Spring Boot趣味实战课学习内容
Spring Boot趣味实战课内容简介
计算机里的世界是现实世界的映射,或者是基于现实世界的演化。技术都是为了解决生活中的问题而诞生的,可以说一切技术都来源于生活。因此,学好技术要从生活入手。本书始终秉持着「技术来源于生活,更要归于生活」的理念,让书中每一项技术都有生活中原型与之对应。用非常接地气的方式让读者更容易理解书中所讲述的技术。
本书内容极其丰富, 不仅涵盖了 Spring MVC、MyBatis Plus、Spring Data JPA、Spring Security、Quartz 等主流框架,整合了 MySQL、 Druid、 Redis、 RabbitMQ、 Elasticsearch 等互联网常用技术与中间件,还涉及单元测试、异常处理、日志、 Swagger 等技术细节,以及 AOP、 IOC、自动配置、数据库事务、分布式锁等硬核知识。本书从初始化到部署、监控,实现了软件全生命周期一站式打包解决。
本书行文风格深入浅出、 通俗易懂、 风趣幽默、 轻松愉快。 从 Hello World 聊到源码分析,从工具使用讲到内部原理,从日常生活说到设计哲学。同时,本书的内容设计由易到难,图文并茂,再加上丰富的实例,可以让初级人员非常轻松地入门。同时,作者对技术独树一帜的理解还可以让中、高级的技术人员受到很多启发。所以,本书堪称“老少皆宜,居家、旅行必备良品” 。《 Spring Boot 趣味实战课》你值得拥有!
本书结构,宏观上可以分为三个部分,
1-3 章是热身,主要用来让小白能够掌握一些必要的前置知识
4-8 章是基础实战,包括 Spring Boot 最基本的使用,以及其内部原理
9-14 章是高级用法,主要是 Spring Boot 与其他各种组件配合使用,完成更加复杂的功能。
本书各章节之间没有什么严格的先后关系,可以根据自己的兴趣安排阅读顺序。但如果你是小白的话,推荐你从头往后阅读。
章节介绍
第一章 是对 Spring Boot 的宏观介绍,主要介绍了 Spring Boot 的现状,以及其简单易用的特点和约定优于配置的设计哲学。
第二章 是一些准备工作,包括对 Maven 的介绍;IDEA 的常用设置及使用技巧,并推荐了一些好用的插件。
第三章 通过一个 HelloWorld 实例引出了 Spring Boot 的工程结构,并对 Starters 和 YAML 进行了详细的讲解。
第四章 主要是对 Spring MVC 的讲解,详细的阐述了 Spring MVC 的各种用法。并对其原理以及源码进行了分析。
第五章 主要是对 HTTP 和 RESTFul 的讲解,每个程序员都该懂一点 HTTP,顺带把 Swagger 的使用进行细致的讲解。
第六章 实战阶段的重头戏,持久化相关的内容都在这里了。MyBatis、Spring Data JPA、Druid、事务隔离级别及传播特性等,内容较多慢慢看。
第七章 包含三方面内容:单元测试、异常处理和日志,这三驾马车可以为你的系统保驾护航,快速定位问题。
第八章 IOC、AOP、自动配置、启动流程,Spring Boot 的核心都在这里了。大量源码分析,掰开揉碎给你整明白。
第九章 Redis 登场,介绍了 Redis 整合 Spring Boot 的各种实战,以及如何使用 Redis 实现分布式锁。
第十章 主要讲解了 Spring Security 的整合、认证和授权,为系统安全提供保障。
第十一章 ,分别用 Spring Task 和 Quartz 做了实例,讲解定时任务三种调度策略。
第十二章 介绍了 RabbitMQ,讲解了它的五种主要工作模式,讨论了 MQ 适用的业务场景。
第十三章 讲解了 Elasticsearch 的核心概念,以及基本用法,阐述了倒排索引的原理。
第十四章 介绍了 Spring Boot 的监控组件 Actuator,并演示了如何与 Spring Boot Admin 整合使用。
第十五章 分享了一些作者多年来关于技术学习的心得。
第1章 Spring Boot凭什么成为JVM圈的框架“一哥”
1.1用数据说话
1.2多方支持
1.3打铁还需自身硬
1.3.2 有内涵
作为一个有追求的框架,肯定不能仅靠一副好看的皮囊。Spring Boot或者说Spring,除了“颜值高”这个我们比较容易感知的特点,还有需要我们深入探索才能了解的丰富内涵。比如,它的两大核心特性——IOC和AOP,还有接下来要探讨的“约定优于配置”的设计哲学。
“约定优于配置”是什么意思呢?就是按照约定俗成的规范编程。Spring Boot制定了一套编程的最佳实践规范,如果我们没有特殊的需求,可以实现“开箱即用”。而这种规范是一种推荐性的而不是强制性的规范。我们还可以根据需要来自定义相应规范。这样既做到了开箱即用的便利性,也兼顾了按需定制的灵活性,在简单和灵活之间找到了一个完美的平衡点。
在Spring Boot中,这种“约定优于配置”的思想随处可见。例如,当引入spring-boot-starter–web依赖后,我们的应用就具备了Spring MVC的功能(提供HTTP服务、JSON支持和数据校验等)。而且我们不需要安装Tomcat或其他Web容器,可以直接以Jar的方式运行一个Web应用。这也是提前约定好的,在默认情况下打包应用时,Spring Boot会内嵌一个Tomcat。当然,也可以通过修改Maven依赖将Tomcat替换成其他容器,如Jetty,或者直接哪个容器也不用。
这种“约定优于配置”的思想,类似于现实生活中的风俗习惯。比如,我们会在春节吃饺子、贴春联、放鞭炮(当然不能在禁放区内燃放),西方国家的人会在感恩节吃火鸡、在平安夜互送苹果。这些都是在一定范围内形成的默契,大家不需要提前商量,到特定的日子就会默契地做相同的事情。
网上流传这样一句话:外表决定了我是否愿意去了解你的内在,而内在决定了我会不会一票否决你的外表。巧的是,Spring Boot不仅有着动人的外表(市场份额高、关注度高、简单易用等),还有着丰富的内在(“约定优于配置”的设计思想、IOC和AOP等强大功能)。如果说Spring Boot是一个女孩,那么我能想到的形容她的词只有“秀外慧中”了。有框架如斯,夫复何求呀!
1.4要点回顾
· 在JVM生态中,Spring占据了大约60%的市场份额;在服务端框架中,Spring Boot+Spring MVC占据了大约80%的市场份额
· Spring Boot自诞生以来,关注度持续上升
· Spring Boot有官方力推和“大厂”背书,未来形势一片大好
· Spring Boot简化了复杂的配置,大大提升了开发效率
· Spring Boot具有优秀的设计思想和强大的功能
第2章 兵马未动,粮草先行——码前准备
2.1软件环境
2.2大管家Maven
本书选择Maven作为Jar包管理及构建工具。原因很简单,它拥有领先的市场份额。
2.2.1 pom文件
POM(Project Object Model,项目对象模型)是我们使用Maven的核心。pom文件使用XML语言编写,定义了项目的基本信息,用于描述项目如何构建,声明项目依赖等。
2.2.2 常用概念
坐标
坐标是Maven中非常重要的概念。我们在初中数学里就已经学习过这个概念,例如:(0,7)代表Y轴上距离原点7个单位的一个点。而我们在地理课里也学习过由经/纬度组成的坐标,例如:(东经116°23’51”,北纬39°54’31”)是天安门的坐标。那么Maven中的坐标是什么样子的呢?Maven中的坐标由以下3部分构成:
· groupId
· artifactId
· version
groupId代表组信息,通常是公司或者组织;artifactId是项目在组内的唯一标识;version就很简单了,代表项目的版本。
在Java中,可以说“万物皆对象”,而在Maven中,则可以说“万物皆坐标”。一切Jar包或pom文件都可以用一个唯一的坐标来标识。
依赖
我们可以通过坐标来声明一个Jar包或pom文件(War包不能被引用,这里不讨论),还可以通过坐标来引用其他的Jar包或pom文件。依赖管理是Maven最重要的功能之一.
继承
Maven中的继承和Java中的继承类似,都通过
构建
构建(Build),也就是我们所说的编译打包的过程,是Maven另外一个重要的功能,用于将我们的工程打成Jar包或War包。
Maven是通过集成插件的方式来实现构建功能的,可以根据不同的构建需求选择不同的插件。在Spring Boot项目中,默认使用spring-boot-maven-plugin插件进行构建,因为Spring Boot需要将工程打包成可执行的Jar文件,所以需要使用自己定制的构建插件
2.3打造一件趁手的兵器
2.4要点回顾
· 软件环境尽量与本书统一,经验丰富者除外
· Maven介绍及相关概念讲解,如坐标、依赖、继承、构建
· Intellij IDEA常用设置,如设置字体、显示行号、自动导入、自定义工具栏等
· Intellij IDEA使用技巧,如历史剪切板、随心搜、自动写代码、重构等
· Intellij IDEA比较好用的插件推荐,如Codota、Lombok、Maven Helper等
第3章 牛刀小试——五分钟入门Spring Boot
3.1万物皆可Hello World
3.2 Spring Boot的工程结构
3.2.1 结构详解
从上面的结构中可以看出,工程根目录由4部分组成——target(目录)、gitignore(文件)、pom.xml(文件)和src(目录)。
我们知道,target是目标的意思,使用Maven打包后会将编译后的.class文件和依赖的Jar包,以及一些资源文件放到这个目录下。
gitignore文件用来配置那些不需要Git帮助我们进行版本控制的文件或目录,例如,Intellij IDEA产生的配置文件或者本地开发使用的application-local.yml文件等。
pom.xml文件用来配置依赖的Jar包,帮助我们进行Jar包管理。我们会经常跟它打交道。
最后的src目录用来存放所有我们编写的Java源码文件、程序配置文件、资源文件等,是开发需要用到的主目录。
3.2.2 结构分类
功能目录
target、gitignore和pom.xml都是偏工具属性的,主要是给Maven、Git用的,与开发人员的关系没有那么紧密。我们可以将其称为功能目录(文件)。
业务目录
真正跟开发人员息息相关的是src目录下的内容。开发人员平时操作最多的内容也是这个目录下的内容。我们可以清晰地看到,src目录有两个分支——main和test。这两个目录的用途很好理解,main用来存放业务逻辑主代码,而test则用来存放测试代码。而且我们可以很容易地发现它们两个内部的结构极其相似。因为test就是为main服务的,理论上讲,main中的每一个Java类(POJO类除外)在test中都有一个测试类,可以理解成main中的每个类都有一个“贴身侍卫”,用来护其周全。
再往下看,又分为dao、service、controller等目录,这体现了软件开发中最基本的分层思想,对应着数据层、业务逻辑层及Web控制层。
3.3珍爱生命,我用Starters
3.4值得拥有的YAML
Y3.4.1 Properties与YAML
YAML更加具有整体性和层次感,直观地体现了各个配置项之间的层级关系;而Properties在这一点上比较弱,它的内容只是罗列了配置信息,并没有直观地体现它们之间的关系。同时,YAML的写法更加简洁。
3.4.2 YAML语法
Spring Boot默认使用Properties作为配置文件格式,需要手动将application.properties重命名为application.yml。
3.5要点回顾
· Spring Boot只需5步就可以搭建一个Web工程
· Spring Boot采用Maven的工程结构,它们都遵循“约定优于配置”的原则
· Starters整合了很多常用功能,可以减少大量重复性工作
· YAML是一种非常简洁、易读写的配置文件格式
第4章 斗转星移,无人能及——Spring MVC
4.1 Spring MVC简介
Spring MVC是Spring Framework中的一个组件,原名为Spring Web MVC。不过人们更喜欢将其称为Spring MVC。由它的名字可知,它是一款Web框架。通过Spring Web MVC这个名字,我们就可以对它有一个宏观的认识。
· Spring彰显了它的家族身份,代表它来自Spring家族
· Web代表它是一款与Web相关的框架
· MVC则代表它的本领
那么,这个MVC具体是什么意思呢?MVC模式是软件工程中的一种软件架构模式,把软件系统分为3个基本部分:模型(Model)、视图(View)和控制器(Controller)。
· 模型(Model):Model是由一个实体Bean实现的,是数据的载体
· 视图(View):在Java EE应用程序中,View可以由JSP(Java Server Page)担任。在目前的前/后端分离模式下,View已经由前端取代
· 控制器(Controller):在Java EE应用中,Controller可能是一个Servlet。在Spring MVC中,控制器的核心是DispatcherServlet
4.2接收参数的各种方式
上一章中的Hello World程序只是一个非常简单的例子,hello方法没有接收任何参数,而在实际应用中,我们需要处理各式各样的参数。Spring MVC接收参数的方式大致可以分为以下4种:
· 无注解方式
· @RequestParam方式
· @PathVariable方式
· @RequestBody方式
4.2.1 常用注解
在学习如何接收参数之前,先来认识一下Spring MVC中的常用注解,如表所示。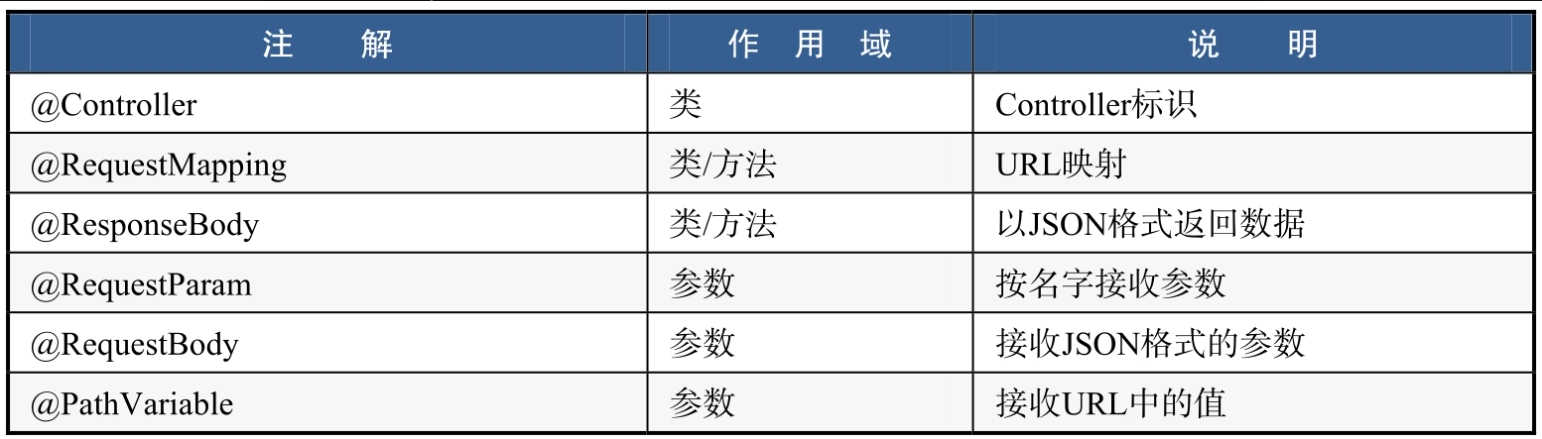
@Controller
@Controller用来修饰类,表示该类为一个Controller对象。Spring容器在启动时会将该类实例化。
@RequestMapping
@RequestMapping用来修饰类或方法,设置接口的访问路径。在修饰类时,一般用于设置该类下所有接口路径的前缀。
@ResponseBody
@ResponseBody用来修饰类或方法。在修饰方法时,该方法以JSON格式返回数据;在修饰类时,该类下的所有方法默认都以JSON格式返回数据。
@RequestParam
@RequestParam用来修饰参数,可以根据名字与参数进行绑定,相当于ServletRequest.getParameter()。
@RequestBody
@RequestBody用来修饰参数,接收JSON格式的参数,经常应用于AJAX请求,前/后端分离的场景下。
@PathVariable
@PathVariable用来修饰参数,用于获取URL上的值。
除了上面这些,我们还会用到一些其他的注解。这些注解可以说是以上注解的一个“变种”,可以被称为“组合注解”。什么是组合注解呢?继续阅读,一看便知:
· @RestController=@Controller+@ResponseBody
· @GetMapping=@RequestMapping(method=RequestMethod.GET)
· @PostMapping=@RequestMapping(method=RequestMethod.POST)
· @PutMapping=@RequestMapping(method=RequestMethod.PUT)
· @PatchMapping=@RequestMapping(method=RequestMethod.PATCH)
· @DeleteMapping=@RequestMapping(method=RequestMethod.DELETE)
相信聪明的你已经发现了,组合注解就是具有多个功能的注解,是由多个注解或一个注解与一个特定的属性值组成的注解,相当于对注解的一种封装。封装后的注解具有多个功能,如:@RestController不仅可以标识一个Controller,还可以让被标识的Controller中的所有方法都返回JSON格式的数据;@GetMapping不仅可以映射一个请求路径,还可以让该路径只响应GET方法。
4.2.2 准备工作
@Data
@Data注解是Lombok库中的一个注解,它可以自动为类生成一些通用的方法,如getters和setters、equals、hashCode和toString等。
4.2.3 无注解方式
4.2.4 @RequestParam方式
4.2.5 @PathVariable方式
4.2.6 @RequestBody方式
4.3参数校验
说到传参,就避不开参数校验。在实际开发中,我们需要根据需求对参数进行各种各样的校验:是否为空、是否超出取值范围、是否为数字、E-mail格式是否正确等。在没有数据校验API之前,我们需要自己实现这些校验的代码。在有了JSR-303规范之后,这些事情就变得无比简单、方便。
Spring MVC对JSR-303具有良好的支持特性,在Spring Boot的加持下,更是“如鱼得水”,只需要引入一个Starter就可以获得参数校验的能力。
4.3.1 开启参数校验
添加validation的Starter依赖
为数据对象添加注解:
4.3.3 常用的参数校验注解除前文介绍的4个注解以外,还有一些比较常用的参数校验注解,如表所示。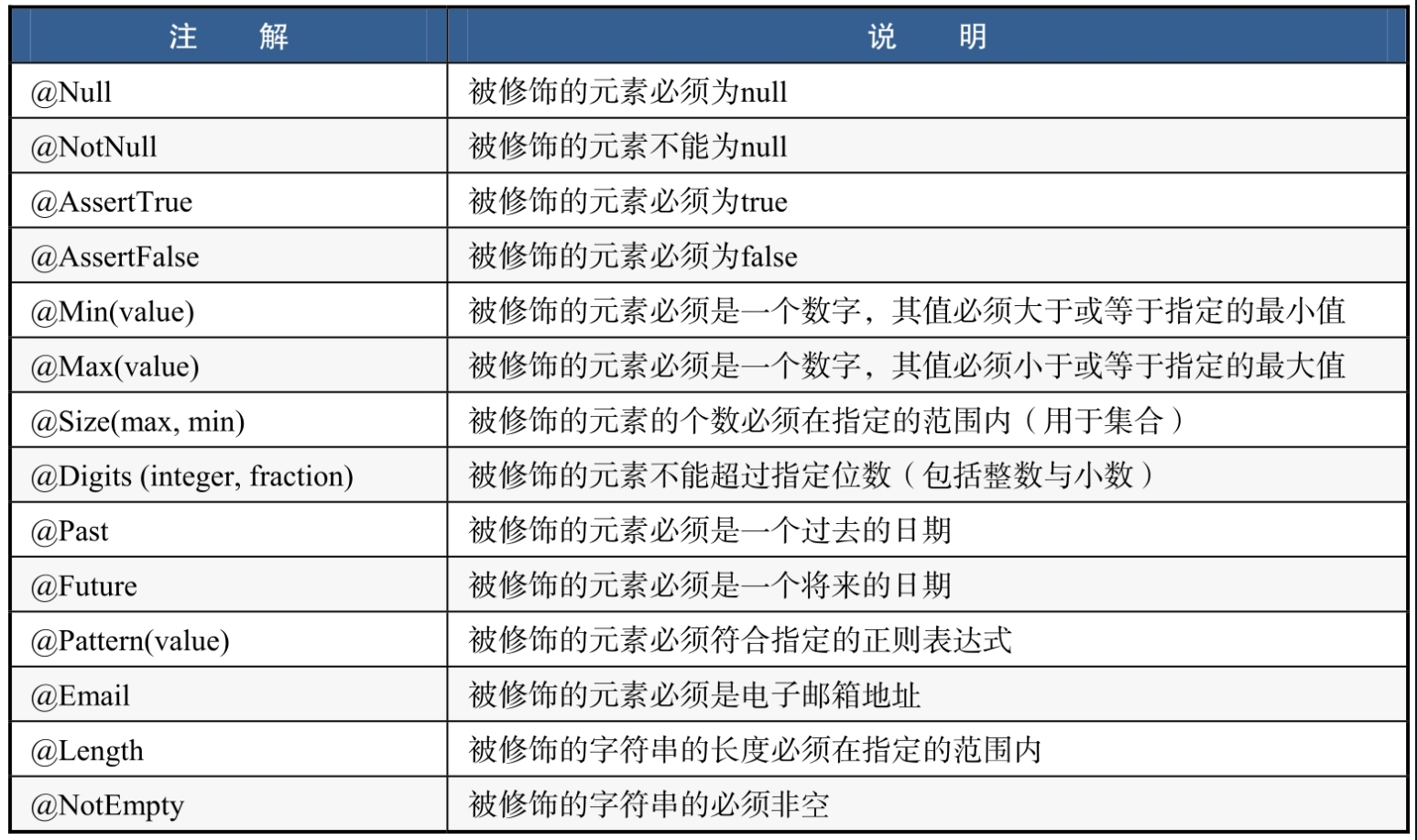
实际上,参数校验就好比乘坐高铁、飞机之前的安检,是保护系统的一道防线,而不符合要求的参数就好比违禁物品。如果将易燃、易爆物品带上高铁或者飞机,就可能会引发一些安全事故,严重的还会威胁到乘客的生命安全。同样地,如果系统不进行参数校验,就会有不符合要求的数据进入系统,从而对系统造成破坏,所以要把好参数校验这一关。
4.4原理分析
经过学习前面的内容,我们已经掌握了使用Spring MVC的基本技能。但仅仅会用是不够的,我们还需要知道它的内部是如何运作的。下面我们就来一探究竟。
Spring MVC最核心的思想在于DispatcherServlet。在现在的开发模式中,我们主要使用的也是Spring MVC的这一核心功能。那么,DispatcherServlet究竟是何方“神圣”呢?
大家还记得“姑苏慕容”吗?没错,就是小说《天龙八部》里那个以绝招“斗转星移”闻名于世,致力于“光复大燕”的慕容家族。这里,我们就拿“斗转星移”和DispatcherServlet进行一个类比。它们都先从外部接收一个东西(内力/请求),经过一系列转换,然后给外部一个反馈(内力/响应)。当年,慕容龙城(小说里的慕容氏先祖)凭借自创的“斗转星移”威震江湖。在《天龙八部》中,“斗转星移”连扫地僧口中天下第一的武功“降龙十八掌”都能化解,足见其十分精妙。不过,后来遇到段誉的“六脉神剑”,“斗转星移”就显得不太灵光了,可能是因为当年慕容龙城创造“斗转星移”时,没有考虑“高并发”的业务场景(笔者注:宋朝时算力有限,6个请求就算得上“高并发”了)。
4.4.1 流程分析
Spring MVC的内部处理流程如图所示。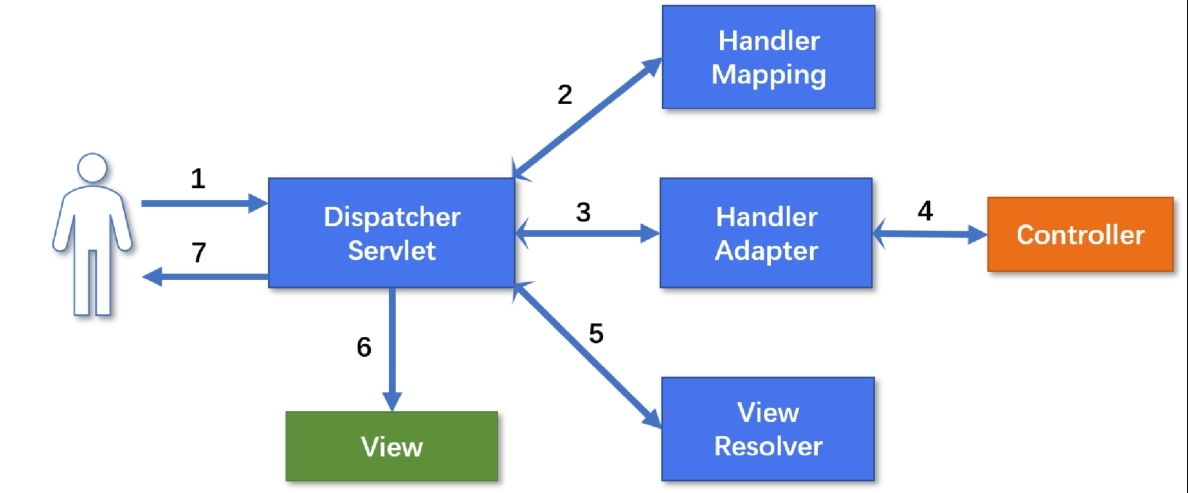
浏览器发起一个请求(如http://localhost:8080/hello),会经历如下步骤。
1.DispatcherServlet接收用户请求。
2.DispatcherServlet根据用户请求通过HandlerMapping找到对应的Handler,得到一个HandlerExecutionChain。
3.DispatcherServlet通过HandlerAdapter调用Controller进行后续业务逻辑处理,等待步骤4的返回。
4.处理完业务逻辑后,HandlerAdapter将ModelAndView返回给DispatcherServlet。
5.DispatcherServlet通过ViewResolver进行视图解析并返回View。
6.DispatcherServlet对View进行渲染。
7.DispatcherServlet将最终响应返回给用户。
当返回JSON格式的数据时,DispatcherServlet会省去对视图处理的步骤。
4.4.2 深入核心
Spring MVC的3个核心组件:
· Handler
· HandlerMapping
· HandlerAdapter
Handler是用来做具体事情的,对应的是Controller里面的方法。所有有@RequestMapping的方法都可以被看作一个Handler。
HandlerMapping是用来找到Handler的,是请求路径与Handler的映射关系。
从名字来看,HandlerAdapter是一个适配器。它是用来跟具体的Handler配合使用的。我们可以将其简单理解为各种电子产品与电源适配器(充电器)的关系。
DispatcherServlet最核心的方法是doDispatch。doDispatch主要做了4件事:
· 根据请求找到Handler
· 根据Handler找到对应的HandlerAdapter
· 用HandlerAdapter处理Handler
· 处理经过以上步骤的结果
4.5拦截器
前面我们学习了Spring MVC的基本使用及其内部原理,下面学习Spring MVC的高级用法——拦截器。拦截器在日常开发中有很重要的地位,可以帮助我们完成很多重要的功能。例如:
· 登录认证
· 权限验证
· 记录日志
· 性能监控
· ……
下面我们通过一个实例来学习拦截器是如何工作的。
4.5.1 自定义拦截器
Spring MVC中所有的拦截器都实现/继承自HandlerInterceptor接口。如果想要编写一个自定义拦截器,就需要实现/继承HandlerInterceptor接口或其子接口/实现类。下图所示为Spring MVC中拦截器的类图。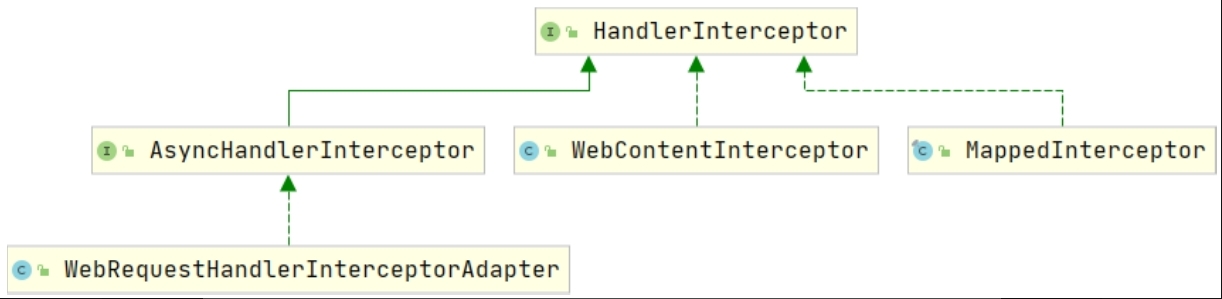
HandlerInterceptor接口的源码如下:
该接口包含3个默认实现(Java 8)的方法——preHandle、postHandle和afterCompletion。
4.5.2 拦截器的执行流程
从控制台的日志输出中,我们可以大概看出拦截器的执行流程。通过下图,我们可以更清晰地了解拦截器的执行流程。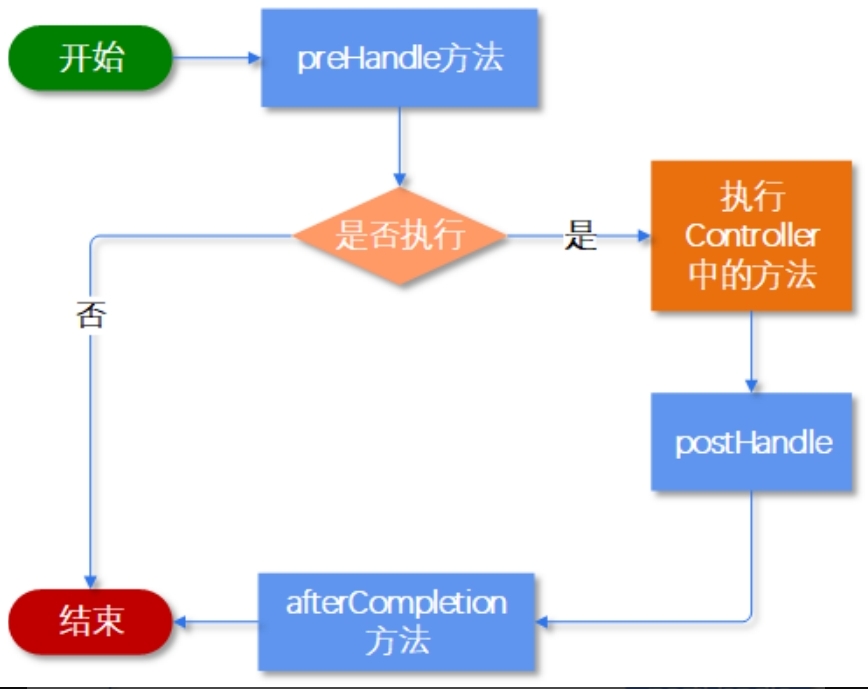
1.执行preHandle方法。该方法会返回一个布尔值。如果为false,则结束本次请求;如果为true,则继续本次请求。
2.执行处理器逻辑,也就是Controller。
3.执行postHandle方法。
4.执行afterCompletion方法。
看到这个流程后,我想起了评书中很常见的一幕:
一行人正在赶路,行至一座山脚下。突然一彪形大汉从树丛中蹿出,面蒙黑巾,手持两把板斧,大喝道:“此山是我开,此树是我栽,要想从此过,留下买路财!”此人不是别人,正是那混世魔王程咬金。
嗯?原来拦截器就是程序届的“程咬金”呀!看来发明拦截器的人一定没少听单田芳老师的评书。
我们常说艺术来源于生活,其实技术同样来源于生活。现实生活中的很多场景都可以看到拦截器的“影子”,比如,我们上下班坐地铁这件事情,就好比拦截器的现实生活版。坐地铁的流程如图所示。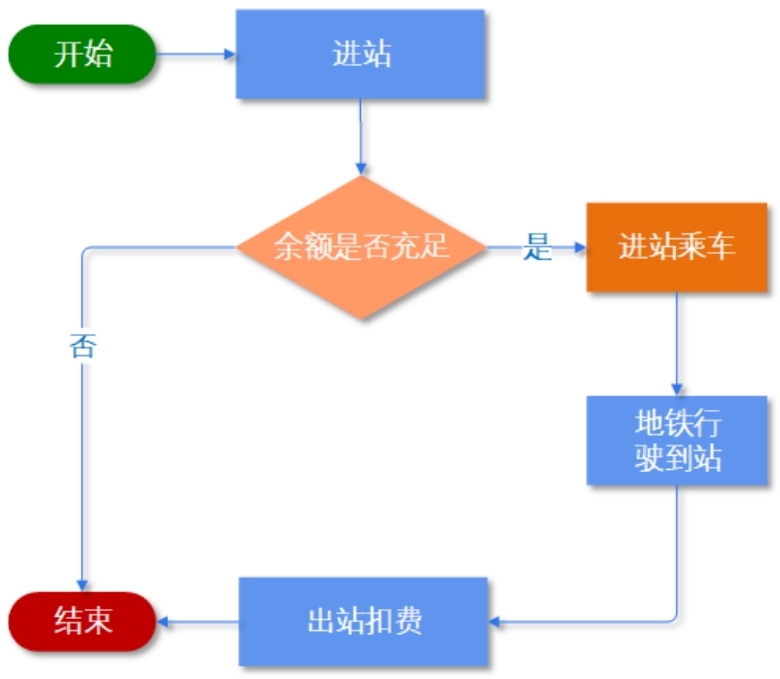
可以看出,坐地铁的流程跟拦截器是一一对应的。
1.进站对应preHandle方法。在闸机上刷卡,如果余额充足,则可以进站;如果余额不足,则不允许进站。
2.进站乘车对应Controller中的逻辑(我们要做的事)。
3.进入车厢后(完成乘车动作),地铁启动,行驶到我们的目的地,对应postHandle方法。
4.到站后,在闸机刷卡,完成出站扣费,对应afterCompletion方法。
4.5.3 多个拦截器的执行顺序
在实际应用中,通常需要多个拦截器一起配合使用才能满足我们的需求。了解了单个拦截器的执行流程后,接下来看看多个拦截器组合起来是如何运转的:是执行完一个再执行下一个,还是嵌套执行,抑或是其他的方式呢?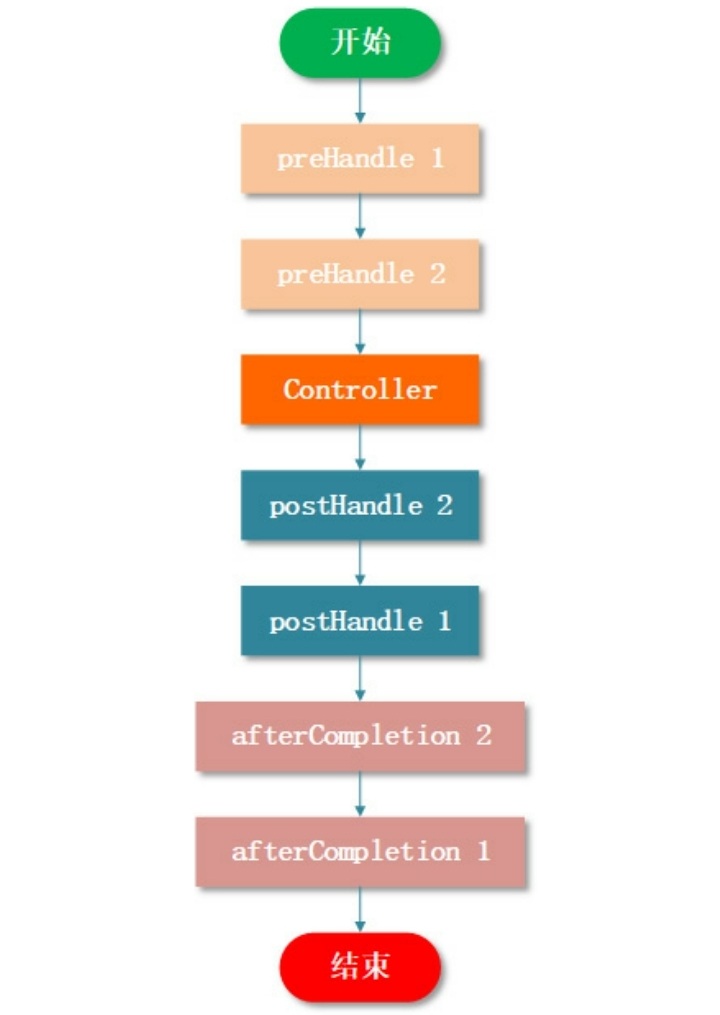
4.6要点回顾
· MVC指的是模型(Model)、视图(View)和控制器(Controller)
· Spring MVC接收参数的4种方式:无注解、@RequestParam、@PathVariable和@RequestBody
· 常用的参数校验注解:@NotEmpty、@Min、@Email和@Past
· Spring MVC核心组件DispatcherServlet及处理请求的七步流程
· Spring MVC的3个核心对象:Handler、HandlerMapping和HandlerAdapter
· 通过两个自定义拦截器学习了拦截器的运行原理,了解了多个拦截器按照先进后出的顺序执行,并通过分析源码进一步验证
第5章 你有REST Style吗
5.1你应该懂—点HTTP
5.1.4 协议版本
在前面介绍报文的时候,你可能已经发现了,不管是请求还是响应,里面都有一个值——HTTP/1.1。这个值主要用来说明当前请求/响应使用的是HTTP的哪个版本。HTTP发展至今,经历了几个版本的更迭,一直在进化,在成长。前面示例中用的是目前最为流行的HTTP/1.1。除了这个版本,在这个版本之前还有HTTP/0.9、HTTP/1.0,之后还有HTTP/2.0。接下来我们来看看它们之间的异同。
HTTP/0.9
这个版本只能算作一个原型版本,诞生于1991年。它非常简陋,并且存在严重的设计缺陷。它只支持GET请求,没有Header(也就是我们上面说的首部),其设计初衷就是为了从服务器中获取简单的HTML对象。好在后面很快就被HTTP/1.0取代了。
HTTP/1.0
HTTP/1.0算是真正意义上的正式版本。这个版本设计已经非常良好与完善了,后面也得到了广泛的应用。HTTP/1.0在之前版本的基础上增加了Header、状态码的支持,并且支持更多的HTTP方法,还加入了对多媒体格式和缓存的支持。
HTTP/1.1
HTTP/1.1是目前应用最广泛的版本,在HTTP/1.0的基础上进行了进一步的完善。该版本最大的变化是引入了持久连接,使得建立一次连接可以发送多次HTTP请求,提高了资源利用率。同时,增加的PUT、PATCH、DELETE方法对后来RESTful的发展也有一定的促进作用。另外,Header中还增加了Host字段,使得同一主机可以提供多个服务。
HTTP/2.0
HTTP/2.0目前还没有得到广泛的应用,但这只是时间问题而已。这个版本主要在性能方面进行了优化,将所有数据都改为二进制格式进行传输(之前基本上都是字符串),并且对首部内容进行了压缩传输。此外,还增加了双工模式,使得客户端可以在一个HTTP连接中同时发送多个请求,服务端也可以同时处理多个请求。HTTP/2.0还增加了一个新特性——服务器推送(Server Push),即由服务器主动发起的操作,这一特性很适合静态资源(如CSS、JS等)的加载。
说起HTTP,有这样一个现象:前端工作人员认为HTTP应该是后端工作人员掌握的知识,后端工作人员认为HTTP应该是前端工作人员掌握的知识。对此,HTTP表示“我招谁惹谁了?”那么,HTTP究竟是谁应该掌握的呢?我认为,每个程序员都应该了解HTTP。
5.2接口代言人Swagger
为什么还不介绍RESTful?别急!这里引出Swagger有两个原因:一个是为了填补第4章中挖的“坑”,如果不记得,可以回去看一下(4.2节结尾处);另一个是后续的内容需要用到Swagger。下面我们先看看Swagger是什么。
Swagger是一款用于生成、描述、调用和可视化RESTful风格的Web服务接口文档的框架。由于其最大的特点莫过于可以使接口文档与代码实时同步,所以我把Swagger称为接口代言人。
Java Web从最开始的JSP到后来加入的AJAX异步交互,再到现在的前/后端分离,后端工作人员从一开始包揽HTML、JS、Java代码到现在更加专注于后端业务逻辑。随着开发模式的演变,前/后端工作人员的分工越来越精细,联系也越来越松散。这时接口文档便成了连接前/后端的关键纽带。最初,通常的做法是将接口文档写在公司内部的Wiki上(如Confluence)。但这种做法的致命缺点就是接口文档几乎永远都会落后于实际代码实现,让我们的开发工作无法顺畅地进行下去。为了解决这些问题,Swagger应运而生。Swagger不仅可以实时展示接口信息,还可以对接口进行调试。下面让我们一起走进Swagger的“世界”。
5.2.2 效果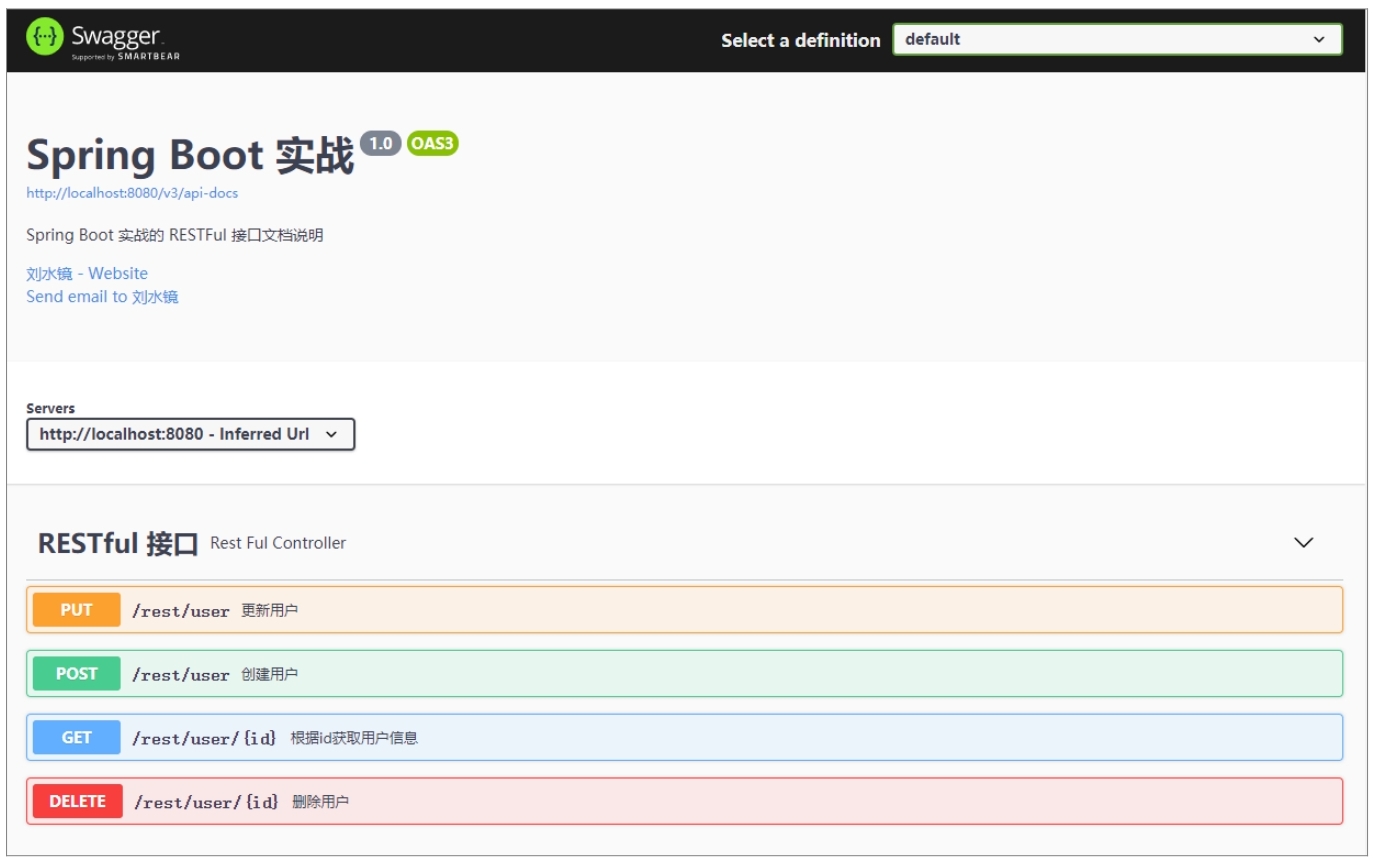
Swagger页面分为两部分,上面是接口的基本信息,包含了项目名称、描述等信息;下面是每个接口的具体描述,如接口名字、参数名字、参数类型、是否必填等,还有返回的结果示例。
单击对应的接口,可以看到接口的详细描述,还可以调用该接口,并查看返回值。接口的用法很简单,一看就会,这里就不赘述了。
5.2.4 增强版
Swagger作为接口文档来说已经非常好了,如实时更新、接口说明、参数及返回值示例等一应俱全。但它在使用体验和调试接口方面有些弱。幸运的是,有一款增强版的工具能够弥补原生Swagger的不足——knife4j
5.3解密REST
5.3.1 REST定义
REST是Representational State Transfer的缩写,翻译为中文就是“表现层状态转换”,是Roy Thomas Fielding于2000年在他的博士论文中提出来的一种互联网软件架构风格。
以上是关于REST的解释,如果你通过以上的描述理解了REST是什么,那么你可以合上这本书了。假如你没理解,那么我非常欢迎你继续阅读这本书。
Roy Thomas Fielding是何许人也呢?他是HTTP协议(1.0版和1.1版)的主要设计者,Apache服务器软件的作者之一,Apache基金会的第一任主席。所以,当他提出REST的概念时,能够迅速引起业界的高度关注也就不足为奇了。
资源
“表现层状态转换”的说法比较抽象,实际上,“表现层”指的是“资源”的表现层(可能Roy Thomas Fielding觉得RREST看起来不如REST好看,所以省略了Resource)。那么我们首先需要弄明白,这里的“资源”指的是什么。实际上,“资源”的范围比较宽泛,比如一个文件(图片、文档、音乐等)、一条数据(用户信息、订单等)都可以被看作资源(每个资源都有一个对应的URI)。我们在学习面向对象编程的时候,应当都听过一句“五字真言”——万物皆对象。这里可以将其拿过来套用一下,即万物皆资源。
表现层
Representational被翻译成表现层,其实我认为叫“表现形式”会更容易理解。简单来说,就是资源以什么样的形式来展现自己——例如,文本可以是JSON或XML格式的,图片可以是JPEG或其他格式的。所以,我们现在将REST翻译成“资源表现形式的状态转换”,接下来我们来理解一下这个状态转换。
状态转换
我们对REST的翻译进化到了“资源表现形式的状态转换”,比起“表现层状态转换”好像清晰了一些,但总觉得哪里不太对。这个“状态转换”还是不好理解。这里有两个问题:一个是表面上的,即状态转换是什么;另一个是隐含的,即状态转换是如何产生的。
。。。
状态转换说的是资源发生了变化。第一个问题解决了,下面我们来看第二个问题——状态转换是如何产生的?要解决这个问题,需要用到Roy Thomas Fielding的另一个身份——HTTP协议的设计者。这个问题跟HTTP协议有着密切的关系。还记得HTTP中的GET、POST、PUT、DELETE这4个方法吗?“资源”的状态转换正是由HTTP的各种动作(方法)所引起的。
至此,REST的翻译就变成了“资源以某种表现形式在HTTP方法的作用下发生变化”。这样一来,意思就比较明显了,转换其实就是发生了变化,就是改变的意思。而资源的状态发生了改变,其实就是说资源被修改了,也就是REST数据操作的另一种叫法。其实,REST的核心不仅仅是对数据的操作,还包括如何操作,以什么样的规范操作。后面会通过具体的例子来进一步说明RESTful API到底是什么样的。
5.3.3 RESTful实践
前面介绍了很多关于REST的内容,那么RESTful风格的API究竟是什么样的呢?下面我们通过几个实例体会一下。RESTful风格的API要满足以下要求:
· 用URI定位资源
· URI由名词组成
· 使用HTTP方法操作资源
获取数据
新增数据
更新数据
删除数据
5.4 URL与URI
不知道你有没有注意到,上面描述REST规范的时候用的是URI,而不是我们更为熟悉的URL。它们两个有什么区别和联系呢?想要弄清楚它们之间的关系,需要引入第三方——URN。这里我们不过多介绍,只是简单说明URI和URL的关系。
· URI:Uniform Resource Identifier,统一资源标识符
· URL:Uniform Resource Locator,统一资源定位符
· URN:Uniform Resource Name,统一资源名称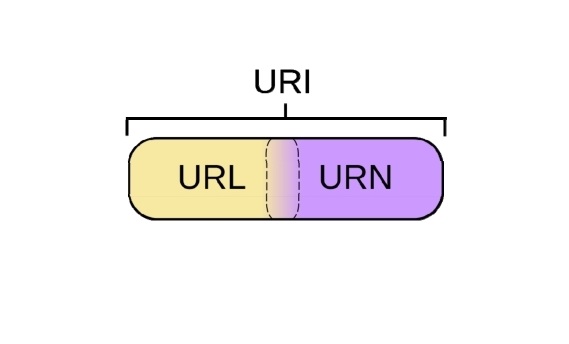
5.5要点回顾
· 每个开发者都应该懂一点HTTP· 报文分为请求报文和响应报文,由起始行、首部和主体组成
· knife4j是一款非常棒的Swagger增强工具
· RESTful风格的接口由URI定位资源,使用HTTP方法操作资源,且URI由名词组成
· 所有的URL和URN都是URI· URL能够定位资源,而URN不能
第6章 与持久化有关的那些事儿
6.1发展
持久化操作(对数据库的操作)一直都是Java的核心内容,并且在Java的发展历史中,数据库持久化层面的技术也在不断地发展与更新。
JDBC(Java Database Connectivity)是Java中访问数据库的规范,由Sun公司(2009年被Oracle收购)制定。原生的JDBC代码臃肿、冗余、非常难用,使得Java EE在当时备受质疑,所以Sun公司推出了EJB。现在已经很少有人提及EJB(当年靠着Sun公司的力捧名噪一时)了,这是因为EJB太重量级、太难用,很快就被Hibernate所取代(事实再一次告诉我们,“打铁还需自身硬”)。
Hibernate凭借自身强大的功能迅速走红,与Struts和Spring组成了当时风靡一时的SSH组合。后来,Sun公司借鉴了Hibernate的设计思路,制定了JPA(Java Persistence API)规范。在Hibernate后来的版本中,也实现了对JPA的完全支持。这也使得Hibernate在当时进一步巩固了自己在持久层框架的“霸主”地位。
走JPA路线的Hibernate发展得“风生水起”,但JDBC并没有因此“沉沦”。随着互联网的发展,尤其是移动互联网的飞速扩展,MyBatis(基于JDBC的轻量级持久层框架,前身是iBatis)凭借其简单、高效、灵活等特点迅速成为新时代的“宠儿”。
6.2派系之争
6.3 Spring Data JPA
Spring Data让数据访问技术(例如,关系型和非关系型数据库、MapReduce框架及基于云的数据服务)变得更加容易。Spring Data是一个聚合项目,包括很多子项目。Spring Data JPA就是其中之一
Spring Data组件
以下是Spring Data已经发布的相关组件:
· Spring Data Commons
· Spring Data JPA
· Spring Data KeyValue
· Spring Data LDAP
· Spring Data MongoDB
· Spring Data Redis
· Spring Data REST
· Spring Data for Apache Cassandra
· Spring Data for Apache Geode
· Spring Data for Apache Solr
· Spring Data for Pivotal GemFire
· Spring Data Couchbase(社区)
· Spring Data Elasticsearch(社区)
· Spring Data Neo4j(社区)
这些项目中很多都是由Spring团队和对应技术的第三方公司一起开发的。
通过名字,我们基本上就能知道这些组件的具体用途了。我们不再过多介绍这些组件了,重点来讨论Spring Data JPA。
主要功能特性
Spring Data JPA具有非常强大的功能和很好的易用性,其主要的功能特性如下:
· 丰富的数据操作和自定义对象映射抽象· 基于方法名衍生出的动态查询· 使用基类封装公共属性
· 无感知的自动审计· 支持自定义数据操作
· 可以非常方便地与Spring Boot集成(使用JavaConfig或XML)
· 可以通过配置与Spring MVC进行集成
· 跨存储持久化的实验性支持
这里我们先对Spring Data JPA有一个总体认识
6.4 MyBatis Plus
MyBatis Plus?我们知道,数码圈喜欢使用Plus,什么时候技术圈也流行使用Plus了,是不是还有MyBatis Pro或MyBatis Ultra?其实不是这样的,那么MyBatis Plus到底是什么呢?
MyBatis Plus(简称MP)是一个MyBatis的增强工具,在MyBatis的基础上只做增强不做更改,为简化开发、提高效率而生。
MyBatis Plus要做的是成为MyBatis最好的搭档,就像“魂斗罗”中的1P、2P,“哥俩搭配,效率翻倍
6.5强大的Druid
一次数据库访问总共分几步?三步:
第一步是创建一个连接;
第二步是操作数据;
第三步是释放连接。
对于一个业务动作来说,我们并不关心第一步和第三步,我们真正关心的是第二步——操作数据。为了做一件事情,我们不得不额外做两件我们并不想做的事情。前面讲到的Spring Data JPA和MyBatis Plus将这个问题解决了一半——封装了数据库连接的创建和释放,这样虽然减少了我们的工作量,但仍然有很大的性能开销。因为创建和释放连接的操作都是非常耗时的操作,要解决这个问题,就需要使用数据库连接池了。
6.5.1 基本原理
在应用初始化的时候,可以根据配置信息预先创建一些数据库连接对象,并存放于内存中。当需要访问数据库的时候,可以直接到连接池中“借”一个连接来用。当完成数据库操作以后,再将这个连接“还”给连接池,从而实现资源共享的目的。近几年很火的共享经济(共享单车、共享汽车、共享充电宝等)不就是这种思路吗?原来这些看起来新鲜的“玩法”早就被程序员们使用过了。
连接池技术避免了频繁创建与释放连接的情况,并且可以根据当前的使用情况来动态增减数据库连接数,做到一定程度上的按需“备货”,使得数据库资源的利用变得更加合理,不仅在速度上有了很大的提升,在稳定性上也得到了改善。
6.5.2 如何选择连接池
市面上有很多Java的数据库连接池组件,我们应该如何选择呢?表所示为主流数据库连接池的对比。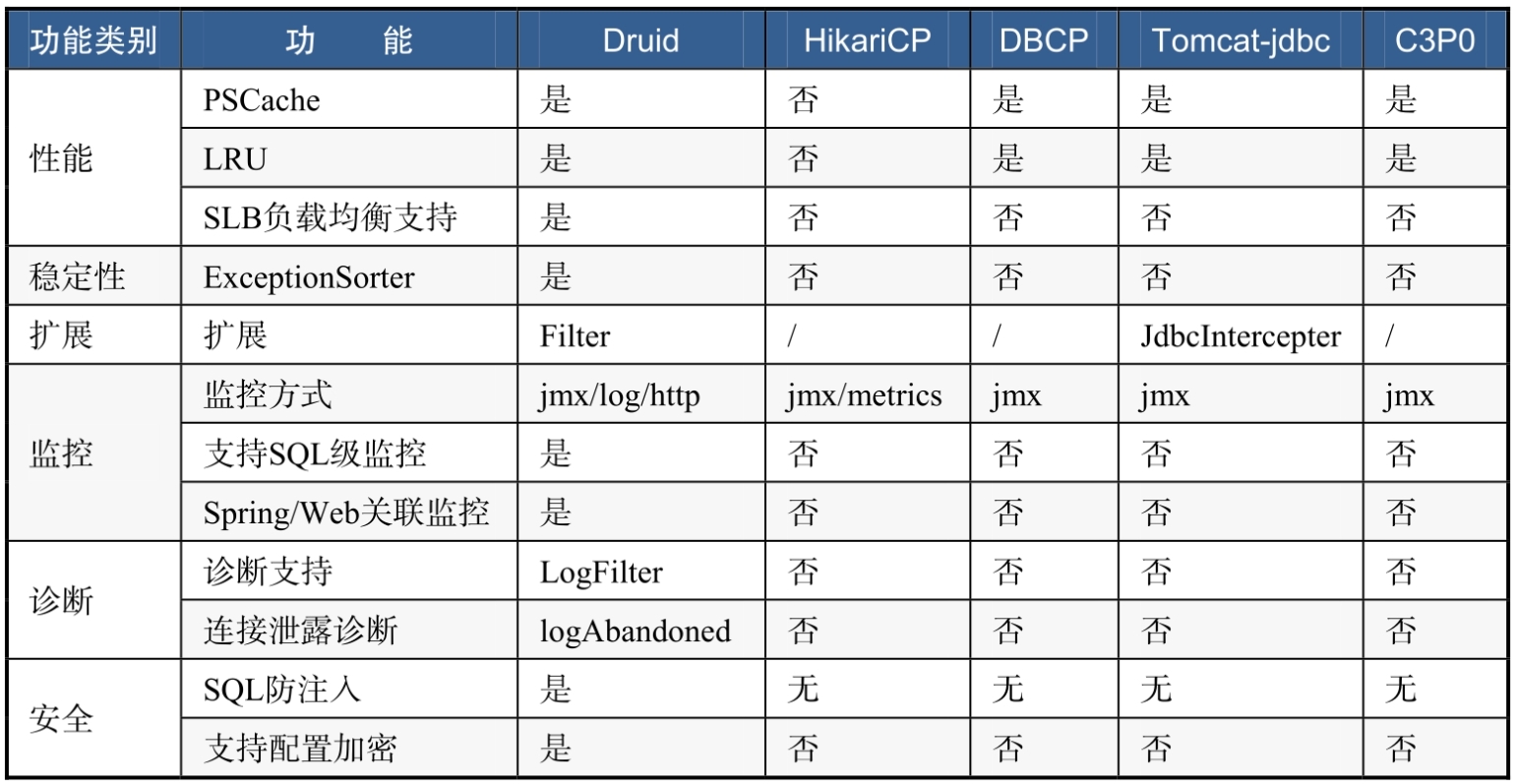
Druid是阿里巴巴公司出品的一款非常优秀的数据库连接池组件,拥有强大的监控功能,同时保证了非常好的性能,并且其稳定性经过了阿里巴巴公司内部成千上万次的系统验证,还经受过历年“双十一”活动的考验。这些都足以说明Druid是一款兼具性能与稳定性的优秀数据库连接池组件,因此我们可以放心地使用它。
6.6事务
事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
很显然,事务的概念是给“牛人”看的,我们普通人很难看懂。我们可以将其简单地理解为:对数据的一次操作就是一个事务。
6.6.1 事务的特性
事务具备4个特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),简称ACID。
原子性:事务作为一个整体被执行,其中对数据库的操作要么全部被执行,要么都不执行(有始有终)。
一致性:事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束(表里如一)。
隔离性:多个事务并发执行时,一个事务的执行不应影响其他事务的执行(不多管闲事)。
持久性:被提交的事务对数据库的修改应该永久保存在数据库中(一诺千金)。也就是说,事务“有始有终”“表里如一”“不多管闲事”“一诺千金”,真是集众多优秀品质于一身!
6.6.2 脏读、不可重复读、幻读
表所示为不同隔离级别与读问题的对照关系。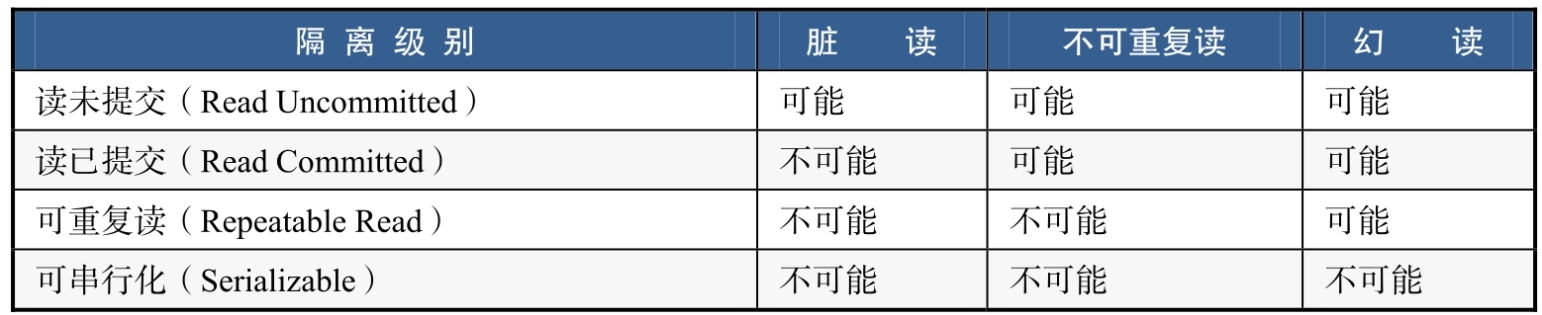
读未提交(Read Uncommitted):所有读问题都可能发生,一般不会使用这种隔离级别。
读已提交(Read Committed):只能避免脏读发生,Oracle的默认隔离级别。
可重复读(Repeated Read):能够避免脏读和不可重复读发生,MySQL中InnoDB引擎默认的隔离级别。
可串行化(Serializable):可以解决所有读问题,但由于是串行执行,性能相当一般,所以通常也不会被使用。
在MySQL中,可重复读级别就解决了幻读的问题。
6.6.4 Spring中的事务传播行为
我们知道事务有4个特性——ACID。其中,A代表原子性,意思是一个事务要么成功(将结果写入数据库),要么失败(不对数据库有任何影响)。但是当若干个事务需要配合完成一个复杂任务时,就不能这样简单地“一刀切”了。例如,在一个批量任务里(假设包含1000个任务),前面的999个任务都非常顺利、漂亮、完美且成功地执行了,然而最后一个任务非常“悲催”地失败了。这时候,Spring对着前面999个成功执行的任务说:“兄弟们,我们有一个任务失败了,现在需要全体恢复原状!”很显然,这不是我们想要的结果。我们需要根据任务之间的亲疏关系来指定哪些任务需要联动回滚,哪些任务即使失败也不会影响其他任务。要解决这个问题,就需要了解事务的传播行为。Spring中有7种事务传播行为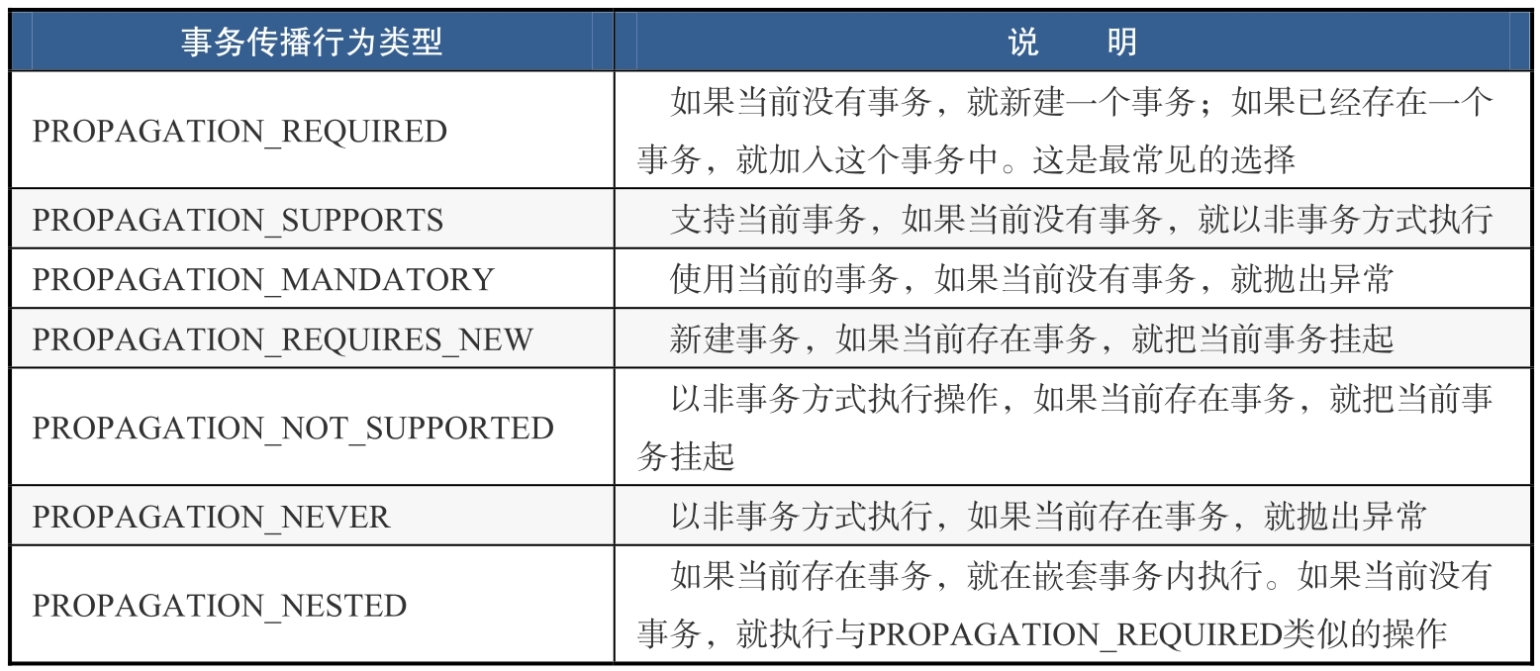
6.6.5 拓展
对于大部分数据库来说,我们在一段SQL语句中可以设置一个标志位,如果标志位后面的代码在执行过程中发生异常,则只需回滚到这个标志位的数据状态,而不会让这个标志位之前的代码也回滚。这个标志位在数据库的概念中被称为保存点。在Spring传播行为中,NESTED就是利用数据库保存点的技术实现的。但需要注意的是,一些数据库是不支持保存点的,这时NESTED就会像REQUIRES_NEW一样创建一个全新的事务(而非嵌套事务)。但是此时二者仍然有一些不同,NESTED传播行为会沿用外部事务的隔离级别和锁等特性,而REQUIRES_NEW则可以拥有自己独立的隔离级别和锁等特性,这一点区别在实际应用中要注意。
6.7要点回顾
· Hibernate与MyBatis没有绝对的好与坏,各有特色
· Spring Data JPA与MyBatis Plus都非常强大、好用,能够大幅度地减少CRUD功能代码的编写
· Druid不仅性能强劲,还有非常丰富的监控功能
· 事务有ACID特性和4个隔离级别
· 脏读、不可重复读、幻读要分清楚
· 不同的事务传播行为发生异常后,回滚的方式也不尽相同
第7章 出征前送你3个锦囊
经过前面几章的学习,我们了解了Spring Boot工程的搭建与配置、使用Spring MVC编写RESTful接口,以及持久层(Spring Data JPA和MyBatis Plus)的相关内容。至此,我们已经具备了完成一个后端应用的基础知识。是不是已经按捺不住想要动手编写一个小系统的心情了?先不要着急,在动手之前,我送你3个锦囊(现在就可以打开看的那种)——单元测试、异常处理和日志。
单元测试可以让你的代码更加健壮;
异常处理可以让意外对系统的伤害降到最低;
日志可以帮助你在系统出现问题后更快地修复系统。
7.1代码的护身符——单元测试
7.1.1 一个单元测试的自我修养
作为一个单元测试,要明确自己的定位,时时刻刻谨记——做一个合格的单元测试。那么,我们来看一下单元测试具备哪些素质才能称为一个合格的单元测试。
· 无副作用:单元测试不能对业务代码造成影响
· 可重复运行:多次运行结果一致
· 独立且完整:单元测试不依赖外部环境或其他模块的代码
前面两条很好理解,那么什么是“独立且完整”呢?例如,我们要为Service层的一个方法写单元测试,那么在运行这个单元测试时,就不能真的去访问数据库(因为与数据库交互的代码在Dao层,Service层的单元测试不能依赖Dao层),这就是“独立”。虽然不能访问数据库,但是需要保证整个流程可以正确、完整地执行,这就是“完整”。那么我们如何做到“独立且完整”呢?答案就是——Mock。市面上有很多Mock框架,如Mockito、Jmock、easyMock等。借助这些工具,我们可以很轻松地Mock出我们想要的依赖。
7.1.3 Junit
Junit是Java的一个单元测试框架,也是Spring Boot默认的单元测试工具。我们先来看一下Junit的几个核心概念和常用注解。
7.2天有不测风云——异常处理
无论你的代码写得多么无懈可击,也不可能完全避免意外发生。而我们能做的是,在意外发生以后将影响降到最低,使用更加温和的方式将问题反馈出来,让程序不至于直接崩溃。要达到这个目的,我们需要进行异常处理。在进行异常处理之前,我们需要对Java中的异常有一个简单的了解。
7.2.1 异常体系
简单来说,异常就是程序运行时遇到的我们预想之外的情况,而这些意外情况可以按照其严重性及我们对意外的处理能力分成不同的类型。Java异常体系如图所示。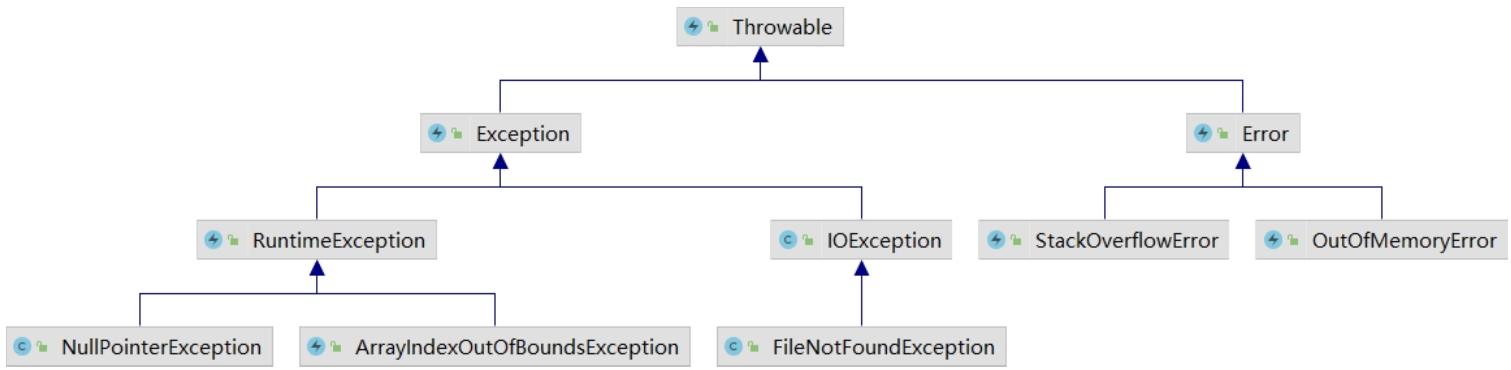
Java中有非常完整的异常机制,所有的异常类型都有一个共同的“祖先”——Throwable。由图可以看出,Throwable下面有两个分支:一个是Error,另一个是Exception。
Error
Error属于非常严重的系统错误,如OutOfMemoryError和StackOverflowError,类似于现实世界中的地震、台风等不可抗力。一旦这类问题发生,我们基本上就束手无策了,能做的通常是预防和事后补救。
Exception
Exception属于我们能够处理的范畴,如NullPointerException和FileNotFoundException。Exception还可以进一步细分为受检异常(checked)和非受检异常(unchecked)。
checked异常
checked异常指的是需要进行显式处理(try或throws)的异常,否则会发生编译错误。Java中的checked异常是一个庞大的家族,除RuntimeException和Error以外的类都属于checked异常。
unchecked异常
unchecked异常是最容易掌控的,甚至可以通过良好的编码习惯来避免(没错,就是避免),比如,NullPointerException、IndexOutOtBoundsException等。好比我们可以通过培养良好的习惯来避免生活中的很多不必要的麻烦,例如,我们可以提前出门,以避免因为堵车而赶不上飞机。同样地,在使用一个对象前,先判断该对象是否为null,就可以避免NullPointerException的发生。
7.2.2 全局异常处理
现在我们从理论层面对异常有了很全面的了解,接下来动手实践一下全局异常处理。
全局异常捕获
在Spring Boot中进行全局异常捕获非常简单,其核心就是一个注解——@ControllerAdvice/@RestControllerAdvice。
7.2.3 异常与意外
程序中的异常就像生活中的意外,有些我们无能为力,有些我们可以制定处理措施,有些则可以避免。人们总说“意外和明天,你永远不知道哪个会先来”,虽然我们无法左右谁先来,但我们能做的是:把握住自己能够掌控的,尽力改善我们能影响的,坦然接受我们无能为力的。
7.3软件系统的黑匣子——日志
7.3.1 日志的作用
程序中记录的日志有什么作用呢?
日志记录的是程序的运行情况,包括用户的各种操作、程序的运行状态等信息。就像飞机上的黑匣子,它记录了飞机在飞行过程中发生的情况,可以帮助我们进行分析、复盘,尤其是在飞行过程中遇到突发情况的时候,黑匣子是帮助我们找到问题根源的重要依据。而日志就是软件系统的“黑匣子”。
日志vs Debug
说到定位问题,一位名叫Debug的同学愤然起身,高声喝道:“说到定位问题,我Debug认第二,就没人敢认第一,这个叫日志的家伙是谁,有本事出来单挑!”
的确,在开发环境中,Debug称第二,没人敢称第一。但是在生产环境中,它就有点“张飞扔鸡毛——有劲儿使不上了”。什么?它还有一个“表哥”——远程Debug?如果你敢在生产环境中使用远程Debug,相信你的领导会分分钟“提刀”向你走来。
之所以在生产环境中不能使用Debug,一是因为断点会阻塞所有请求;二是因为有些偶发性问题很难复现。而日志则完美避免了这两个问题,所以日志成了定位生产环境问题的不二之选。正所谓“日志打得好,线上没烦恼”。
7.3.2 日志级别
事有轻重缓急,日志也不例外。日志可以通过划分不同的级别来输出不同的信息。表所示为日志级别及其描述。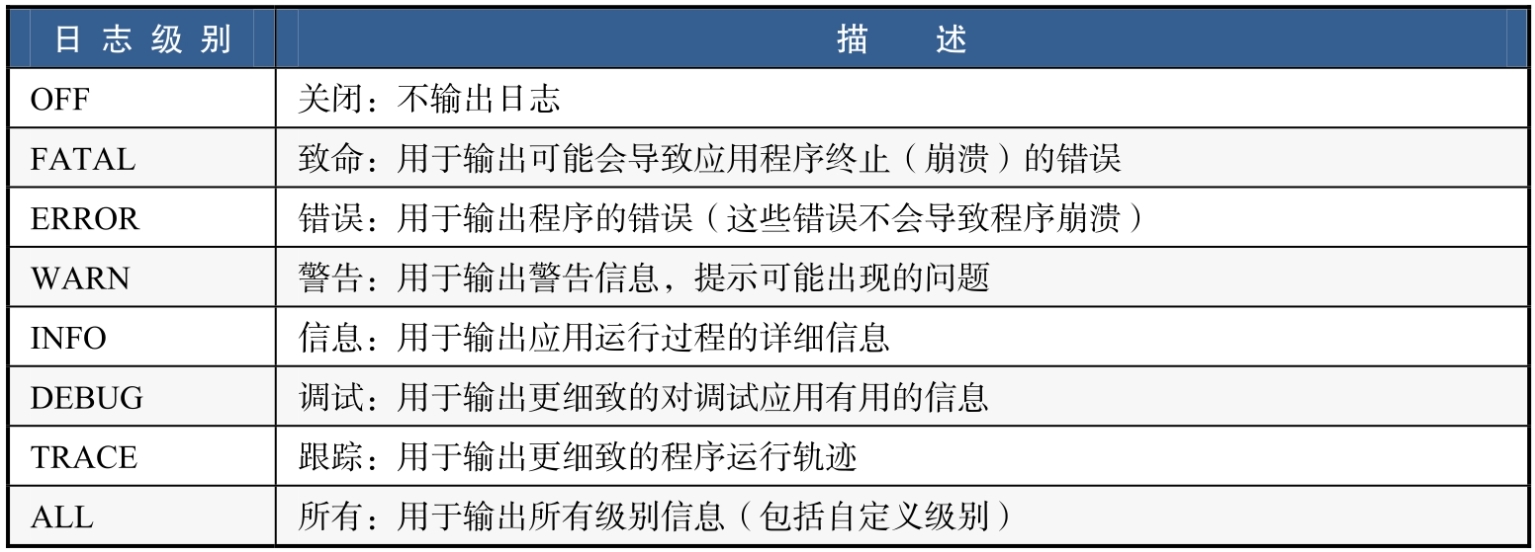
日志级别的输出规则:假如当前日志级别为INFO,则会将INFO、WARN、ERROR、FATAL级别的日志都打印出来,也就是说,会打印大于或等于当前日志级别的所有日志。
7.3.3 常见日志框架
日志框架中其实还有两个更详细的分类——日志门面和日志实现。如果你了解设计模式,那么对于“门面”这个词应该不会感到陌生,就是facade模式。如果你不了解设计模式,那么可以将日志门面理解为日志的接口框架,即对日志输出定义了一套标准,可以配合相应的日志实现框架一起使用。
日志门面
· JCL
· SLF4J
日志实现
· Log4j
· Log4j2
· Logback
· J.U.L
7.3.5 规范
7.3.6 得日志者
得天下日志所记录的程序运行的轨迹与状态,可以帮助我们很好地对程序进行分析与优化。虽然日志具有非常重要的作用,但是它一直默默无闻,容易被人忽略,以致很多人并不重视它。日志蕴含着非常宝贵的信息,所以当你重视日志,善于使用和分析日志的时候,你就超越了身边的很多人,成为一个分析问题、解决问题的高手。
7.4要点回顾
· 单元测试要无副作用、可重复运行、独立且完整· 单元测试可以帮助你节省开发成本
· 异常处理
· 日志很重要,但使用时要遵循一定的规范
第8章 Spring Boot的核心原理
8.1你真的懂IOC吗
8.1.1 实现方式
IOC的实现方式主要有两种:一种是依赖查找,另一种是依赖注入。两者的主要区别在于查找是主动行为,而注入是被动行为。依赖查找会主动寻找对象所需的依赖,同时获取依赖对象的时机也是可以自行控制的;依赖注入则会被动地等待容器为其注入依赖对象,由容器通过类型或者名称将被依赖对象注入相应的对象中。
依赖查找
依赖查找会主动获取,在需要的时候通过调用框架提供的方法来获取对象,并且在获取时需要提供相关的配置文件路径、key等信息来确定获取对象的状态。EJB就是使用依赖查找实现的控制反转。依赖查找建立在Java EE的JNDI规范之上,但随着EJB的衰落,其实现方式也慢慢无人问津。
依赖注入
依赖注入是控制反转最常见的实现方式,这在很大程度上得益于Spring在Java领域的垄断地位。在Spring中使用依赖注入可以通过如下4种方式:
· 基于接口
· 基于Set方法
· 基于构造函数
· 基于注解
由于注解方便、好用,目前几乎所有系统都使用注解的方式来完成依赖注入。实际上,我们已经对使用注解的依赖注入方式很熟悉了,在之前的小节中就已经用过N次了。首先使用@Controller、@Service、@Component等注解将类声明为Spring Bean,然后使用@Autowire注解注入依赖对象。
8.2什么是AOP
在Spring的世界里,IOC和AOP总是形影不离的,而且配合默契。
8.2.1 AOP与OOP
AOP(Aspect Oriented Programming,面向切面的程序设计)也是一种编程思想。作为P字家庭的一员,AOP经常会被拿来和OOP做对比。P家族的程序设计思想主要包含4个成员:
· OOP(Object Oriented Programming,面向对象编程)
· AOP(Aspect Oriented Programming,面向切面编程)
· POP(Process Oriented Programming,面向过程编程)
· FP(Functional Programming,函数式编程)
OOP的语言包括我们熟悉的Java、C++、C#等;AOP其实只能作为OOP的一种补充或者延伸,与其他3个成员不属于同一类,主要包括Spring、AspectJ、Jboss-AOP、AspectWerkz等实现;POP可以说是最悠久的编程方式了,最具代表性的就是C语言;FP近些年比较火热,如Python、Ruby等,其实FP已经诞生很久了,现在又“重获生机”,连Java从1.8版本以后都开始支持函数式编程(Lambda表达式)了。
8.2.2 为什么用AOP
我们来看一个小故事:小明接到一个需求,现在有一个下单的业务逻辑,需要记录一下整个下单流程消耗的时间,以便后续进行性能优化。小明思考了一下,觉得很简单,可以在下单之前记录一下开始时间,在下单完成后记录一下结束时间,然后让结束时间减去开始时间,就可以得到整个下单流程所消耗的时间了,完美!
后来,需要记录一次商品搜索需要花费的时间,于是小明按照上面的思路,在搜索逻辑中加入了记录时间的代码。再后来,又需要记录登录所需要的时间……
随着产品的迭代,系统中需要统计时间的接口越来越多。直到某一天,产品经理说:“为了让统计结果更加精确,我们需要把原来的时间单位由秒修改成毫秒,就修改一下单位,应该很简单吧,今天下班前能上线吗?”
然而小明看着自己写的几百个统计时间的接口,直接无能为力了!
我们不难发现,记录任何业务逻辑的执行时间所需要的操作都是一样的,都是记录一个开始时间和一个结束时间,然后求两个时间点的差值。对于这样有共性的逻辑,我们首先想到的就是将其封装成一个方法,然后哪里需要就在哪里调用,这是面向对象的编程思想。但仔细想想,在使用面向对象的编程方式时,虽然我们将代码进行了封装,但是貌似对原有的业务代码仍然有侵入。如果有一天需要记录日志时应该怎么办呢?还是需要修改每一个记录日志的方法。那么,如何解决代码侵入的问题呢?
AOP的诞生就是为了弥补OOP(面向对象编程)的不足。面向对象非常擅长解决纵向的业务逻辑,但是对于横向的公共操作却显得有些“力不从心”。而AOP却是这方面的“好手”。下面通过图来感受一下AOP。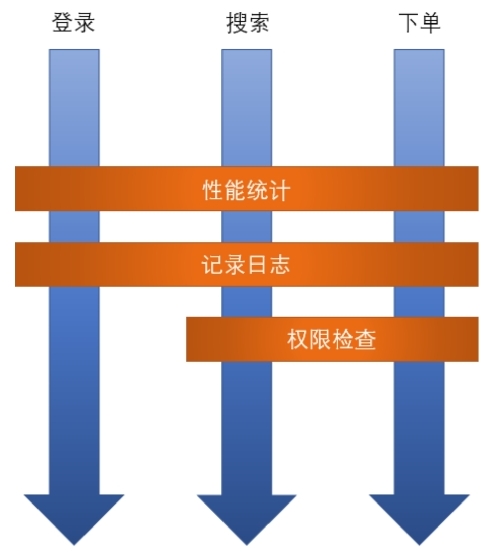
图中纵向的登录、搜索、下单都属于业务逻辑,这些是面向对象擅长的领域;横向的性能统计、记录日志、权限检查是一些系统中公共的操作,这些是AOP擅长的领域。由图可以看出,横向的AOP操作作用到纵向的业务逻辑上,就好像在业务逻辑上横着切了3刀,因此被称为面向切面编程是非常贴切的。
8.2.3 用在什么地方
AOP中的核心概念
· Adice(通知):想要让AOP做的事情,比如,上图中的性能统计
· JoinPoint(连接点):允许AOP通知的地方,比如,在方法被调用前检查权限,这个“方法被调用前”就是一个JoinPoint
· Pointcut(切入点):用于筛选JoinPoint的条件。只有符合Pointcut条件的JoinPoint才会执行Advice,上图中只有下单和搜索前才会进行权限检查
· Aspect(切面):一个包含Advice和Pointcut的集合,完整地定义了符合什么条件时做什么事。上图中的每一条横线就是一个Aspect,比如,当搜索或下单接口被调用时进行权限检查
要想知道AOP可以用在哪些场景,我们需要从AOP其中一个概念入手——Advice(通知)。我们简单回顾一下。
· Before:在目标方法执行前调用Advice
· After[finally]:在目标方法执行完成后调用Advice
· After-Returning:在目标方法成功执行后调用Advice
· After-Throwing:在目标方法抛出异常后调用Advice
· Around:一般解释为环绕/包裹目标方法调用Advice,是可定制化调用的Advice
AOP的适用场景
Before可以在目标方法执行前做一些事情,如解析请求参数、进行权限检查等;After可以在目标方法执行完成后记录一些日志;After-Returning可以与Before配合计算目标方法执行时间;After-Throwing可以在目标方法抛出异常后做一些处理;而Around基本上可以做以上所有的事情。
根据AOP的能力与特点,我们通常会在以下场景中使用AOP:
· 参数检查
· 日志记录
· 异常处理
· 性能统计
除了上面这些基础功能,还可以利用AOP做一些更加复杂的通用处理:
· 事务控制
· 缓存处理
· 权限控制
· ……
8.3为什么一个main方法就能启动项目
8.3.1 概览
8.3.2 应用启动计时
8.3.3 打印Banner
8.3.4 创建上下文实例
下面我们来到run方法中注释编号为8的位置,这里调用了一个createApplicationContext方法,该方法最终会调用ApplicationContextFactory接口。
8.3.5 构建容器上下文
下面我们来到run方法中注释编号为9的prepareContext方法中。通过方法名,我们可以猜到它是为context做上台前的准备工作的。
8.3.6 刷新上下文
run方法中注释编号为10的refreshContext方法是整个启动过程中比较核心的地方。我们熟悉的BeanFactory就是在这个阶段构建的,且所有非懒加载的Spring Bean(@Controller、@Service等)都是在这个阶段被创建的,还有Spring Boot内嵌的Web容器也是在这个时候启动的。
跟踪源码,你会发现内部调用的是ConfigurableApplicationContext.refresh方法,ConfigurableApplicationContext是一个接口,真正实现这个方法的类有3个:AbstractApplicationContext、ReactiveWebServerApplicationContext和ServletWeb ServerApplicationContext。
8.4比你更懂你的自动配置
8.5要点回顾
· IOC主要有两种实现:依赖查找和依赖注入
· IOC的意义在于屏蔽具体的实现,降低代码的耦合度
· AOP主要是为了处理横向的公共业务
· Spring Boot启动过程的核心在于refreshContext方法
· @EnableAutoConfiguration是自动配置的关键
· 按需配置依赖于众多的内置条件注解
第9章 互联网应用性能瓶颈的“万金油”——Redis
9.1初识Redis
9.2 Redis可以做什么
就像电影《蜘蛛侠》中的那句经典台词:能力越大,责任越大。Redis拥有很多优点与强大的功能,那么它一定能承担起很多责任。下面来看看Redis都能做些什么吧。
缓存
缓存是Redis的本职工作,是Redis最广泛的用途。Redis强大的性能加上优秀的缓存设计不但可以提升系统的访问速度,还能大大缓解数据库的压力。对于一些查询频率很高但修改很少的数据来说,使用Redis进行缓存再合适不过了。Redis提供了键值过期的时间设置,并且提供了灵活控制最大内存和内存溢出后的淘汰策略。一个合理的缓存设计能够为一个网站的稳定保驾护航。
排行榜
很多网站都有排行榜应用,比如,很多人每天都会关注的微博热搜榜,很多程序员关注的GitHub热度排行榜等。Redis提供的有序集合(zset)能实现各种复杂的排行榜应用。
计数器
计数器在日常生活中很常见,比如,微博的点赞数、转发量,微信文章的阅读量、在看人数,视频网站的播放量等。使用Redis的incr命令来实现这种累加功能非常合适,不但性能好,而且能从容应对高并发的请求。
社交关系
传统关系型数据库不擅长处理社交关系数据,而Redis可以很好地实现且有非常好的性能。例如,对于点赞列表、收藏列表、关注列表、粉丝列表等,使用Hash类型数据结构是一个不错的选择。
消息队列
消息队列是大型网站必用的中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis虽然和专业的消息队列相比还不够强大,但是基本可以满足一般的消息队列功能。
分布式锁
目前,几乎所有的互联网公司都用到了分布式技术,使得我们在享受新技术的同时会面对一些新的问题。分布式系统在应对同一资源并发修改的时候,不管是synchronized还是ReentrantLock都束手无策。而且直接利用数据库的锁在高并发环境下容易将数据库服务器拖垮。这时候Redis又一次“站”了出来,利用其性能优势、具有原子性的命令SETNX,或者借助Lua脚本可以实现分布式锁的功能。
9.3使用Redis
9.3.2 默认端口来历
Redis的默认端口是6379。很多人对这个端口的来历都很好奇,作者在Redis as an LRU cache一文中给出了解释,选择6379作为Redis的默认端口号,是因为MERZ(至于为什么是MERZ?你去看看作者这篇文章就知道了)这4个字母在九宫格键盘中对应的数字正好是6379。
9.4更多用法
9.4.1 Template
Spring将操作Redis的API封装成了Template。其中,使用最多的就是上面例子中的那个StringRedisTemplate,还有一个是RedisTemplate。StringRedisTemplate用于key和value都是字符串的情况,这也是我们平时使用最多的场景。字符串的好处在于简单且对人类比较友好(不需要任何转换就能看懂,不像二进制的数据那样,这一点在排查问题的时候尤为突出),而RedisTemplate则是一个相对通用的API,不仅可以处理字符串,还可以处理自定义对象等复杂类型。RedisTemplate默认采用JDK的序列化方式来转换对象,当然,我们还可以根据需要自定义序列化的方式。
Redis允许key和value为任意二进制形式,但最好还是使用字符串作为key-value的形式,因为这样容易让用户通过Redis客户端查看和管理(便于排查问题)。JSON方式也是一种不错的方式,可以将value序列化成JSON字符串。
9.5 Redis实现分布式锁
9.5.1 锁的自我修养
一个演员要有演员的自我修养,同样地,一把锁也要有锁的自我修养。下面我们来看一下,一把合格的锁应该具备哪些性质。
· 互斥:锁具有独占性,一把锁在同一时刻最多只能有一个持有者
· 安全:安全指的是解锁时的安全性,即只能解锁自己持有的锁
· 不死锁:不能因为意外的发生,导致锁不能被正常释放
9.5.2 实现分布式锁的方式
我们都知道,Java提供了锁相关的API(如synchronized、ReentrantLock等)。这些锁存在一定的局限性,在多线程(同一个JVM)的情况下可以从容应对,但是在多进程(不同JVM)的情况下,就有些无能为力了。
现在的业务场景早已不是一个单体应用就能满足的时候了,随随便便就需要一个集群加上分布式,再复杂一点的还需要异构平台的交互。既然传统的锁不能满足分布式应用的场景,聪明的程序员们就研究出了一个新锁——分布式锁。
目前,市面上对于分布式锁的实现方式主要有以下3种:
· 数据库(这种方式很少用了)
· Redis
· ZooKeeper(Chubby,来自谷歌)
在以上3种方案中,基于数据库的实现方案已经很少被应用在实际项目中了。原因很简单,性能是它最大的障碍。Redis和ZooKeeper这两种方案目前应用得比较广泛。
实现原理
不管哪种实现方案,其原理都差不多,只是所依赖的具体技术不同而已。3种方案都是基于对应技术的两个特性实现的分布式锁:
一是操作的原子性;
二是资源的唯一性。
数据库方式:乐观锁/悲观锁+唯一约束。
Redis方式:SETNX。
ZooKeeper方式:临时顺序节点。
9.6要点回顾
· Redis之所以快,根本原因是基于内存
· Redis除了做缓存,还可以做排行榜、社交关系、队列等
· Spring Boot通过RedisTemplate来访问Redis
· Spring Boot通过RedisTemplate的opsFor方法来操作Redis的各种数据类型
· 对于一把锁,最重要的是互斥、安全及不死锁
· Redis分布式锁的难点在于只释放自己的锁,以及防止过期后其他人获得自己正在使用的锁
第10章 安全领域的“扛把子”——Spring Security
身份认证与权限控制是一个企业级应用业务的“基石”。通常越复杂的系统对认证和授权的要求越高。
10.1认证和授权
10.2 Spring Security简介
10.3功能一览
10.3.1 多种认证方式
· HTTP Basic
· HTTP Form
· HTTP Digest
· LDAP· OpenID
· CAS· ACL
· OAuth 2
· SAML
· JAAS
· ……
从最基本的HTTP Basic到常用的HTTP Form,再到LDAP、OpenID及OAuth等,可以说Spring Security几乎支持市面上所有主要的认证方式。
如果你对Spring Security内置的这些认证方式都不满意,那么也没有关系,Spring Security还支持自定义认证,最大化地满足你的个性化需求。
10.3.2 多种加密方式
密码安全是系统安全的重中之重。互联网发展至今,密码泄露的事件屡见不鲜。2011年国内的一个知名IT网站就发生了一起数据泄露事件,更可怕的是,用户密码都是采用明文存储的,导致数百万用户无异于在网上“裸奔”,再加上很多人为了便于记忆,会把各种账号的密码都设置为一样的,造成“一号泄露,众号沦陷”的局面。
Spring官方推荐使用BcryptPasswordEncoder来进行密码加密
10.3.3 多种授权方式
多种认证方式加上丰富的加密策略,让Spring Security有了强大的认证功能及密码安全性。同时,Spring Security还提供了非常丰富的授权方式:
· 通过配置方式,按角色或权限资源进行访问控制
· 通过注解方式,按角色、权限资源或方法进行访问控制
· Spring EL表达式配置权限
· RBAC动态权限控制
· 指定IP进行访问控制
10.4动手实践
10.5前景
10.6要点回顾
· 认证用来核实你是谁,授权用来确定你被允许做什么
· Spring Security支持HTTP Basic、HTTP Form、LDAP、OpenID、CAS、ACL、OAuth 2、SAML、JAAS等多种认证方式
· Spring Security支持Bcrypt、LDAP-SHA、MessageDigest、PBKDF2、Scrypt、Argon2等加密方式
· Spring Security可以通过配置、注解方式来配置权限,支持Spring EL表达式、RBAC等多种权限配置方式
· 我们通过多个实例学习了Spring Security的认证、授权、异常处理(认证、鉴权)、“记住我”等实用功能
第11章 自律到“令人发指”的定时任务
11.1什么时候需要定时任务
11.2 Java中的定时任务
11.2.1 单机
Timer:来自JDK,从JDK 1.3开始引入。JDK自带,不需要引入外部依赖,简单易用,但是功能相对单一。
ScheduledExecutorService:同样来自JDK,比Timer晚一些,从JDK 1.5开始引入,它的引入弥补了Timer的一些缺陷。
Spring Task:来自Spring,Spring环境中单机定时任务的不二之选。
11.2.2 分布式
Quartz:分布式定时任务的基石,功能丰富且强大,既能与简单的单体应用结合,又能支撑起复杂的分布式系统。
ElasticJob:来自当当网,最开始是基于Quartz开发的,后来改用ZooKeeper来实现分布式协调。它具有完整的定时任务处理流程,很多国内公司都在使用(目前登记在册的有80多家),并且支持云开发。
XXL-JOB:来自大众点评,同样是基于Quartz开发的,后来改用自研的调度组件。它是一个轻量级的分布式任务调度平台,简单易用,很多国内公司都在使用(目前登记在册的有400多家)。
PowerJob:号称“全新一代分布式调度与计算框架”,采用无锁化设计,支持多种报警通知方式(如WebHook、邮件、钉钉及自定义)。它比较重量级,适合做公司公共的任务调度中间件。
11.3 Spring Task实战
11.4整合Quartz
11.4.1 核心概念
· Job:任务的核心逻辑
· JobDetail:对Job进一步封装,完成一些属性设置
· Trigger:触发器,主要用来指定Job的触发规则
· Scheduler:调度器,用来维护Job的生命周期(创建、删除、暂停、调度等)
11.5 cron表达式
cron模式是定时任务中最常用的触发策略,可以应对更多的情况。
11.6要点回顾
· 定时任务适合处理在指定的时间内,按照指定的频率或次数处理的需求
· 定时任务有单机和分布式之分:单机的定时任务推荐使用Spring Task;分布式的定时任务方案很多,可根据需要选择
· fixedDelay、cron和fixedRate三种调度策略对超时任务的处理略有不同
· Quartz的核心概念:Job、JobDetail、Trigger和Scheduler
· cron是最常用的触发策略,但不需要我们刻意记忆,只需要我们能通过图形化工具生成cron表达式即可
第12章 RabbitMQ从哪里来、是什么、能干什么、怎么干
12.1消息队列的由来
12.2核心概念
RabbitMQ架构模型总体可以分为客户端和服务端两部分。客户端包括生产者和消费者;服务端包括虚拟主机、交换器及队列。两者通过连接和信道进行通信。
整体的流程很简单:生产者(Producer)将消息发送到服务端(Broker),消费者(Consumer)从服务端获取对应的消息。当然,生产者在发送消息前需要先确定发送给哪个虚拟主机(Virtual Host)的哪个交换器(Exchange),再由交换器通过路由键(Routing Key)将消息转发给与之绑定(Binding)的队列(Queue)。最后,消费者到指定的队列中获取自己的消息进行消费。
12.2.1 客户端
上图中两侧的生产者和消费者都属于客户端,是需要我们用代码实现具体逻辑的部分。
生产者
生产者是消息的发送方,将要发送的信息封装成一定的格式,发送给服务端。消息通常包括消息体(payload)和标签(label)。
消费者
消费者是消息的接收方,负责消费消息体。
12.2.2 服务端
上图的中部表示RabbitMQ的服务端,这部分是我们部署的RabbitMQ服务,可以是单机也可以是集群。
虚拟主机
虚拟主机用来对交换器和队列进行逻辑隔离。在同一个虚拟主机下,交换器和队列的名称不能重复。这一点类似于Java中的package,在同一个package下,不能出现相同名称的类或接口。
交换器
交换器负责接收生产者发来的消息,并根据规则分配给对应的队列。它不生产消息,只是消息的搬运工。
队列
队列负责存储消息。生产者发送的消息会被存放到这里,而消费者从这里获取消息。
12.3业务场景
消息队列适用于哪些业务场景呢?这就要从消息队列的功能说起了。消息队列的主要功能有以下3种。
第一,消息队列天生具备异步处理的功能。
第二,消息队列可以作为系统之间的沟通桥梁,且不受系统技术栈约束。
第三,队列的特性可以给高并发的业务提供缓冲。
异步处理
有些业务由N个子业务组成,而且有些是核心子业务,有些是非核心子业务。比如,“提交订单”可能涉及创建订单、扣减库存、增加用户积分、发送订单邮件等。显然,创建订单和扣减库存是核心子业务,所以,没必要等待发送订单邮件后再告诉用户订单提交成功,更没有必要因为邮件发送失败而通知用户订单提交失败。那么,发送订单邮件和增加用户积分这样的操作就可以交给消息队列去异步执行。
总的来说,异步是为了尽快返回,提升用户体验。
系统解耦
仍然以电商业务为例,用户在购买一件商品时,需要多个系统互相配合才能完成,如订单系统、支付系统、积分系统、库存系统、客服系统等。这些系统之间既需要紧密的配合,又需要各自保持独立。这样才能让系统既稳定,又能应对快速发展的业务需要。这就需要各个系统既要灵活多变,又要在变化的同时不影响其他系统,甚至用户更换了实现语言也互不影响。而消息队列恰好可以满足这些需求,充当系统之间通信的桥梁。
缓冲削峰
经历过春节抢火车票的读者应该都有感触,12306网站的排队抢票就是一个很适合使用消息队列的场景。在火车票开卖的瞬间,系统中瞬间涌入海量请求,如果将这些请求一股脑地发送到业务服务器上,那么再厉害的架构,再高端的服务器也“扛”不住。消息队列可以组织这些请求有序排队,然后由业务系统按顺序处理。自从12306有了排队功能,就很少出现系统崩溃的情况了。
12.4工作模式
RabbitMQ支持7种工作模式:
· 简单模式
· 工作队列模式
· 广播模式
· 路由模式
· 动态路由模式
· 远程模式
· 生产者确认模式
12.5动手实践
12.6要点回顾
· 消息队列起源于金融行业
· 消息队列的核心概念包括生产者、消费者、连接、信道、虚拟主机、交换器、队列
· 消息队列擅长的业务场景包括异步处理、系统解耦、缓冲削峰
· RabbitMQ有7种工作模式:简单模式、工作队列模式、广播模式、路由模式、动态路由模式、远程模式、生产者确认模式
第13章 反其道行之的Elasticsearch
13.1 Elasticsearch简介
13.1.1 什么是搜索引擎
我们对搜索引擎都有一定的了解,但你可能不知道搜索引擎还有以下几种分类:
· 目录搜索引擎
· 全文搜索引擎
· 元搜索引擎
· 垂直搜索引擎目
录搜索引擎:算不上真正的搜索引擎。由人工采集、整理分类的信息网站,以及早期那些门户网站属于这一类。
全文搜索引擎:目前应用最广泛的搜索引擎,通过网络爬虫、自然语言处理(NLP)及大数据分析形成自己庞大的数据库。百度、谷歌、必应等属于这一类。
元搜索引擎:简单来讲,就是一种聚合多个全文搜索引擎的工具。它可以先把关键词发送给多个搜索引擎,然后把各个搜索引擎的搜索结果组合在一起。元搜索引擎并不生产搜索结果,它只是搜索结果的搬运工。
垂直搜索引擎:属于全文搜索引擎的一个细分类型,是某个特定业务领域的全文搜索引擎。
本章开篇提到的淘宝、微博、bilibili等都属于这一类。我们通常使用的是垂直搜索引擎。
13.2核心概念
13.3动手实践
13.4数据同步
在通常情况下,Elasticsearch不负责生产数据,一般都会先将数据同步到Elasticsearch,然后由Elasticsearch完成搜索。开发人员涉及最多的场景就是将数据库的数据同步到Elasticsearch。同步可以分为两种类型:一种是全量同步;另一种是增量同步。全量同步通常只会进行一次,是在初始同步时进行的。之后,数据库发生增加、删除、修改的操作时,只会将变化同步过去,这就是增量同步了。
增量同步可以采用定时同步或实时同步的方案来实现。
13.5要点回顾
· 搜索引擎分为目录搜索引擎、全文搜索引擎、元搜索引擎、垂直搜索引擎
· Elasticsearch核心对象包括Index、Type、Document、Field、Mapping
· Elasticsearch适合做搜索引擎的原因在于倒排索引
· Spring Boot提供了两种访问Elasticsearch的方式,即ElasticsearchRepository和ElasticsearchRestTemplate
· 将MySQL数据同步到Elasticsearch通常有两种方案,即定时同步和实时同步。
第14章 项目上线的“最后一公里”——部署与监控
14.1部署
14.2监控
我们在前面学习了Spring Boot应用的部署方式。那么,当应用被部署到生产环境以后,我们如何随时掌握它的运行状态呢?这时就该Actuator出场了,有了它,我们就像长了“顺风耳”“千里眼”。它可以将应用的一举一动通过网线瞬间呈现给我们,让我们可以“运筹帷幄之中,决胜千里之外”。
14.2.1 Actuator
Actuator是一个制造术语,指的是移动或控制某物体的机械装置。这种装置可以非常精准地展示每一个细微的变化。
这也是Spring对Actuator的期望。Actuator是Spring Boot的附加功能,可以帮助我们监控和管理应用,并且支持使用HTTP端点或JMX来管理和监视应用程序。
14.3要点回顾
· Spring Boot支持两种部署方式,即Jar和War
· DevTools可以让项目在修改后自动重启,从而节省一些时间
· Spring Boot为我们提供了强大的监控组件Actuator
· Spring Boot Admin可以将Actuator的监控指标通过图形化的方式更直观地呈现出来
第15章 你学习技术的“姿势”对吗
15.1技术应该怎么学
“姿势不对,啥也白费。”下面我们来看一下,我多年来一直在用,并且效果还不错的一套学习技术的方法论。其实说起来非常简单,就4个字:看、用、想、写。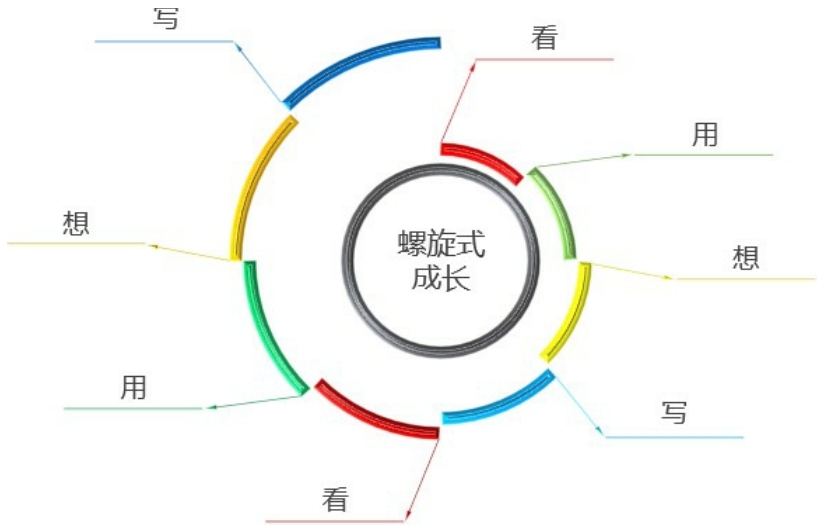
15.2不怕麻烦
15.3遇到问题怎么办
15.4要点回顾
· 技术的学习离不开看、用、想、写,并且需要长期坚持
· “不怕麻烦”是成功的前提
· 别人可以帮助你解决问题,但不能代替你解决问题
附录:使用 Docker 配置开发环境
Docker 常用命令
镜像操作
1 | # 搜索镜像 |
容器操作
1 | # 创建并运行容器 |
安装环境
安装 MySQL
1 | # 拉取镜像 |
安装 Redis
1 | # 拉取镜像 |
安装 RabbitMQ
1 | # 拉取镜像 |
安装 Elasticsearch
1 | # 拉取镜像 |
安装 ik 分词器
1 | # 进入容器 |
解决中文乱码
1 | # 创建 ~/.vimrc 文件 |
参考文献或转载相关:
原文链接:https://blog.csdn.net/m0_73311735/article/details/129299339