kafka开源分布式流处理平台技术
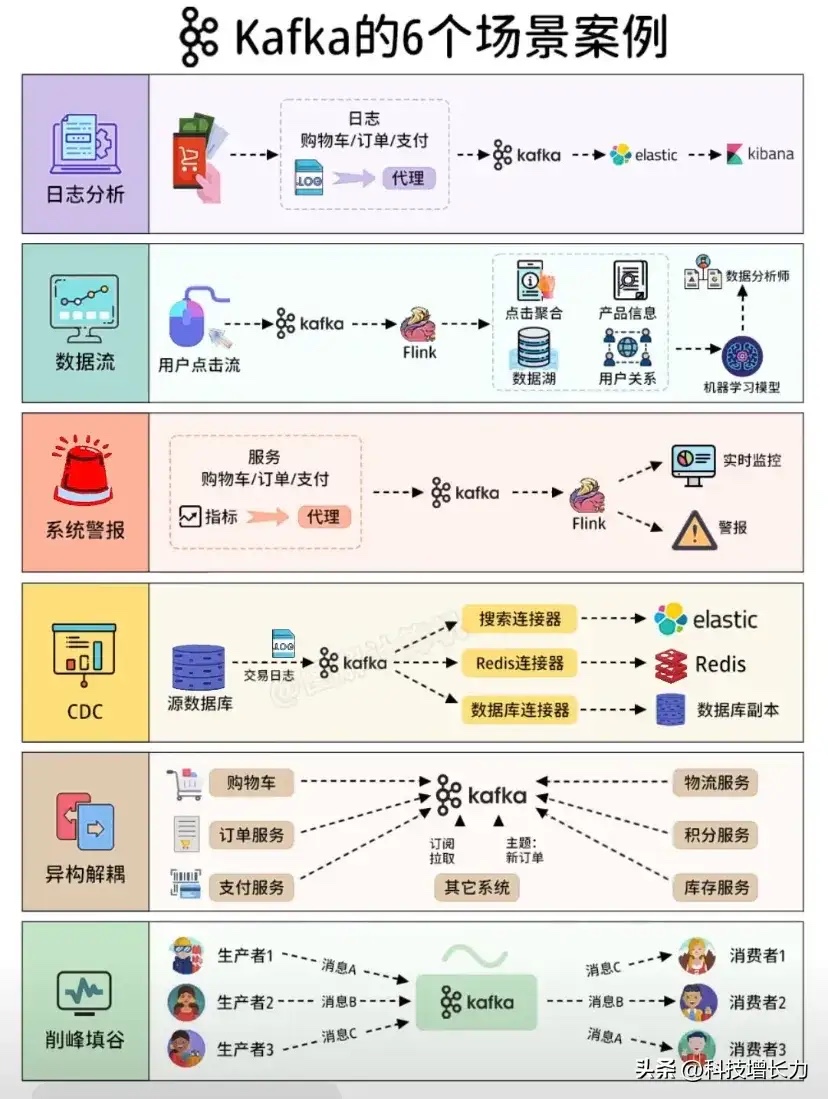
Kafka的常见场景案例介绍:
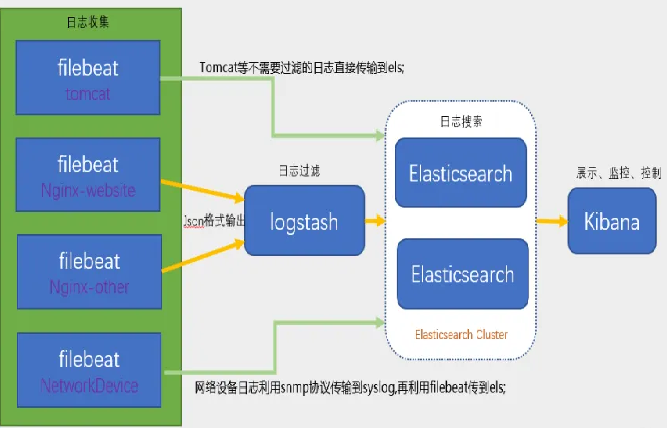
日志分析
• 流程:购物车、订单、支付等操作产生的日志(如日志文件LOG)通过代理传输到Kafka,然后Kafka将数据传递给Elastic,最后在Kibana中进行展示和分析。
• 用途:用于收集和分析系统产生的大量日志数据,帮助开发者和运维人员了解系统的运行状况、排查问题等。
数据流
• 流程:用户的点击流数据先进入Kafka,再由Kafka传递给Flink进行处理,处理后的数据存储在数据湖(包含点击聚合、产品信息、用户关系等)中,最后供数据分析师使用,并可用于机器学习模型的训练等。
• 用途:实时处理用户的行为数据,为业务决策、用户画像、个性化推荐等提供数据支持。
系统警报
• 流程:购物车、订单、支付等服务的相关指标通过代理传输到Kafka,Kafka将数据传递给Flink进行处理,然后进行实时监控,当出现异常情况时发出警报。
• 用途:对关键业务指标进行实时监控,及时发现系统故障、性能问题等,并发出警报以便快速响应和处理。
CDC(Change Data Capture,变更数据捕获)
• 流程:源数据库中的交易日志等数据通过Kafka进行传输,然后利用搜索连接器传输到Elastic,利用Redis连接器传输到Redis,利用数据库连接器传输到数据库副本。
• 用途:捕获数据库中的数据变更,并将这些变更同步到其他系统中,实现数据的实时同步和备份等。
异构解耦
• 流程:购物车、订单服务、支付服务等产生的数据通过Kafka进行传输,Kafka将数据传递给物流服务、积分服务、库存服务等其他系统,通过订阅拉取的方式实现解耦。
• 用途:在复杂的分布式系统中,将不同的服务(如购物车、订单、支付等)与其他相关服务(如物流、积分、库存等)进行解耦,使得各个服务可以独立开发、部署和扩展,而不相互影响。
削峰填谷
• 流程:生产者(如生产者1、生产者2、生产者3)产生的消息(消息A、消息B、消息C)先发送到Kafka中,然后消费者(如消费者1、消费者2、消费者3)从Kafka中拉取消息进行处理。
• 用途:在高并发的场景下,通过Kafka作为消息中间件,缓冲生产者产生的大量消息,避免消费者直接面对高并发的压力,实现削峰填谷的效果,保证系统的稳定性和可靠性。