实时计算框架概述
以下是关于如何使用Storm、Kafka、Flume和Flink这些实时计算框架的一些基本信息:
- Storm:
- Storm是一个开源的分布式实时计算系统。它可以处理大量的数据流,并且具有高可靠性和可扩展性。
- Storm的应用包括实时计算,数据被一条一条地计算,实时收集、实时计算、实时展示。
- Kafka:
- Kafka是一个开源的分布式流处理平台,由LinkedIn开发并于2011年成为Apache项目。
- Kafka的使用包括创建Topic,发送消息,以及消费消息。
- Kafka还支持多语言,包括C/C++、PHP、Python、Go等。
- Flume:
- Flume是Cloudera开发的实时日志收集系统,受到了业界的认可与广泛应用。
- Flume的安装包括下载Flume,配置Flume,以及测试Flume。
- Flume的使用包括从内存中读取数据,从文件中读取数据,以及从端口读取数据。
- Flink:
- Flink是一个框架和分布式处理引擎,用于在无边界和有边界的数据流上进行有状态的计算。
- Flink的使用包括创建执行环境,读取数据源,数据转换,数据输出,以及启动任务
将框架连接起来完成一个实时计算任务
- 数据采集:使用Flume从各个节点上实时采集数据。Flume可以配置为监听特定的日志文件或者目录,然后将采集到的数据发送到Kafka。
- 数据接入:由于数据采集的速度和数据处理的速度可能不同步,因此需要添加一个消息中间件作为缓冲。这里我们使用Kafka来实现。你可以在Kafka中创建一个用于实时处理系统的topic,然后让Flume将采集到的数据发送到该topic上。
- 流式计算:对采集到的数据进行实时分析,这里我们使用Flink来实现。Flink可以从Kafka中读取数据,然后进行实时的数据处理。
- 数据输出:处理完的数据可以输出到其他系统进行存储或进一步的分析
Storm和Flink都可以进行流式计算。
- Storm:
- Storm是一个实时计算框架,它可以处理大量的数据流,并且具有高可靠性和可扩展性。
- 在Storm中,需要先设计一个实时计算结构,我们称之为拓扑(topology)。之后,这个拓扑结构会被提交给集群,其中主节点(master node)负责给工作节点(worker node)分配代码,工作节点负责执行代码。
- Flink:
- Flink是一个针对流数据和批数据的计算框架。
- Flink创造性地统一了流处理和批处理,作为流处理看待时输入数据流是无界的,而批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
这两个框架都可以进行流式计算,但是他们的处理方式和适用场景可能会有所不同。具体选择哪个框架,需要根据你的具体需求和应用场景来决定。在本任务中,我会设计两个方案,一个方案使用Storm,一个方案使用Flink,比较其性能。
环境搭建
在本次任务中使用Docker Desktop进行集群的搭建
Docker Desktop可前往官方网站进行下载:Docker Hub
下载到安装包之后建议使用命令行进行安装,使用命令行安装可以指定Docker Hub的安装位置,如果直接点击安装包会将docker安装到C盘。
1
2
3
| --installation-dir:选择默认安装位置
--windows-containers-default-data-root:选择指定 Windows 容器的默认位置
--wsl-default-data-root:指定 WSL 分发磁盘的默认位置
|
1
| C:\Windows\System32>start /w "" "P:\\Downloads\\Docker Desktop Installer.exe" install --installation-dir="P:\\Program Files\\Docker" --windows-containers-default-data-root="P:\\Program Files\\containers" --wsl-default-data-root="P:\\Program Files\\wsl"
|
安装成功后,可以打开PowerShell并运行docker -v,查看docker版本

搭建Zookeeper集群
使用docker-compose进行Zookeeper集群的搭建。
首先新建一个yml文件,将其命名为zookeeper-compose.yml文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| version: '3.7'
# 给zk集群配置一个网络,网络名为zk-net
networks:
zk-net:
name: zk-net
# 配置zk集群的container services下的每一个子配置都对应一个zk节点的docker container
services:
zk1:
# docker container所使用的docker image
image: zookeeper
hostname: zk1
container_name: zk1
# 配置docker container和宿主机的端口映射
ports:
- 2181:2181
- 8081:8080
# 配置docker container的环境变量
environment:
# 当前zk实例的id
ZOO_MY_ID: 1
# 整个zk集群的机器、端口列表
ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
# 将docker container上的路径挂载到宿主机上 实现宿主机和docker container的数据共享
volumes:
- ./zk1/data:/data
- ./zk1/datalog:/datalog
# 当前docker container加入名为zk-net的隔离网络
networks:
- zk-net
zk2:
image: zookeeper
hostname: zk2
container_name: zk2
ports:
- 2182:2181
- 8082:8080
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zk3:2888:3888;2181
volumes:
- ./zk2/data:/data
- ./zk2/datalog:/datalog
networks:
- zk-net
zk3:
image: zookeeper
hostname: zk3
container_name: zk3
ports:
- 2183:2181
- 8083:8080
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181
volumes:
- ./zk3/data:/data
- ./zk3/datalog:/datalog
networks:
- zk-net
|
然后在PowerShell使用docker-compose安装zookeeper-compose.yml。
1
| docker-compose -f .\zookeeper-compose.yml up -d
|
输入docker ps查看是否安装成功

分别进入zk1,zk2,zk3,查看他们是否形成集群
1
2
| docker exec -it zk1 /bin/bash
zkServer.sh status
|

结果为follower,成功连接集群。
输入exit退出容器,进入zk2

zk2也连接集群成功
进入zk3

zk3也成功连接集群成功,并且是leader。
至此zookeeper集群搭建成功。
安装成功后,使用zookeeper java api查看是否能连接成功。
1
2
3
4
5
| <dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.9.1</version>
</dependency>
|
API Client1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| package org.example.kafka;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
public class ZookeeperClientExample {
private static final String CONNECT_STRING = "localhost:2181";
private static final int SESSION_TIMEOUT = 5000;
private static final CountDownLatch connectedSignal = new CountDownLatch(1);
public static void main(String[] args) {
ZooKeeper zk = null;
try {
zk = new ZooKeeper(CONNECT_STRING, SESSION_TIMEOUT, new Watcher() {
public void process(WatchedEvent event) {
if (event.getState() == Watcher.Event.KeeperState.SyncConnected) {
System.out.println("连接成功!");
connectedSignal.countDown();
}
}
});
connectedSignal.await();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (zk != null) {
try {
zk.close();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
|
查看输出:
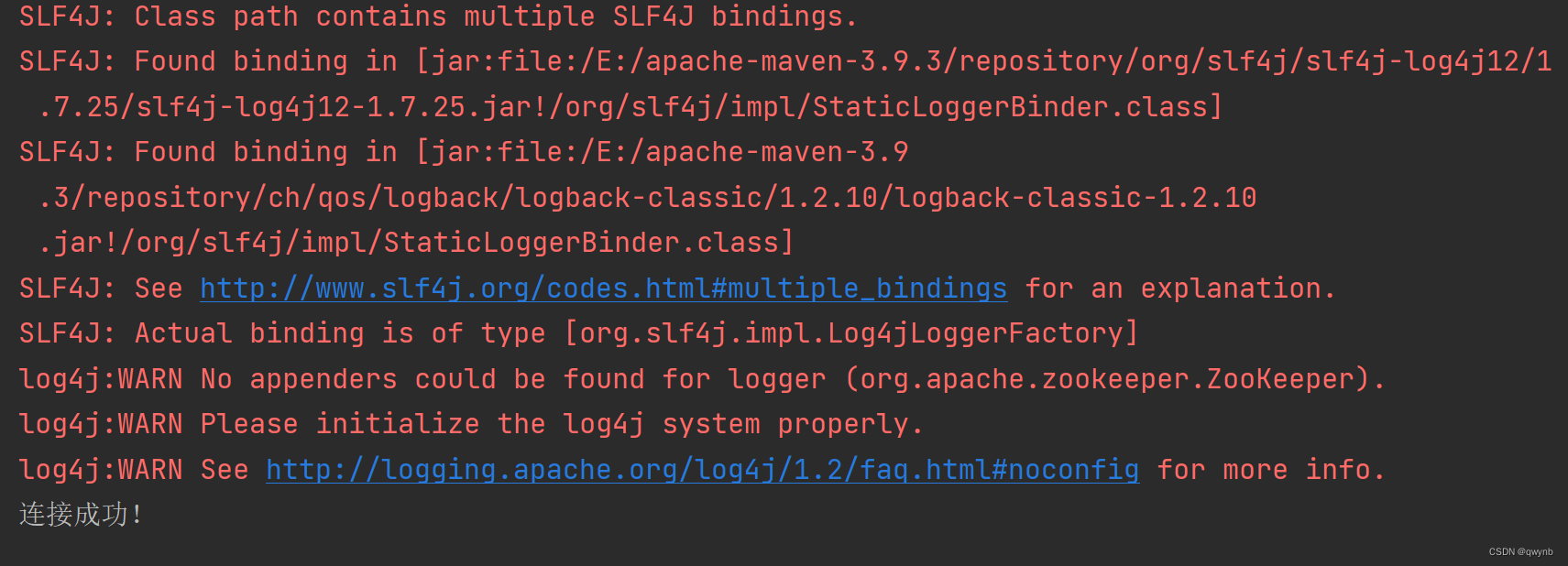
如果连接成功就代表zookeeper集群安装成功。
搭建Kafka集群
使用docker-compose进行集群的安装
新建一个yml文件,命名为kafka-compose.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| version: '3'
services:
kafka1:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zk1:2181,zk2:2181,zk3:2181
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka1:9092,OUTSIDE://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9093
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- zk-net
kafka2:
image: wurstmeister/kafka
ports:
- "9093:9093"
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zk1:2181,zk2:2181,zk3:2181
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka2:9092,OUTSIDE://localhost:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9093
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- zk-net
kafka3:
image: wurstmeister/kafka
ports:
- "9094:9094"
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zk1:2181,zk2:2181,zk3:2181
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka3:9092,OUTSIDE://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9093
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- zk-net
networks:
zk-net:
external: true
|
使用docker ps查看正在运行的容器
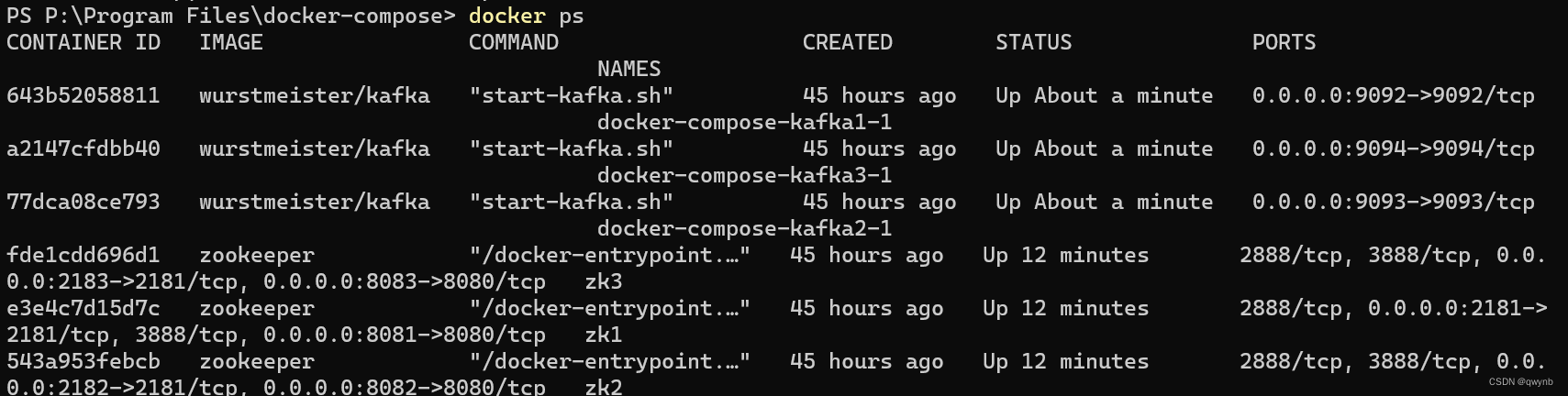
使用kafka java api查看是否能连接成功
1
2
3
4
5
| <dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.1</version>
</dependency>
|
Java API1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| package org.example.kafka;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import java.util.Properties;
public class KafkaConnectionTest {
private static final String KAFKA_CONNECTION_STRING = "localhost:9093";
//private static final String KAFKA_CONNECTION_STRING = "localhost:9092";
//private static final String KAFKA_CONNECTION_STRING = "localhost:9094";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_CONNECTION_STRING);
try (AdminClient adminClient = AdminClient.create(properties)) {
adminClient.listTopics().names().get();
System.out.println("成功连接到Kafka!");
} catch (Exception e) {
System.out.println("无法连接到Kafka!");
System.out.println("连接Kafka时发生错误: " + e.getMessage());
}
}
}
|
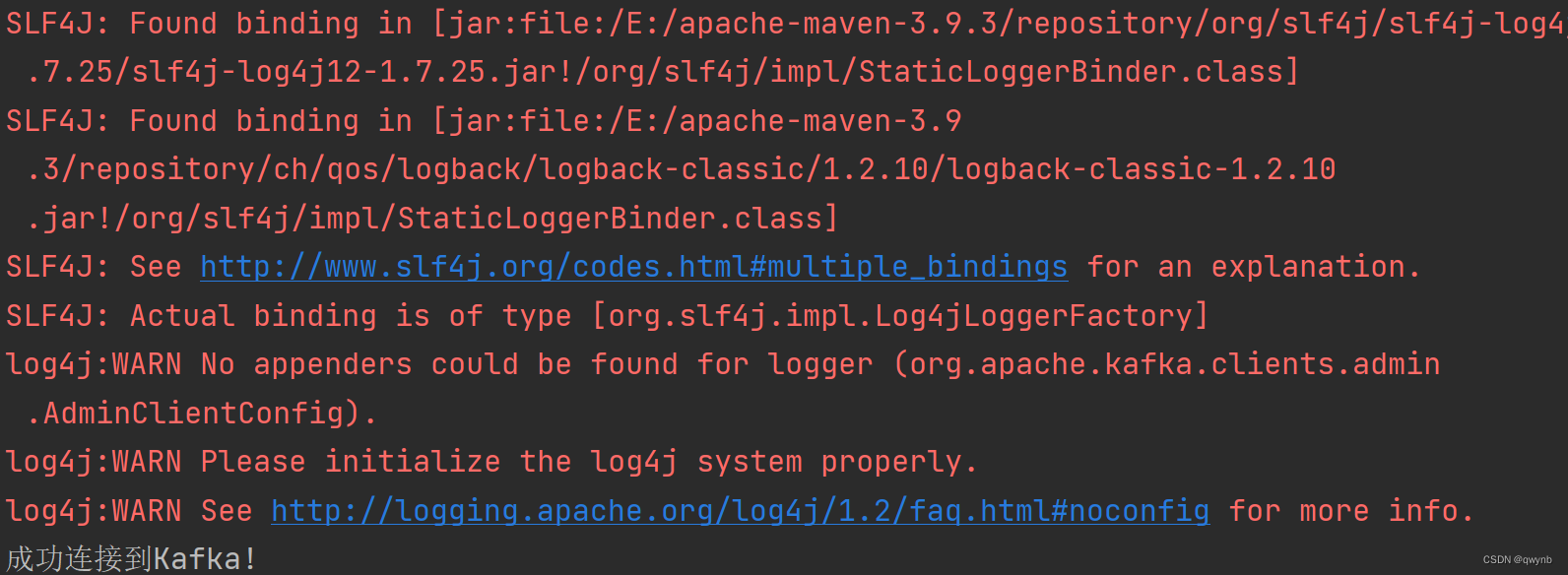
如果连接失败,可以尝试使用
localhost:9093和localhost:9094
成功连接代表安装成功。
安装成功之后,进入kafka容器,新建一个名为new-topic的主题。
1
2
| docker exec -it docker-compose-kafka1-1 /bin/bash
kafka-topics.sh --zookeeper zk1:2181,zk2:2181,zk3:2181 --create --topic new-topic --partitions 9 --replication-factor 2
|
–zookeeper zk1:2181,zk2:2181,zk3:2181 指定了Zookeeper的地址和端口
–create 表示我们要创建一个新的主题。
–topic new-topic 指定了新主题的名称。
–partitions 9 指定了新主题应该有9个分区,分区数量最好是kafka集群数量的倍数。
–replication-factor 2 指定了每个分区应该有2个副本。
创建成功时,会提示:Created topic my-topic。
搭建storm集群(可以不安装)
在 Storm 集群中,Nimbus 是用于协调拓扑任务的主节点,而 Supervisor 是用于执行拓扑任务的工作节点。通常情况下,Supervisor 的数量应该大于或等于 Nimbus 的数量以实现更好的负载均衡和容错性。
对于一个 Storm 集群,至少需要一个 Nimbus 节点和一个 Supervisor 节点。然而,为了实现高可用性和容错性,建议至少设置两个 Nimbus 节点。
我在storm集群中安装了两个Nimbus 节点和三个Supervisor 节点。
首先要在目录下新建一个storm.yaml文件
1
2
3
4
5
| storm.zookeeper.servers:
- "zk1"
- "zk2"
- "zk3"
nimbus.seeds: ["nimbus","nimbus2"]
|
使用docker-compose安装storm集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| version: '3.1'
services:
nimbus:
image: storm
container_name: nimbus
command: storm nimbus
volumes:
- "./storm.yaml:/conf/storm.yaml"
- "./nimbus/data:/data"
- "./nimbus/logs:/logs"
restart: always
ports:
- 6627:6627
networks:
- zk-net
nimbus2:
image: storm
container_name: nimbus2
command: storm nimbus
volumes:
- "./storm.yaml:/conf/storm.yaml"
- "./nimbus2/data:/data"
- "./nimbus2/logs:/logs"
restart: always
ports:
- 6628:6627
networks:
- zk-net
supervisor:
image: storm
container_name: supervisor
command: storm supervisor
depends_on:
- nimbus
- nimbus2
links:
- nimbus
- nimbus2
volumes:
- "./storm.yaml:/conf/storm.yaml"
- "./supervisor/data:/data"
- "./supervisor/logs:/logs"
networks:
- zk-net
restart: always
supervisor2:
image: storm
container_name: supervisor2
command: storm supervisor
depends_on:
- nimbus
- nimbus2
links:
- nimbus
- nimbus2
volumes:
- "./storm.yaml:/conf/storm.yaml"
- "./supervisor2/data:/data"
- "./supervisor2/logs:/logs"
networks:
- zk-net
restart: always
supervisor3:
image: storm
container_name: supervisor3
command: storm supervisor
depends_on:
- nimbus
- nimbus2
links:
- nimbus
- nimbus2
volumes:
- "./storm.yaml:/conf/storm.yaml"
- "./supervisor3/data:/data"
- "./supervisor3/logs:/logs"
networks:
- zk-net
restart: always
networks:
zk-net:
external: true
|
安装storm ui查看storm是否安装成功
在PowerShell中输入
1
| docker run -d -p 8080:8080 --network zk-net --restart always --name ui --link nimbus:nimbus storm storm ui
|

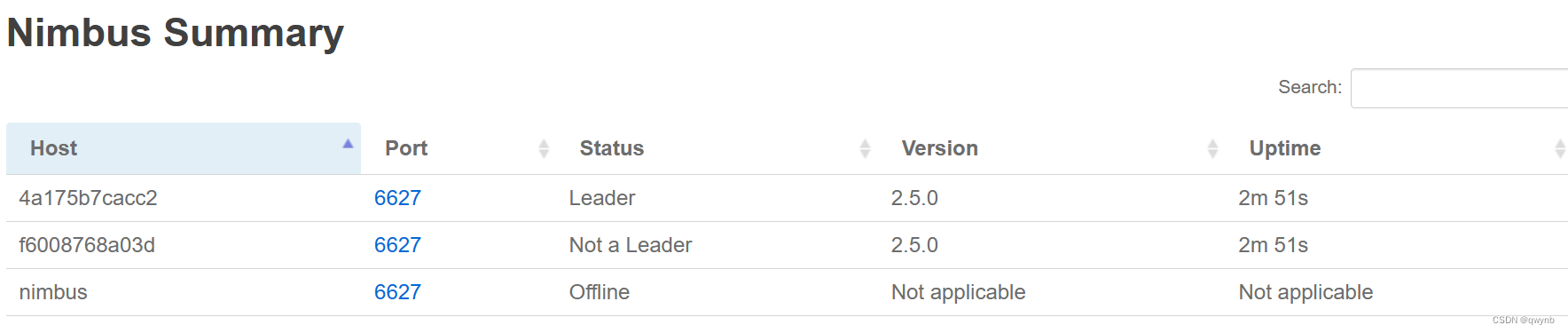
安装完成后在浏览器中输入 localhost:8080 Storm UI
可以看到有两个nimbus
还能看到三个 Supervisor
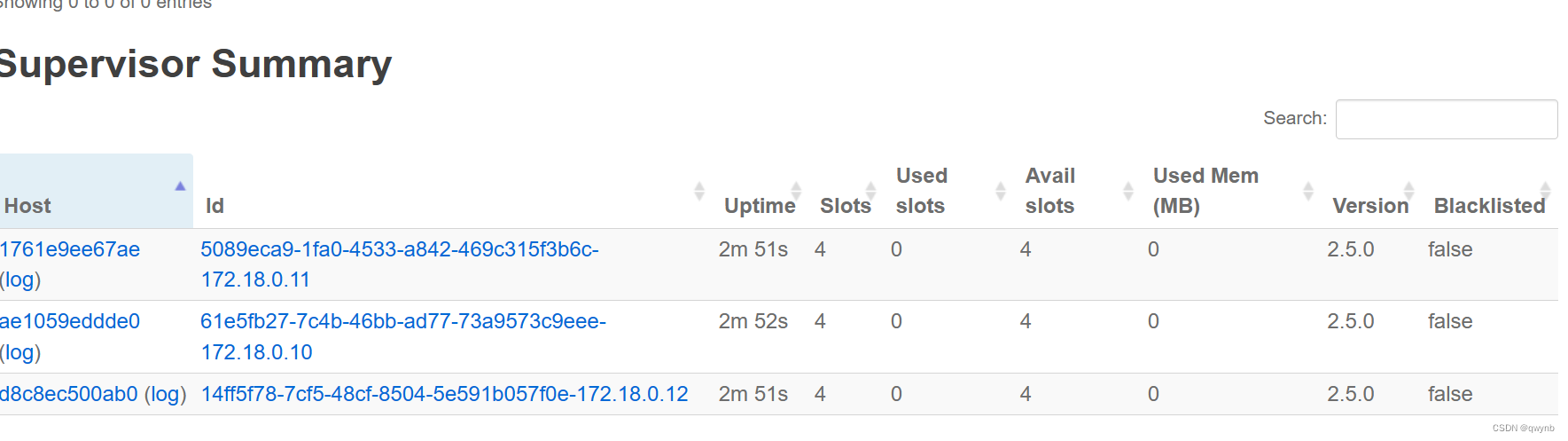
strom集群安装成功
搭建Flink集群
在 Flink 集群中,JobManager 和 TaskManager 是两种不同的角色,各自承担着不同的任务和职责。
JobManager(作业管理器):
- JobManager 是 Flink 集群的主节点,负责协调和管理整个 Flink 作业的执行。
- JobManager 接收并调度提交的作业,将作业划分为多个不同的任务(task)并分配给 TaskManager 执行。
- JobManager 还负责协调任务的状态、处理任务的故障恢复、协调检查点(checkpoint)等重要的集群级别的操作和任务调度。
- JobManager 同时提供了 Flink 的 Web UI,用于监控和管理作业的执行状态、度量指标和日志等。
TaskManager(任务管理器):
- TaskManager 是 Flink 集群中的工作节点,负责执行 JobManager 分配给它的任务。
- TaskManager 接收来自 JobManager 的任务,并在本地执行任务的计算逻辑。
- TaskManager 还负责将任务结果返回给 JobManager,并与其进行通信和协调。
- TaskManager 在执行任务时,可以并行执行多个任务,并提供了资源管理和任务隔离的功能。
- Flink 集群中可以有多个 TaskManager,以便并行执行多个任务,实现高吞吐量和可伸缩性。
在 Flink 集群中,JobManager 和 TaskManager 协同工作,共同完成作业的执行。JobManager 负责作业的管理和调度,而 TaskManager 负责实际的任务执行。通过将任务分配给不同的 TaskManager,Flink 可以实现任务级别的并行处理,并提供高可用性和容错性来保证作业的稳定执行。
我在Flink 集群启动了一个jobmanager和三个taskmanager
新建一个Flink-compose.yml文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| version: '3'
services:
jobmanager:
image: flink
command: jobmanager
ports:
- "8085:8081"
jobmanager2:
image: flink
command: jobmanager
taskmanager1:
image: flink
command: taskmanager
depends_on:
- jobmanager
- jobmanager2
taskmanager2:
image: flink
command: taskmanager
depends_on:
- jobmanager
- jobmanager2
taskmanager3:
image: flink
command: taskmanager
depends_on:
- jobmanager
- jobmanager2
|
在PowerShell中安装compose文件
docker-compose -f .\Flink-compose.yml up -d
安装完成后,访问Flink UI localhost:8085 Apache Flink Web Dashboard
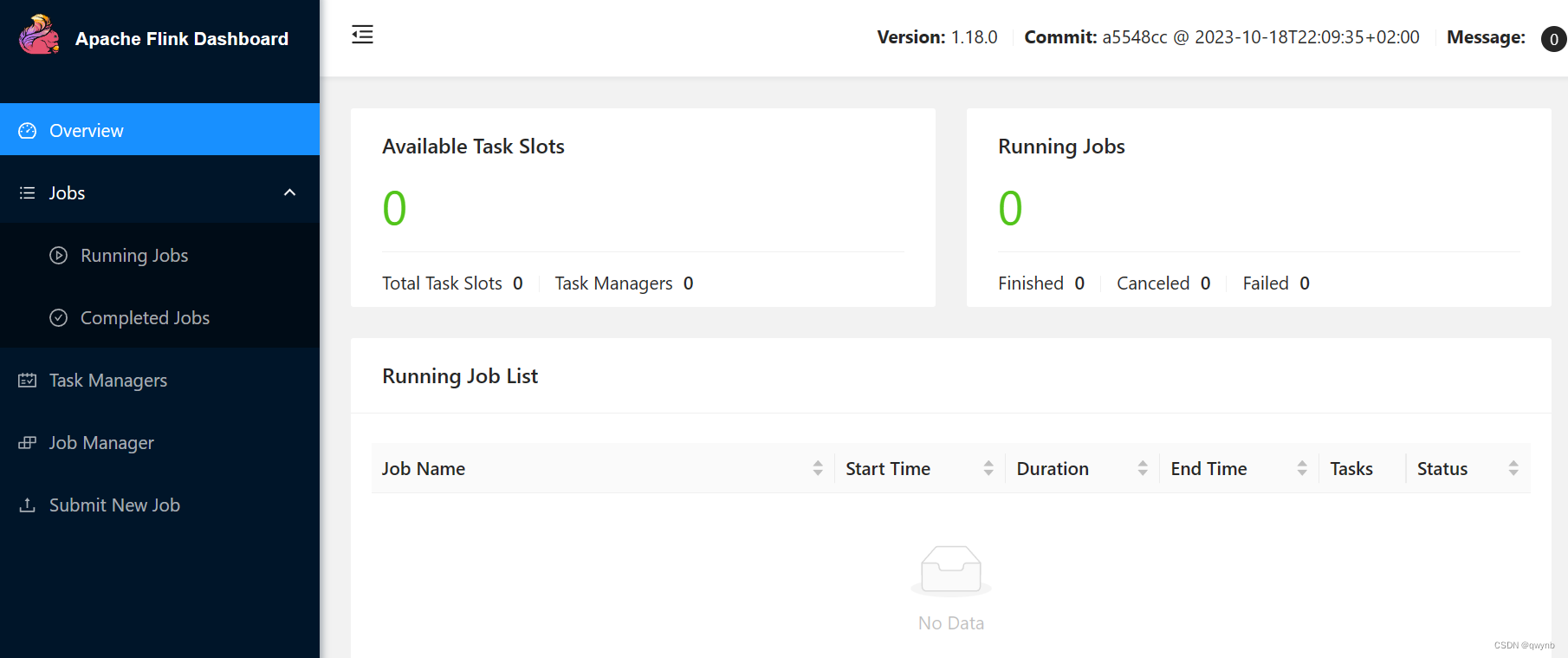
能够访问网站代表安装成功。
搭建 Flume集群
一个典型的 Flume 集群由多个 Agent 组成,每个 Agent 包含一个 Source、一个或多个 Channel 和一个或多个 Sink。通过组合和配置这些组件,可以构建适合特定数据流需求的 Flume 集群。
在本次任务中,我会搭建3个Agent
新建一个docker-compose文件,命名为Flume-compose.yml
再新建一个flume-conf目录,在目录下新建三个配置文件
我需要把Flume获取到的数据输出到kafka中,所有需要在配置文件中设置Flume的输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 定义Flume agent的名称和组件
agent1.sources = avro-source
agent1.channels = memory-channel
agent1.sinks = kafka-sink
# 配置Avro源
agent1.sources.avro-source.type = avro
agent1.sources.avro-source.bind = 0.0.0.0
agent1.sources.avro-source.port = 44444
agent1.sources.avro-source.channels = memory-channel
# 配置内存通道
agent1.channels.memory-channel.type = memory
agent1.channels.memory-channel.capacity = 10000
agent1.channels.memory-channel.transactionCapacity = 1000
# 配置负载均衡选择器
agent1.sources.avro-source.selector.type = replicating
# 配置Kafka汇
agent1.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafka-sink.kafka.topic = new-topic
agent1.sinks.kafka-sink.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092
agent1.sinks.kafka-sink.kafka.flumeBatchSize = 100
agent1.sinks.kafka-sink.channel = memory-channel
# 将组件连接起来
agent1.sources.avro-source.channels = memory-channel
agent1.sinks.kafka-sink.channel = memory-channel
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 定义Flume agent的名称和组件
agent2.sources = avro-source
agent2.channels = memory-channel
agent2.sinks = kafka-sink
# 配置Avro源
agent2.sources.avro-source.type = avro
agent2.sources.avro-source.bind = 0.0.0.0
agent2.sources.avro-source.port = 44445
agent2.sources.avro-source.channels = memory-channel
# 配置内存通道
agent2.channels.memory-channel.type = memory
agent2.channels.memory-channel.capacity = 10000
agent2.channels.memory-channel.transactionCapacity = 1000
# 配置负载均衡选择器
agent2.sources.avro-source.selector.type = replicating
# 配置Kafka汇
agent2.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
agent2.sinks.kafka-sink.kafka.topic = new-topic
agent2.sinks.kafka-sink.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092
agent2.sinks.kafka-sink.kafka.flumeBatchSize = 100
agent2.sinks.kafka-sink.channel = memory-channel
# 将组件连接起来
agent2.sources.avro-source.channels = memory-channel
agent2.sinks.kafka-sink.channel = memory-channel
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 定义Flume agent的名称和组件
agent3.sources = avro-source
agent3.channels = memory-channel
agent3.sinks = kafka-sink
# 配置Avro源
agent3.sources.avro-source.type = avro
agent3.sources.avro-source.bind = 0.0.0.0
agent3.sources.avro-source.port = 44446
agent3.sources.avro-source.channels = memory-channel
# 配置内存通道
agent3.channels.memory-channel.type = memory
agent3.channels.memory-channel.capacity = 10000
agent3.channels.memory-channel.transactionCapacity = 1000
# 配置负载均衡选择器
agent3.sources.avro-source.selector.type = replicating
# 配置Kafka汇
agent3.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
agent3.sinks.kafka-sink.kafka.topic = new-topic
agent3.sinks.kafka-sink.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092
agent3.sinks.kafka-sink.kafka.flumeBatchSize = 100
agent3.sinks.kafka-sink.channel = memory-channel
# 将组件连接起来
agent3.sources.avro-source.channels = memory-channel
agent3.sinks.kafka-sink.channel = memory-channel
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| version: '3'
services:
flume1:
image: probablyfine/flume:latest
volumes:
- ./flume-conf/flume1.conf:/opt/flume-config/flume.conf
environment:
- FLUME_AGENT_NAME=agent1
ports:
- "44444:44444"
flume2:
image: probablyfine/flume:latest
volumes:
- ./flume-conf/flume2.conf:/opt/flume-config/flume.conf
environment:
- FLUME_AGENT_NAME=agent2
ports:
- "44445:44445"
flume3:
image: probablyfine/flume:latest
volumes:
- ./flume-conf/flume3.conf:/opt/flume-config/flume.conf
environment:
- FLUME_AGENT_NAME=agent3
ports:
- "44446:44446"
|
在PowerShell中安装compose文件
1
| docker-compose -f .\Flume-compose.yml up -d
|
采集数据
使用Flume将消息传递给Kafka有几个主要的原因:
数据源多样性:Flume支持多种数据源,包括日志文件、网络流、社交媒体流等。这使得Flume可以从各种各样的数据源中获取数据,并将其传递给Kafka。
可靠性:Flume提供了可靠的数据传输机制。即使在面临网络问题或系统故障时,Flume也能确保数据不会丢失。
分布式:Flume是一个分布式系统,可以处理大量的日志数据。通过将数据分布在多个agent上,Flume可以提高数据处理的效率。
易于集成:Flume与Kafka的集成非常简单,只需要在Flume的配置文件中设置相应的参数,就可以将数据发送到Kafka。
负载均衡和容错:Flume支持负载均衡和容错。这意味着,如果某个Flume agent失败,其他的agent可以接管它的工作。同时,Flume还可以将数据均匀地分配到多个sink,从而防止某个sink过载。
因此,使用Flume读取数据并将其传递给Kafka是一种有效的方式,可以确保数据的可靠性,提高数据处理的效率,同时还可以简化系统的集成和管理。
数据会使用股票交易数据模拟器进行生成。模拟器会放在代码仓库中。
现在需要使用flume实时监控并将数据发送给kafka
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
| package org.example.readcsv;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.FlumeException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.io.*;
import java.nio.file.*;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FlumeRpcClientExample {
private static final String FLUME_HOST = "localhost";
private static final int[] FLUME_PORTS = {44444, 44445, 44446}; // 替换为Flume监听的端口
private static final String FLUME_HEADERS = ""; // 添加需要的Flume头部信息
public static void main(String[] args) {
String folderPath = "P:\\data\\temp"; // 替换为CSV文件所在的文件夹路径
sendCSVFile(folderPath);
}
private static void sendCSVFile(String folderPath) {
try {
File folder = new File(folderPath);
File[] listOfFiles = folder.listFiles();
RpcClient[] clients = new RpcClient[3];
clients[0]=RpcClientFactory.getDefaultInstance(FLUME_HOST, FLUME_PORTS[0]);
clients[1]=RpcClientFactory.getDefaultInstance(FLUME_HOST, FLUME_PORTS[1]);
clients[2]=RpcClientFactory.getDefaultInstance(FLUME_HOST, FLUME_PORTS[2]);
// 首先发送所有已经有的数据
int count;
int total=0;
ExecutorService executor = Executors.newFixedThreadPool(30); // 创建一个固定大小的线程池
for (File file : listOfFiles) {
if (file.isFile() && file.getName().endsWith(".csv")) {
executor.submit(() -> { // 在一个新的线程中执行
int count_port = 0;
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file), "gbk"));
String line = reader.readLine();
count_port = 0;
while (line != null) {
RpcClient client = clients[count_port % FLUME_PORTS.length];
Event flumeEvent = EventBuilder.withBody(line.getBytes());
client.append(flumeEvent);
line = reader.readLine();
count_port++;
}
reader.close();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(count_port);
});
}
}
executor.shutdown(); // 关闭线程池
while (!executor.isTerminated()) {} // 等待所有任务完成
System.out.println(total);
// for (File file : listOfFiles) {
// if (file.isFile() && file.getName().endsWith(".csv")) {
// BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file), "gbk"));
// String line = reader.readLine();
// count=0;
// while (line != null) {
System.out.println("当前的数据: " + line);
// RpcClient client = clients[count % FLUME_PORTS.length];
// Event flumeEvent = EventBuilder.withBody(line.getBytes());
// client.append(flumeEvent);
// line = reader.readLine();
// count++;
// total++;
// }
// reader.close();
// }
// System.out.println(total);
// }
WatchService watchService = FileSystems.getDefault().newWatchService();
// 注册要监视的路径和事件类型到WatchService对象中
Path dirPath = folder.toPath();
dirPath.register(watchService, StandardWatchEventKinds.ENTRY_CREATE, StandardWatchEventKinds.ENTRY_DELETE, StandardWatchEventKinds.ENTRY_MODIFY);
// 创建一个Map对象,用于存储每个文件的BufferedReader和上一次长度
Map<String, BufferedReader> readers = new HashMap<>();
Map<String, Long> lastLengths = new HashMap<>();
while (true) {
WatchKey watchKey = watchService.take();
// 获取一个WatchEventList对象
for (WatchEvent<?> event : watchKey.pollEvents()) {
// 判断事件类型
if (event.kind() == StandardWatchEventKinds.ENTRY_MODIFY) {
// 如果是文件修改事件,则读取文件的新内容
Path filePath = dirPath.resolve((Path) event.context());
if (filePath.toString().endsWith(".csv")) {
File file = filePath.toFile();
long length = file.length();
if (!readers.containsKey(filePath.toString())) {
// 如果是新的文件,则创建一个新的BufferedReader对象
RandomAccessFile raf = new RandomAccessFile(file, "r");
readers.put(filePath.toString(), new BufferedReader(new InputStreamReader(new FileInputStream(raf.getFD()), "GBK")));
lastLengths.put(filePath.toString(), 0L);
}
BufferedReader reader;
long lastLength = lastLengths.get(filePath.toString());
if (length > lastLength) {
// 文件有新增的数据
RandomAccessFile raf = new RandomAccessFile(file, "r");
raf.seek(lastLength); // 将文件指针移动到上一次读取的位置
reader = new BufferedReader(new InputStreamReader(new FileInputStream(raf.getFD()), "GBK")); // 从上一次读取的位置开始创建一个新的BufferedReader对象
String line;
count=0;
while ((line = reader.readLine()) != null) {
RpcClient client = clients[count % FLUME_PORTS.length];
Event flumeEvent = EventBuilder.withBody(line.getBytes());
client.append(flumeEvent);
// System.out.println(line);
count++;
}
// 更新文件的上一次长度
lastLengths.put(filePath.toString(), length);
}
}
}
}
// 重置watchKey状态为ready,以便继续监听事件
if (!watchKey.reset()) {
break;
}
}
} catch (IOException | InterruptedException | EventDeliveryException e) {
e.printStackTrace();
}
}
}
|
需要把`String folderPath = “P:\data\temp”替换为CSV所在的文件夹路径
然后在java代码中启动kafka消费者,如果有数据出现则代表数据发送成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
private static final String KAFKA_CONNECTION_STRING = "localhost:9093";
private static final String TOPIC_NAME = "new-topic";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_CONNECTION_STRING);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "testGroup");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
records.forEach(record -> {
System.out.printf("Topic: %s, Partition: %s, Offset: %s, Key: %s, Value: %s%n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
});
}
}
}
}
|
可以查看到已经有数据出现了。
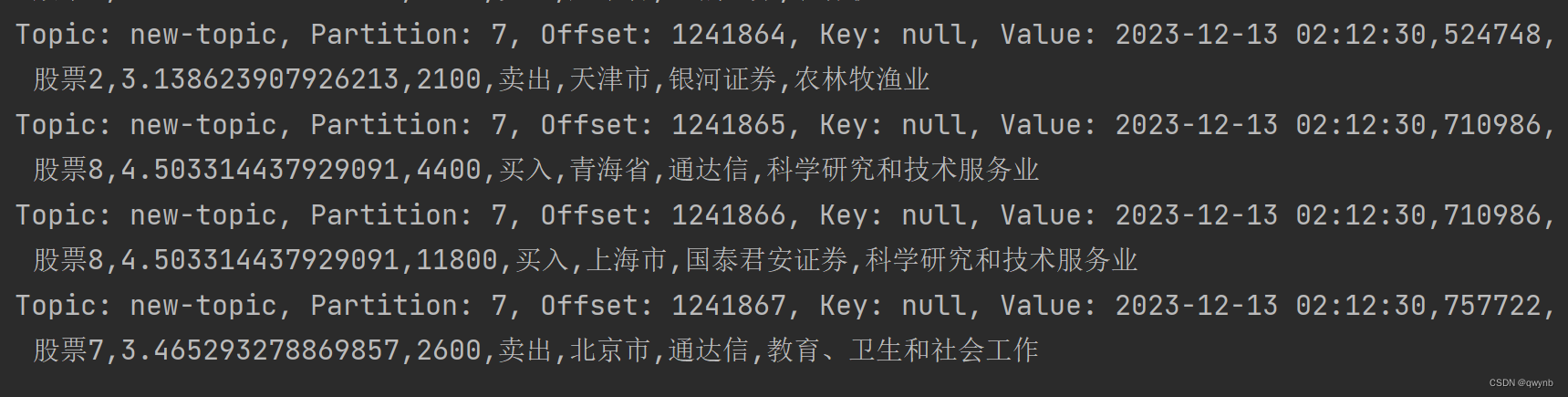
说明Flume已经配置成功了。
数据计算
Flink和Storm都是分布式实时计算框架,但是Flink的程序更加简单,api支持完善,并且Flink UI的界面功能非常完善。所以在本次任务中我选择了Flink框架。
我的Flink计算结果会存储到数据库中,所有代码已经开源至仓库,可自行查看。
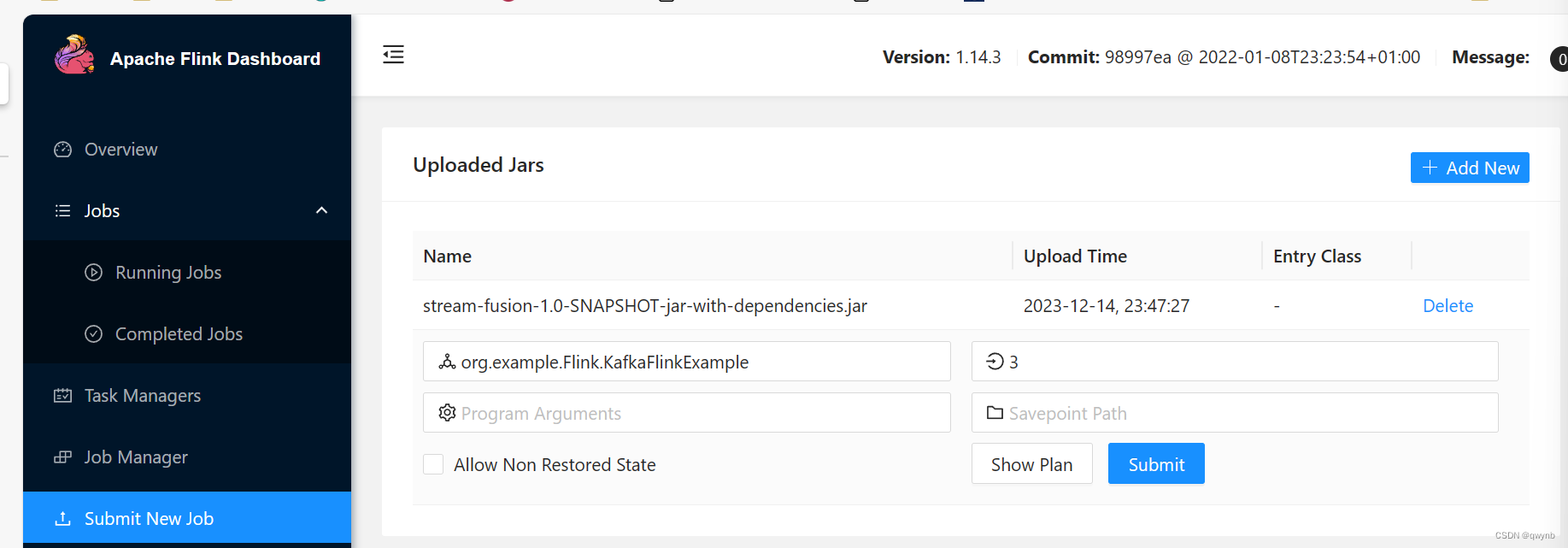
把代码写完之后,将代码打包成jar包上传
选择Flink计算类和并行度。
并行度建议与taskmanager节点的数量相同,本次任务中我选择的是3。
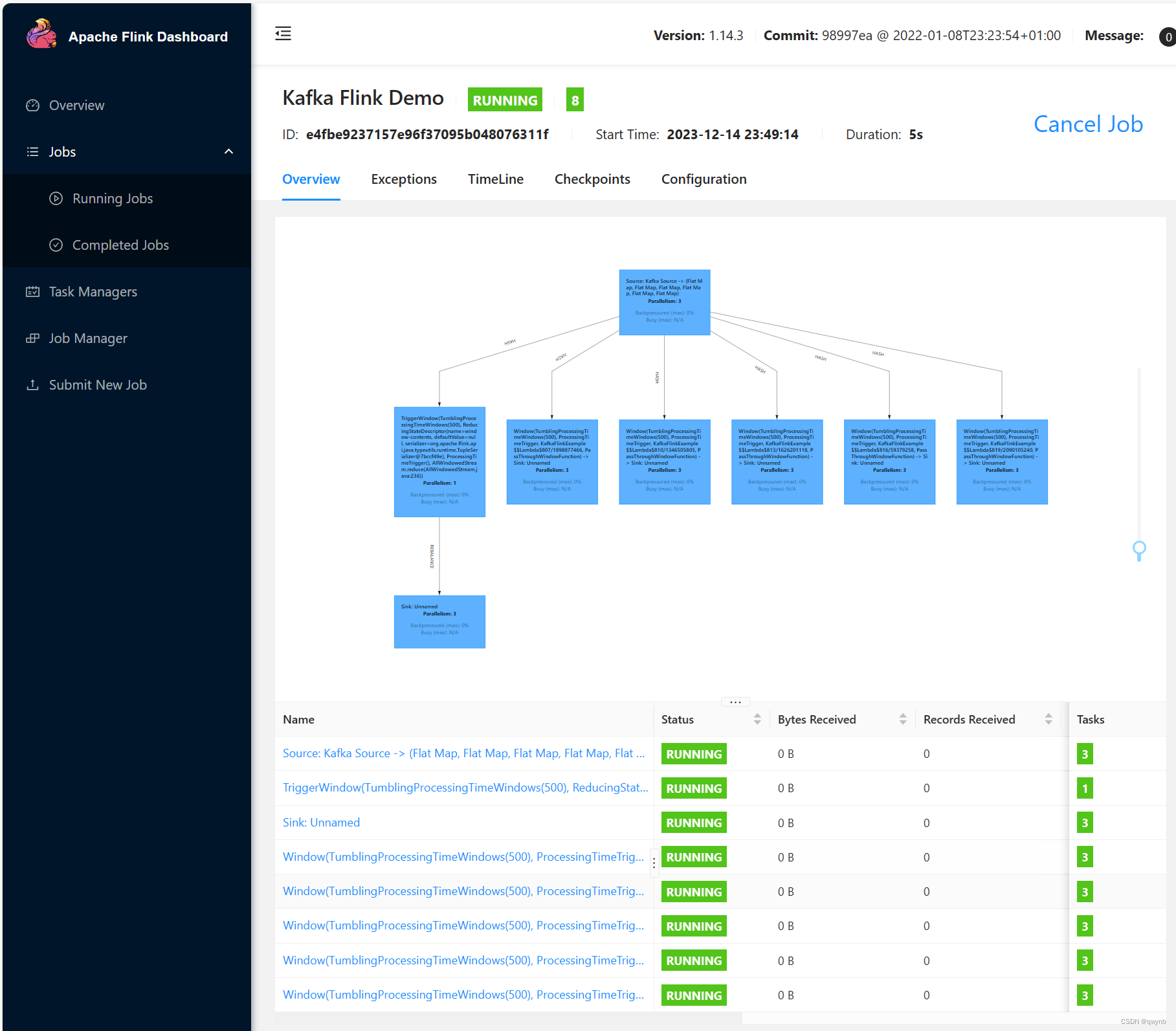
提交之后就能看到所有节点的运行状态。
现在打开数据库,就能看到Flink计算得到的结果了。
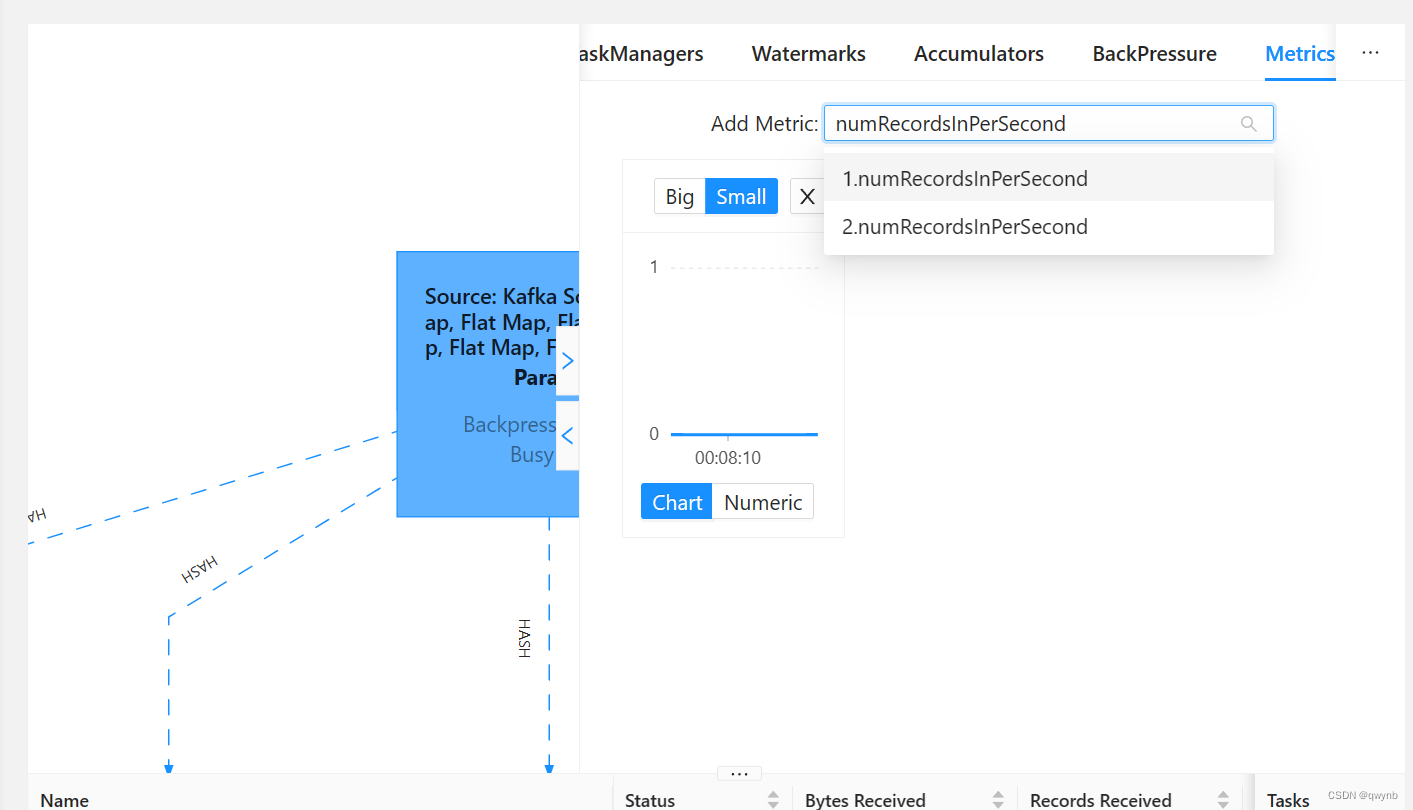
在任务运行时,点击最上方的数据源,输入numRecordsInPerSecond就可以查看每秒从数据源(例如Kafka)读取的记录数量。
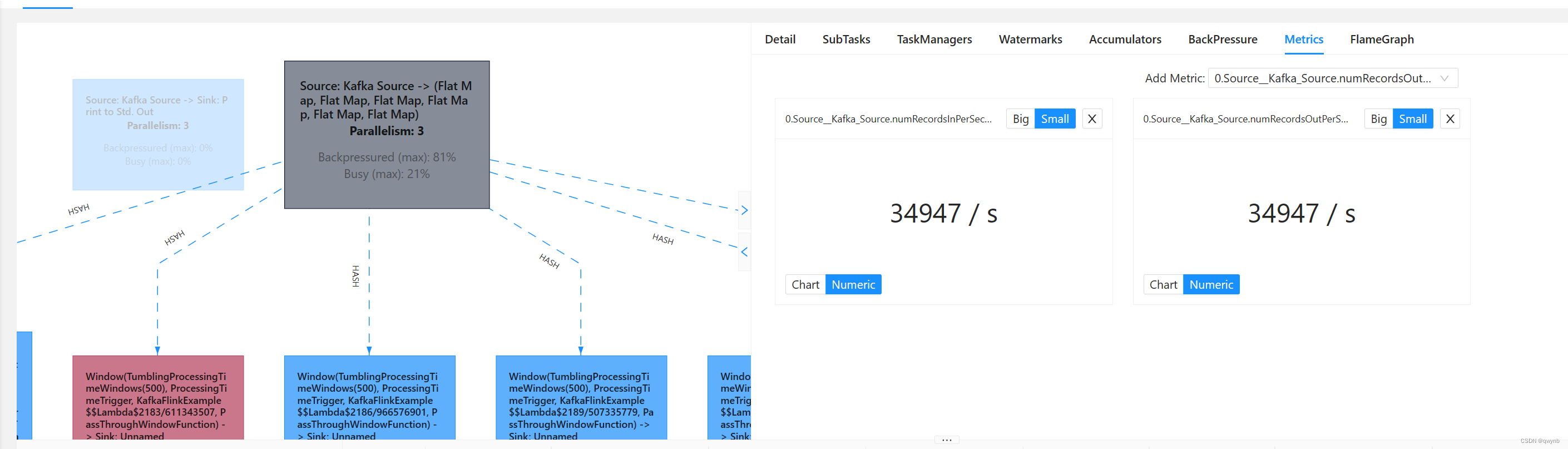
然后启动Flume读取数据,就可以在右侧看到性能参数。
数据展示
接下来,使用spring boot搭建一个数据看板用于展示数据,代码已经开源至仓库。
效果展示:

至此项目结束。
参考文献或转载相关:
原文链接:https://blog.csdn.net/qq_67209161/article/details/134764593