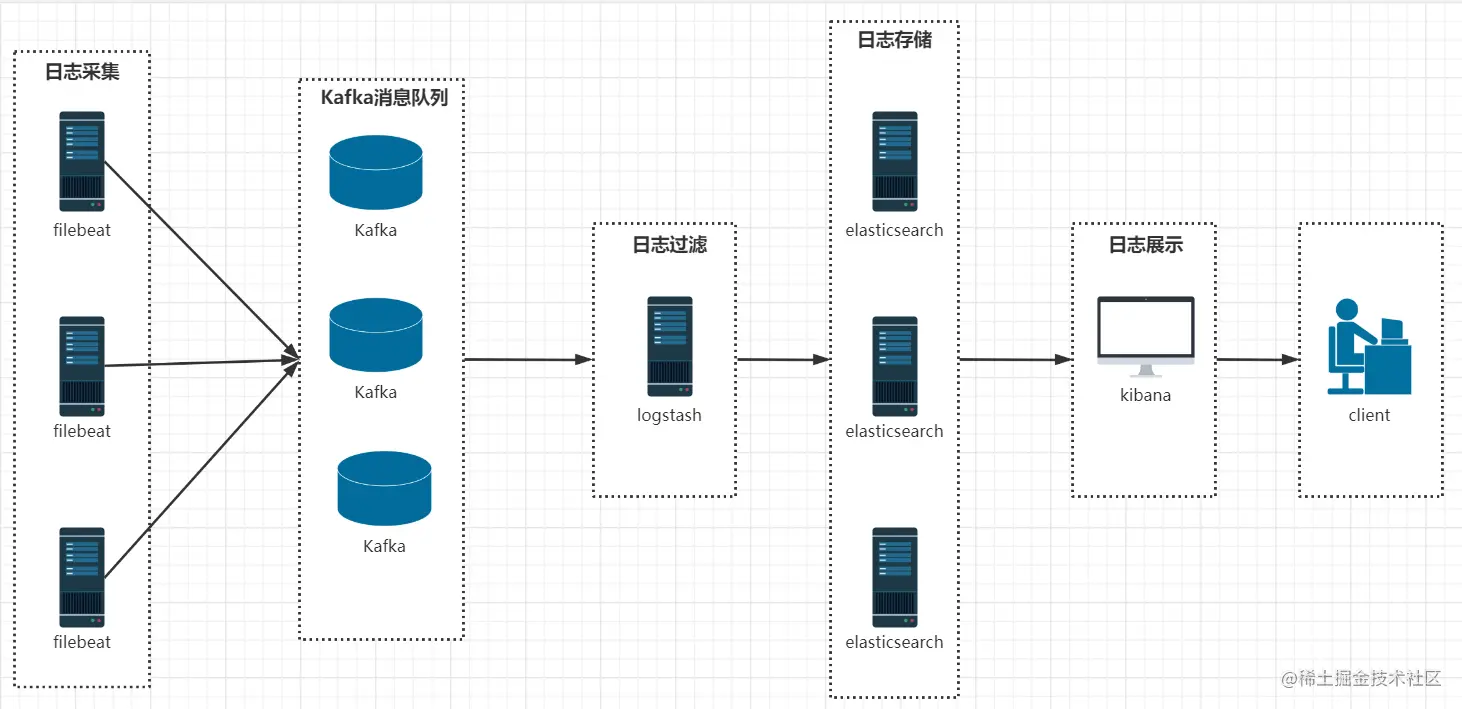
日志系统大致流程图: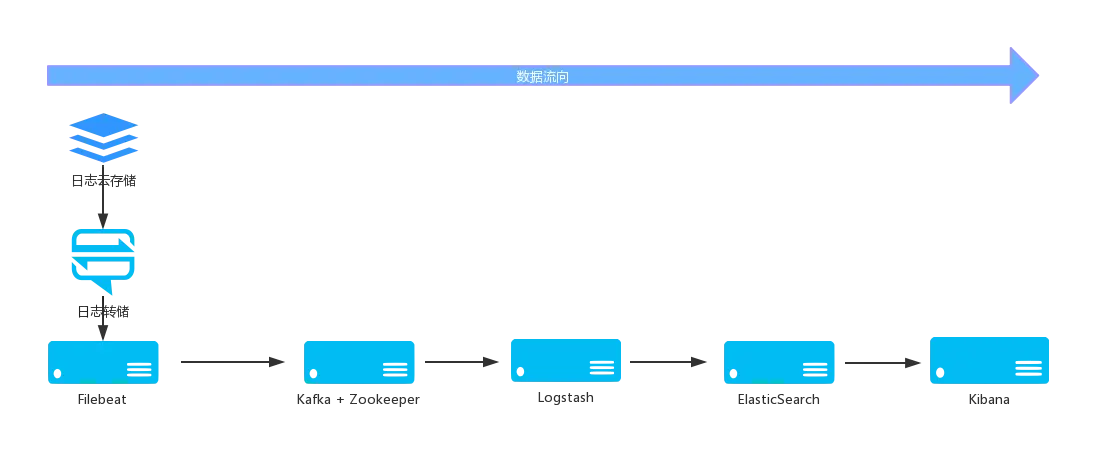
2、Elasticsearch存储 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
3、Logstash过滤 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
- 优点
可伸缩性
集群应该在一组Logstash节点之间进行负载平衡。
建议至少使用两个Logstash节点以实现高可用性。
每个Logstash节点只部署一个Beats输入是很常见的,但每个Logstash节点也可以部署多个Beats输入,以便为不同的数据源公开独立的端点。
弹性
Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹性,确保磁盘冗余非常重要。对于内部部署,建议您配置RAID。在云或容器化环境中运行时,建议您使用具有反映数据SLA的复制策略的永久磁盘。
可过滤
对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。
- 缺点
Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
4、Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
5、Filebeat日志数据采集隶属于Beats。
filebeat是Beats中的一员,Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件。
- 优点
Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少。
- 缺点
Filebeat 的应用范围十分有限,因此在某些场景下咱们会碰到问题。在 5.x 版本中,它还具有过滤的能力。
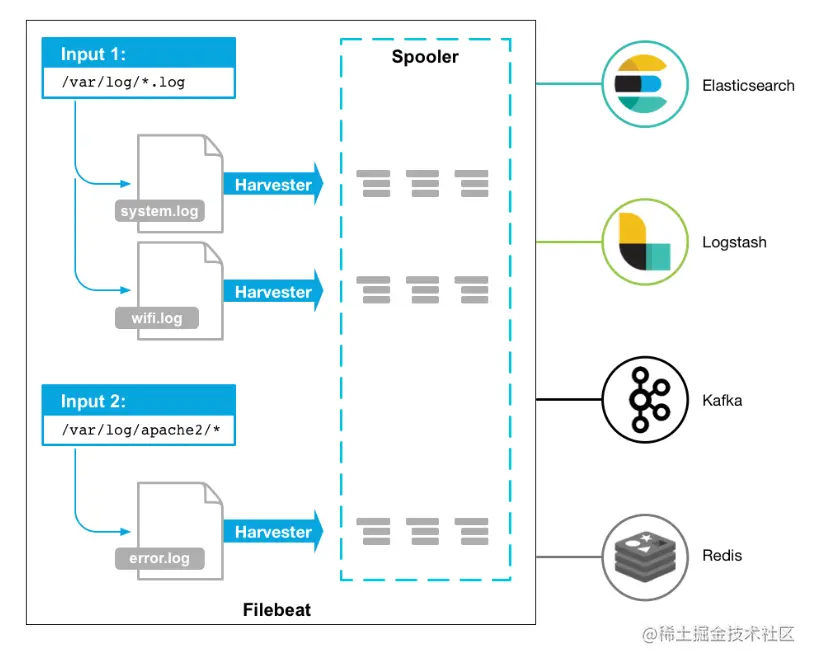
目前Beats包含六种工具:
- Packetbeat:网络数据(收集网络流量数据)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Filebeat:日志文件(收集文件数据)
- Winlogbeat:windows事件日志(收集Windows事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据)
6、Kafka
kafka能帮助我们削峰。ELK可以使用redis作为消息队列,但redis作为消息队列不是强项而且redis集群不如专业的消息发布系统kafka。kafka安装可以参考我之前的文章:Kafka原理介绍+安装+基本操作(kafka on k8s)。
二、为什么要用ELFK
1、一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
2、一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
3、一个完整的集中式日志系统,需要包含以下几个主要特点:收集、传输、存储、分析、警告,而ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。并且是目前主流的一种日志系统。
三、ELK常见部署架构
1、 Logstash作为日志收集器
这种架构是比较原始的部署架构,在各应用服务器端分别部署一个Logstash组件,作为日志收集器,然后将Logstash收集到的数据过滤、分析、格式化处理后发送至Elasticsearch存储,最后使用Kibana进行可视化展示,这种架构不足的是:Logstash比较耗服务器资源,所以会增加应用服务器端的负载压力。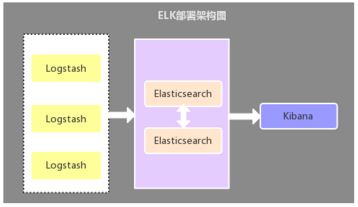
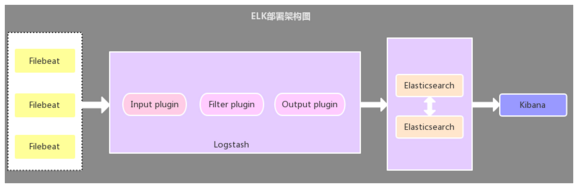
2、Filebeat作为日志收集器
该架构与第一种架构唯一不同的是:应用端日志收集器换成了Filebeat,Filebeat轻量,占用服务器资源少,所以使用Filebeat作为应用服务器端的日志收集器,一般Filebeat会配合Logstash一起使用,这种部署方式也是目前最常用的架构。
filebeat和logstash的关系
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,加入elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。
3、引入缓存队列的部署架构
该架构在第二种架构的基础上引入了Kafka消息队列(还可以是其他消息队列),将Filebeat收集到的数据发送至Kafka,然后在通过Logstasth读取Kafka中的数据,这种架构主要是解决大数据量下的日志收集方案,使用缓存队列主要是解决数据安全与均衡Logstash与Elasticsearch负载压力。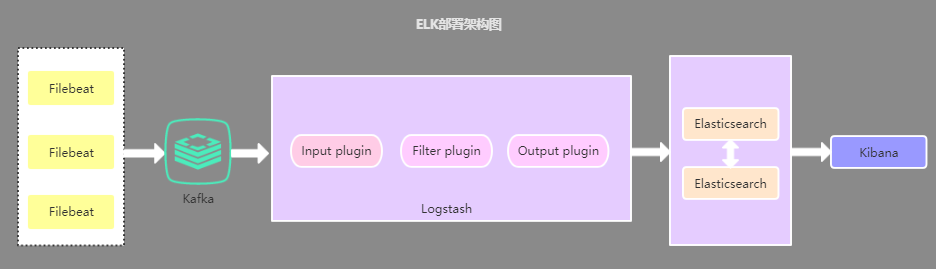
4、以上三种架构的总结
第一种部署架构由于资源占用问题,现已很少使用,目前使用最多的是第二种部署架构,至于第三种部署架构个人觉得没有必要引入消息队列,除非有其他需求,因为在数据量较大的情况下,Filebeat 使用压力敏感协议向 Logstash 或 Elasticsearch 发送数据。如果 Logstash 正在繁忙地处理数据,它会告知 Filebeat 减慢读取速度。拥塞解决后,Filebeat 将恢复初始速度并继续发送数据。